Lucene学习笔记(一)
来源:互联网 发布:2017年9月非农数据 编辑:程序博客网 时间:2024/05/04 14:07
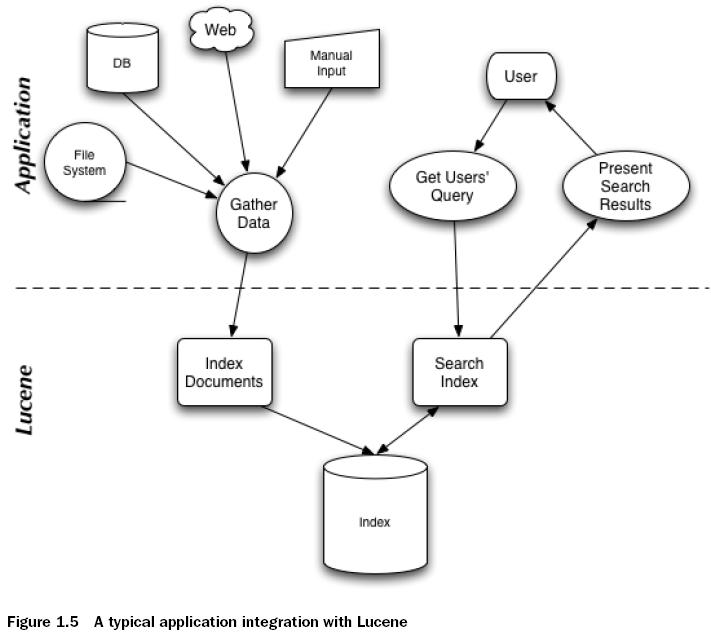
建立索引:
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
public class Indexer
{
//建立索引
/**
* @param args
*/
public static void main(String[] args) throws Exception
{
// TODO Auto-generated method stub
if (args.length != 2)
{
throw new Exception("Usage: java" + Indexer.class.getName()+ "<index dir> <data dir>");
}
File indexDir = new File(args[0]);//存放索引的路径
File dataDir = new File(args[1]); //要建立索引的目录路径
long start = new Date().getTime();
int numIndexed = index(indexDir, dataDir); //建立索引
long end = new Date().getTime();
System.out.println("Indexing " + numIndexed + " files took " + (end - start) + " milliseconds");
}
private static int index(File indexDir, File dataDir) throws IOException
{
if (!dataDir.exists() || !dataDir.isDirectory())
{
throw new IOException(dataDir+ " does not exist or is not a directory");
}
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(), true);
writer.setUseCompoundFile(false);
indexDirectory(writer, dataDir);
int numIndexed = writer.docCount();
writer.optimize();
writer.close();
return numIndexed;
}
private static void indexDirectory(IndexWriter writer, File dataDir) throws IOException
{
// TODO Auto-generated method stub
File[] files = dataDir.listFiles();
for (int i = 0; i < files.length; i++)
{
File f = files[i];
if (f.isDirectory())
{
indexDirectory(writer, f);
}
else if (f.getName().endsWith(".txt"))
{
indexFile(writer, f);
}
}
}
private static void indexFile(IndexWriter writer, File f) throws IOException
{
if (f.isHidden() || !f.exists() || !f.canRead())
{
return;
}
System.out.println("Indexing " + f.getCanonicalPath());
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f)));
doc.add(new Field("filename", f.getCanonicalPath(), Field.Store.YES, Field.Index.TOKENIZED));
writer.addDocument(doc);
}
}
import java.io.FileReader;
import java.io.IOException;
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.index.IndexWriter;
public class Indexer
{
//建立索引
/**
* @param args
*/
public static void main(String[] args) throws Exception
{
// TODO Auto-generated method stub
if (args.length != 2)
{
throw new Exception("Usage: java" + Indexer.class.getName()+ "<index dir> <data dir>");
}
File indexDir = new File(args[0]);//存放索引的路径
File dataDir = new File(args[1]); //要建立索引的目录路径
long start = new Date().getTime();
int numIndexed = index(indexDir, dataDir); //建立索引
long end = new Date().getTime();
System.out.println("Indexing " + numIndexed + " files took " + (end - start) + " milliseconds");
}
private static int index(File indexDir, File dataDir) throws IOException
{
if (!dataDir.exists() || !dataDir.isDirectory())
{
throw new IOException(dataDir+ " does not exist or is not a directory");
}
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(), true);
writer.setUseCompoundFile(false);
indexDirectory(writer, dataDir);
int numIndexed = writer.docCount();
writer.optimize();
writer.close();
return numIndexed;
}
private static void indexDirectory(IndexWriter writer, File dataDir) throws IOException
{
// TODO Auto-generated method stub
File[] files = dataDir.listFiles();
for (int i = 0; i < files.length; i++)
{
File f = files[i];
if (f.isDirectory())
{
indexDirectory(writer, f);
}
else if (f.getName().endsWith(".txt"))
{
indexFile(writer, f);
}
}
}
private static void indexFile(IndexWriter writer, File f) throws IOException
{
if (f.isHidden() || !f.exists() || !f.canRead())
{
return;
}
System.out.println("Indexing " + f.getCanonicalPath());
Document doc = new Document();
doc.add(new Field("contents", new FileReader(f)));
doc.add(new Field("filename", f.getCanonicalPath(), Field.Store.YES, Field.Index.TOKENIZED));
writer.addDocument(doc);
}
}
搜索:
import java.io.File;
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Searcher
{
/**
* @param args
*/
public static void main(String[] args) throws Exception
{
if (args.length != 2)
{
throw new Exception("Usage: java " + Searcher.class.getName()+ " <index dir> <auery>");
}
File indexDir = new File(args[0]);//要搜索的索引所在目录
String q = args[1]; //搜索关键字
if (!indexDir.exists() || !indexDir.isDirectory())
{
throw new Exception(indexDir + " does not exist or is not a directory.");
}
search(indexDir, q);
}
private static void search(File indexDir, String q) throws Exception
{
Directory fsDir = FSDirectory.getDirectory(indexDir, false);
IndexSearcher is = new IndexSearcher(fsDir);// 打开索引
QueryParser parser = new QueryParser("contents", new StandardAnalyzer());
Query query = parser.parse(q); //对文本内容进行分析查询
long start = new Date().getTime();
Hits hits = is.search(query); //搜索索引
long end = new Date().getTime();
System.err.println("Found " + hits.length() + " document(s) (in " + (end - start) + " milliseconds) that matched query '" + q + "’:");
for (int i = 0; i < hits.length(); i++)
{
Document doc = hits.doc(i); //得到匹配的文档
System.out.println(doc.get("filename"));
}
}
}
import java.util.Date;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Searcher
{
/**
* @param args
*/
public static void main(String[] args) throws Exception
{
if (args.length != 2)
{
throw new Exception("Usage: java " + Searcher.class.getName()+ " <index dir> <auery>");
}
File indexDir = new File(args[0]);//要搜索的索引所在目录
String q = args[1]; //搜索关键字
if (!indexDir.exists() || !indexDir.isDirectory())
{
throw new Exception(indexDir + " does not exist or is not a directory.");
}
search(indexDir, q);
}
private static void search(File indexDir, String q) throws Exception
{
Directory fsDir = FSDirectory.getDirectory(indexDir, false);
IndexSearcher is = new IndexSearcher(fsDir);// 打开索引
QueryParser parser = new QueryParser("contents", new StandardAnalyzer());
Query query = parser.parse(q); //对文本内容进行分析查询
long start = new Date().getTime();
Hits hits = is.search(query); //搜索索引
long end = new Date().getTime();
System.err.println("Found " + hits.length() + " document(s) (in " + (end - start) + " milliseconds) that matched query '" + q + "’:");
for (int i = 0; i < hits.length(); i++)
{
Document doc = hits.doc(i); //得到匹配的文档
System.out.println(doc.get("filename"));
}
}
}
重点学习的几个方面:
1, Lucene的索引结构,
2, 各种异构数据源的解析器(Parser)
3, 分词器(Analyzer)提取索引项(尤其是如何进行中文分词)
注:这里使用的是lucene2.2.0
- Lucene学习笔记(一)-------Lucene基础
- Lucene学习笔记(一)
- lucene学习笔记(一)
- Lucene学习笔记(一)
- Lucene学习笔记 (一)
- Lucene学习笔记(一)
- Lucene学习笔记一
- lucene学习笔记一
- lucene学习笔记(一)
- Lucene学习笔记一
- Lucene学习笔记一
- lucene学习笔记(一)
- Lucene全文检索学习笔记(一):lucene的应用
- Lucene+Heritrix学习笔记系列(一)
- Lucene/Solr学习笔记(一)
- Lucene全文搜索学习笔记(一)
- lucene学习笔记(一)简介
- 【转载】Lucene学习笔记(一)
- OpenGL入门笔记(十六)
- OpenGL入门笔记(十五)
- OpenGL入门笔记(十四)
- OpenGL入门笔记(十三)
- 【转】Lucene倒排索引原理
- Lucene学习笔记(一)
- OpenGL中的汉字显示
- OpenGL入门笔记(十二)
- C语言的变参函数设计
- OpenGL的显示列表
- OpenGL选择机制的一点讨论
- 代码分析
- 用Soap消息调用Web Services(续)
- 【转】用JDOM建立XML文件


