Ext2索引节点对象的创建
来源:互联网 发布:小米手机移动网络设置 编辑:程序博客网 时间:2024/04/30 01:29
1.2.3 Ext2索引节点对象的创建
现在还是从一个普通文件的角度来分析上面的过程,比如说,当我门在根目录下调用fd = open("file", O_CREAT)打开(创建)一个文件时,会启动do_sys_open系统调用,并根据路径“file”去触发do_filp_open函数返回一个file结构。do_filp_open主要调用的两个函数(详细的过程请参考博客“VFS系统调用的实现”
http://blog.csdn.net/yunsongice/archive/2010/06/22/5685130.aspx):
(1)open_namei():填充目标文件所在目录(也就是根目录)的dentry结构和所在文件系统的vfsmount结构,并将信息保存在nameidata结构中。在dentry结构中dentry->d_inode就指向目标文件的索引节点。
(2)dentry_open():建立目标文件的一个“上下文”,即file数据结构,并让它与当前进程的task_strrct结构挂上钩。同时,在这个函数中,调用了具体文件系统的打开函数,即f_op->open(),也就是前面看到的generic_file_open,,该函数返回指向新建立的file结构的指针。
注意,如果在访问模式标志中设置了O_CREAT,比如我们这里,则以LOOKUP_PARENT、LOOKUP_OPEN和LOOKUP_CREATE标志的设置开始查找操作。一旦path_lookup()函数成功返回,则检查请求的文件是否已存在。如果不存在,则open_namei会调用父索引节点的create方法分配一个新的磁盘索引节点。这里父索引节点是一个目录的,所以其i_op方法不是上面提到的ext2_file_inode_operations,而是ext2_dir_inode_operations,来自fs/ext2/namei.c:
const struct inode_operations ext2_dir_inode_operations = {
.create = ext2_create,
.lookup = ext2_lookup,
.link = ext2_link,
.unlink = ext2_unlink,
.symlink = ext2_symlink,
.mkdir = ext2_mkdir,
.rmdir = ext2_rmdir,
.mknod = ext2_mknod,
.rename = ext2_rename,
#ifdef CONFIG_EXT2_FS_XATTR
.setxattr = generic_setxattr,
.getxattr = generic_getxattr,
.listxattr = ext2_listxattr,
.removexattr = generic_removexattr,
#endif
.setattr = ext2_setattr,
.check_acl = ext2_check_acl,
};
ext2_create函数定义在同一个文件中,传给它的参数是根目录的inode,:
static int ext2_create (struct inode * dir, struct dentry * dentry, int mode, struct nameidata *nd)
{
struct inode *inode;
dquot_initialize(dir);
inode = ext2_new_inode(dir, mode);
if (IS_ERR(inode))
return PTR_ERR(inode);
inode->i_op = &ext2_file_inode_operations;
if (ext2_use_xip(inode->i_sb)) {
inode->i_mapping->a_ops = &ext2_aops_xip;
inode->i_fop = &ext2_xip_file_operations;
} else if (test_opt(inode->i_sb, NOBH)) {
inode->i_mapping->a_ops = &ext2_nobh_aops;
inode->i_fop = &ext2_file_operations;
} else {
inode->i_mapping->a_ops = &ext2_aops;
inode->i_fop = &ext2_file_operations;
}
mark_inode_dirty(inode);
return ext2_add_nondir(dentry, inode);
}
这里面最重要的是ext2_new_inode()函数,用于在父目录dir下创建Ext2磁盘的索引节点,返回相应的索引节点对象的地址(或失败时为NULL)。该函数谨慎地选择存放该新索引节点的块组;它将无联系的目录散放在不同的组,而且同时把文件存放在父目录的同一组。为了平衡普通文件数与块组中的目录数,Ext2为每一个块组引入“债(debt) ”参数。
ext2_new_inode函数有两个参数:dir,所创建索引节点父目录对应的索引节点对象的地址,新创建的索引节点必须插入到这个目录中,成为其中的一个目录项;mode,要创建的索引节点的类型。后一个参数还包含一个MS_SYNCHRONOUS标志,该标志请求当前进程一直挂起,直到索引节点被分配成功或失败。该函数代码时分复杂,详细的分析内容请参考博客“Ext2索引节点分配” http://blog.csdn.net/yunsongice/archive/2010/08/18/5822472.aspx,这里仅仅概要地讲解一下分配步骤。
ext2_new_inode函数首先调用new_inode()通过sb->s_op->alloc_inode函数分配一个新的VFS索引节点对象,并把它的i_sb字段初始化为存放在dir->i_sb中的超级块地址,然后把它追加到正在用的索引节点链表与超级块链表中。
前面看到,superblock的s_op->alloc_inode函数地址为ext2_alloc_inode,该函数来自fs/ext2/super.c:
static struct inode *ext2_alloc_inode(struct super_block *sb)
{
struct ext2_inode_info *ei;
ei = (struct ext2_inode_info *)kmem_cache_alloc(ext2_inode_cachep, GFP_KERNEL);
if (!ei)
return NULL;
ei->i_block_alloc_info = NULL;
ei->vfs_inode.i_version = 1;
return &ei->vfs_inode;
}
很简单,通过ext2_inode_cachep的slab分配器分配一个磁盘索引节点描述符ext2_inode_info而作为VFS的inode结构作为嵌入其内部的vfs_inode字段被返回。注意,VFS的inode对象是嵌入在ext2_inode_info描述符中的,当执行了ext2_alloc_inode函数以后,new_inode()函数内部就会有一个未初始化的inode结构。随后,new_inode()函数将这个inode分别插入到以inode_in_use和sb->s_inodes为首的循环链表中。
因为inode分别嵌入到ext2_inode_info结构中的,所以内核提供EXT2_I宏来获得已分配inode的ext2_inode_info结构:
static inline struct ext2_inode_info *EXT2_I(struct inode *inode)
{
return container_of(inode, struct ext2_inode_info, vfs_inode);
}
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );})
struct ext2_inode_info *ei = EXT2_I(inode);
那么super_block和ext2_sb_info的关系是不是这样的呢?上一节我们看到,磁盘中的ext2_super_block结构总是被页高速缓存到内存中,由ext2_sb_info结构的s_es字段指向,所以内核提供的EXT2_SB宏就能直接得到ext2_sb_info数据结构位于内存的地址。
static inline struct ext2_sb_info *EXT2_SB(struct super_block *sb)
{
return sb->s_fs_info;
}
struct ext2_sb_info *sbi = EXT2_SB(sb);
struct ext2_super_block *es = sbi->s_es;
因此,ext2_new_inode函数内部,与分配的inode相关的磁盘索引节点映像ext2_inode_info、磁盘超级快映像ext2_sb_info和磁盘超级快对象ext2_super_block分别由内部变量ei、sbi和es指向。
随后如果新的索引节点是一个目录,函数就调用find_group_orlov(sb, dir)为目录找到一个合适的块组(安装ext2时,如果带一个参数OLDALLOC,则会强制内核使用一种简单、老式的方式分配块组:find_group_dir(sb, dir))。
如果新索引节点不是个目录,则调用find_group_other(sb, dir),在有空闲索引节点的块组中给它分配一个。该函数从包含父目录的块组开始往下找。具体逻辑如下:
a. 从包含父目录dir的块组开始,执行快速的对数查找。这种算法要查找log(n)个块组,这里n是块组总数。该算法一直向前查找直到找到一个可用的块组,具体如下:如果我们把开始的块组称为i,那么,该算法要查找的块组号为i mod (n),i+1 mod (n),i+1+2 mod (n),i+1+2+4 mod (n),等等。大家是不是觉得这个东西是不是似曾相识呀,不错,就是伙伴系统算法的思想。
b. 如果该算法没有找到含有空闲索引节点的块组,就从包含父目录dir的块组开始执行彻底的线性查找,总能找到一个含有空闲索引节点的块组,除非磁盘满了。
find_group_other函数将要分配磁盘索引节点的块组号group,回到ext2_new_inode函数中,下一步要做的事是设置位图。于是调用read_inode_bitmap()得到所选块组的索引节点位图,并从中寻找第一个空闲位,这样就得到了第一个空闲磁盘索引节点号:
static struct buffer_head *
read_inode_bitmap(struct super_block * sb, unsigned long block_group)
{
struct ext2_group_desc *desc;
struct buffer_head *bh = NULL;
desc = ext2_get_group_desc(sb, block_group, NULL);
if (!desc)
goto error_out;
bh = sb_bread(sb, le32_to_cpu(desc->bg_inode_bitmap));
if (!bh)
ext2_error(sb, "read_inode_bitmap",
"Cannot read inode bitmap - "
"block_group = %lu, inode_bitmap = %u",
block_group, le32_to_cpu(desc->bg_inode_bitmap));
error_out:
return bh;
}
我们看到,read_inode_bitmap函数接收超级块和刚刚我们得到的组号作为参数,通过ext2_get_group_desc函数获得超级快的块组描述符结构:
struct ext2_group_desc * ext2_get_group_desc(struct super_block * sb,
unsigned int block_group,
struct buffer_head ** bh)
{
unsigned long group_desc;
unsigned long offset;
struct ext2_group_desc * desc;
struct ext2_sb_info *sbi = EXT2_SB(sb);
if (block_group >= sbi->s_groups_count) {
ext2_error (sb, "ext2_get_group_desc",
"block_group >= groups_count - "
"block_group = %d, groups_count = %lu",
block_group, sbi->s_groups_count);
return NULL;
}
group_desc = block_group >> EXT2_DESC_PER_BLOCK_BITS(sb);
offset = block_group & (EXT2_DESC_PER_BLOCK(sb) - 1);
if (!sbi->s_group_desc[group_desc]) {
ext2_error (sb, "ext2_get_group_desc",
"Group descriptor not loaded - "
"block_group = %d, group_desc = %lu, desc = %lu",
block_group, group_desc, offset);
return NULL;
}
desc = (struct ext2_group_desc *) sbi->s_group_desc[group_desc]->b_data;
if (bh)
*bh = sbi->s_group_desc[group_desc];
return desc + offset;
}
看前面那个图,Ext2层对超级块对象总是缓存的,整个磁盘的所有ext2_group_desc 都存放在其s_group_desc数组字段对应的buffer_head对应的磁盘高速缓存中,即同样缓存在同一个页面中的,这个函数直接返回块中对应offset的ext2_group_desc就行了,有缓存,很简单!
得到了ext2_group_desc之后,read_inode_bitmap函数将其索引节点位图地址对应的那个块缓存到页高速缓存中,最后将该高速缓存描述符buffer_head返回。
接下来ext2_new_inode函数要做的事,是分配磁盘索引节点ext2_inode_info:把索引节点位图中的相应位置位,并把含有这个位图的页高速缓存标记为脏。此外,如果文件系统安装时指定了MS_SYNCHRONOUS标志,则调用sync_dirty_buffer(bitmap_bh)开始I/O写操作并等待,直到写操作终止。
初始化这个ext2_inode_info的字段。特别是,设置嵌入在其内部的inode的索引节点号i_no,并把xtime.tv_sec的值拷贝到i_atime、i_mtime及i_ctime。把这个块组的索引赋给ext2_inode_info结构的i_block_group字段;初始化这个ext2_inode_info的访问控制列表(ACL);将新索引节点inode对象插入散列表inode_hashtable(insert_inode_hash(inode),调用mark_inode_dirty()把该索引节点的磁盘索引节点对象移进超级块脏索引节点链表;调用ext2_preread_inode()从磁盘读入包含该索引节点的块,将它存入页高速缓存。千万要注意,这里可不是文件预读,而是对磁盘索引节点进行缓存。进行这种所谓的“预读”是因为最近创建的索引节点可能马上会被读写:
static void ext2_preread_inode(struct inode *inode)
{
unsigned long block_group;
unsigned long offset;
unsigned long block;
struct buffer_head *bh;
struct ext2_group_desc * gdp;
struct backing_dev_info *bdi;
bdi = inode->i_mapping->backing_dev_info;
if (bdi_read_congested(bdi))
return;
if (bdi_write_congested(bdi))
return;
block_group = (inode->i_ino - 1) / EXT2_INODES_PER_GROUP(inode->i_sb);
gdp = ext2_get_group_desc(inode->i_sb, block_group, &bh);
if (gdp == NULL)
return;
/*
* Figure out the offset within the block group inode table
*/
offset = ((inode->i_ino - 1) % EXT2_INODES_PER_GROUP(inode->i_sb)) *
EXT2_INODE_SIZE(inode->i_sb);
block = le32_to_cpu(gdp->bg_inode_table) +
(offset >> EXT2_BLOCK_SIZE_BITS(inode->i_sb));
sb_breadahead(inode->i_sb, block);
}
static inline void
sb_breadahead(struct super_block *sb, sector_t block)
{
__breadahead(sb->s_bdev, block, sb->s_blocksize);
}
我们看到,ext2_preread_inode中首先获得inode对应的块组号block_group,然后通过这个块组号获得对应的ext2_group_desc。得到组描述符后,就可以得到该组对应磁盘索引节点表的磁盘首地址了,然后再根据i_ino得到该磁盘索引节点在表中的位置,赋给内部变量block。
通过sb_breadahead读入该索引节点对应磁盘索引节点对象进缓存,最后ext2_new_inode返回新索引节点对象inode的地址。这样,如果想得到i_ino对应的ext2_inode,就可以通过块设备的页高速缓存page->private->b_data获得。
当调用ext2_new_inode函数之后,新的inode和它对应的磁盘索引节点就建好了,并且缓存到了内存中,其体系结构如图:
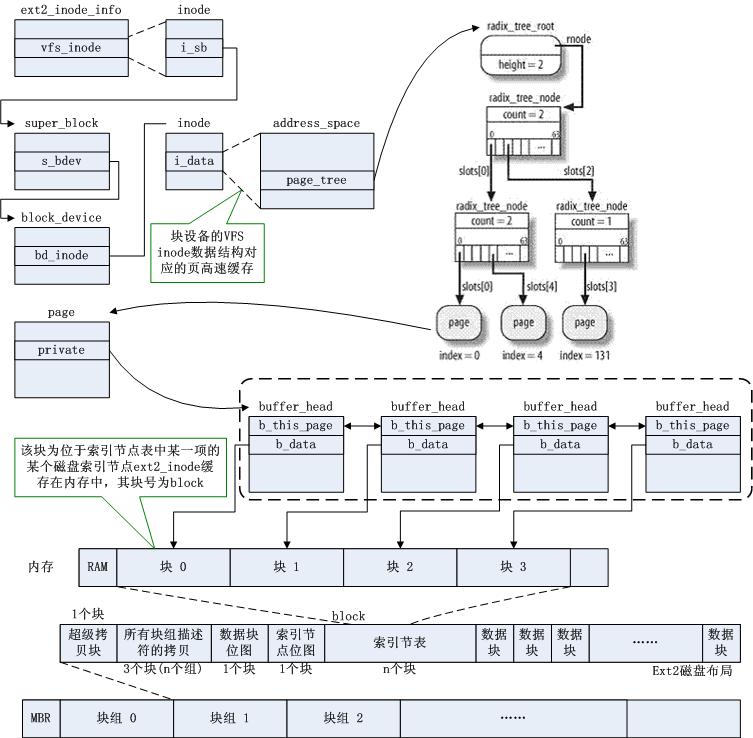
如图,VFS索引节点号为ino的inode,通过函数ext2_preread_inode计数就能得到它对应磁盘索引节点ext2_inode所在的块号block,然后把缓冲区页的描述符插人基树,树根是与块设备相关的特殊bdev文件系统中索引节点的address_space对象。这种缓冲区页必须满足很强的约束条件,就是所有的块缓冲区涉及的块必须是在块设备上相邻存放的,这也是为什么ext2磁盘布局中,所有磁盘索引节点必须连续存放在一个索引节点表中的原因。
还有一点要注意,如果一个页作为缓冲区页使用,那么与它的块缓冲区相关的所有缓冲区首部都被收集在一个单向循环链表中。缓冲区页描述符的private字段指向页中第一个块的缓冲区(由于private字段包含有效数据,而且页的PG_private标志被设置,因此,如果页中包含磁盘数据并且设置了PG_private标志,该页就是一个缓冲区页。注意,尽管如此,其他与块I/O子系统无关的内核组件也因为别的用途而使用private和PG_private字段);每个缓冲区首部存放在b_this_page字段中,该字段是指向链表中下一个缓冲区首部的指针。此外,每个缓冲区首部还把缓冲区页描述符的地址存放在b_page中。
至于__breadahead的底层是怎么实现的,对于块设备的页高速缓存(注意与后面的普通文件页高速缓存相区别)的详细内容,请访问博客“把块存放在页高速缓存中” http://blog.csdn.net/yunsongice/archive/2010/08/30/5850656.aspx。
- Ext2索引节点对象的创建
- Ext2的索引节点对象
- Ext2索引节点对象的读取
- EXT2目录文件索引节点的操作方法
- Ext2索引节点分配
- EXT2普通文件节点的操作方法
- Ext2的超级块对象
- Ext2的超级块对象
- EXT3元数据之索引节点的创建
- 超级块对象、索引节点对象、文件对象及目录项对象的数据结构
- VFS的索引节点
- VFS的索引节点
- document对象 动态的创建元素(节点)/添加元素(节点)/删除元素(节点)
- jquery:创建一个新的节点对象的好方法
- 创建Ext2文件系统
- VFS的索引节点 链接
- linux索引节点的介绍
- inode索引节点的概念
- (煤)矿安全防御
- Story in PeopleWare: 3
- Ext2的超级块对象
- 智能手机之战——windows phone 7的倒下(人生第一次翻译,多指教)
- Story in PeopleWare: 4
- Ext2索引节点对象的创建
- 安装和使用MySQL注意事项
- HTTP505错误
- php 注入和防御(1)
- Story in PeopleWare: 5
- php 注入和防御(2)
- Ext2索引节点对象的读取
- php 注入和防御(3)
- php 注入和防御(4)


