实用算法实践-第1篇排序
来源:互联网 发布:淘宝网店没生意怎么办 编辑:程序博客网 时间:2024/04/29 03:51
1.1 选择排序
许多排序算法比选择排序快多了,但是选择排序能够将排序的交换次数降到最少,这是它比冒泡排序的优点之所在。通过下面这个实例就可以深刻认识这一点。
1.1.1 实例
PKU JudgeOnline, 1674, Sorting by Swapping.
1.2 库函数的应用
快速排序函数qsort()非常好用,下面就是一些应用例子。
据说,STL的sort()函数比stdlib.h 的qsort()函数快。
1.2.1 库函数排序整数数组
#include <stdlib.h>int cmp(const void*p1, const void*p2){ return *(int *)p1 - *(int*)p2;}qsort(&people[1],N, sizeof(people[0]), cmp);上面的cmp函数中如果p1-p2则是非降序,如果p2-p1则是非升序。
1.2.2 库函数排序字符串数组
char word[1002][21];int cmp(const void*p1, const void*p2){ return strcmp((char*) p1,(char*)p2);}qsort(&word[0],num, 21 * sizeof(char),cmp);1.2.3 库函数排序结构体数组
1.2.4 实例
PKU JudgeOnline, 3664, Election Time.
1.2.5 问题描述
N个牛的选举分为两个阶段,第一阶段得票最高的前K个进入第二阶段,第二阶段得票最高的获胜。先输入N、K,然后是N对两阶段得票数。问哪只牛获胜。
1.2.6 输入
53
310
92
56
84
65
1.2.7 输出
5
1.2.8 程序
#include<stdio.h>#include<string.h>#include <stdlib.h>#include <iostream.h>struct Node{ int data1; int data2; int pos;};int cmp1(const void*p1, const void*p2){ return(*(Node *)p2).data1 > (*(Node *)p1).data1 ? 1 : -1;}int cmp2(const void*p1, const void*p2){ return(*(Node *)p2).data2 > (*(Node *)p1).data2 ? 1 : -1;}Nodefirst[50001];int main(){ int i; int N, K; while(cin>> N >> K){ for(i =0; i < N; i++){ scanf("%d%d",&first[i].data1, &first[i].data2); first[i].pos = i + 1; } qsort(first, N,sizeof(first[0]),cmp1);/* for(i = 0; i< N; i++){ cout<<first[i].pos<<" : "<<first[i].data1<<": "<<first[i].data2<<endl; }*/ qsort(first, K,sizeof(first[0]),cmp2);/* for(i = 0; i< N; i++){ cout<<first[i].pos<<" : "<<first[i].data1<<": "<<first[i].data2<<endl; }*/ cout << first[0].pos<<endl; } return 1;}1.3 快速排序的随机化
并不是所有的输入数据的所有排列都是等可能的。为了使得算法能获得较好的平均情况性能,可以加入随机化成分。
1.3.1 程序(未测试)
#include<stdio.h>#include<string.h>#include <stdlib.h>#define maxNum 10001#define ONLINE_JUDGE 0struct cow{int S;int E;//int sequence;//牛的编号,也就是在输入数据的第几个,//因为在输出的时候需要按照编号大小依次输出值//又因为cow不发生变化,所以可以不存};cow cow[maxNum];int pos[maxNum];//在排序之后第i大的数是cow数组的第pos[i]个元素//在任何时候,cow都不会变化。//所有排序都需要通过调整pos数组的指向来进行。int cmp(int i, int j){int Si;int Sj;int Ei;int Ej;Ei = cow[pos[i]].E;Ej = cow[pos[j]].E;Si = cow[pos[i]].S;Sj = cow[pos[j]].S;/*if(Si > Sj){return 1;}else{return -1;}*/if(Si <= Sj && Ej <= Ei && Ei - Si > Ej - Sj){return 1;}else{return -1;}}int sequence[maxNum];//pos数组的“逆”,即若pos[i] = j,那么sequence[j] = i;//通过sequence数组数组,可以知道cow数组的第i个元素于第sequence[i]名void exchange(int i, int j){int temp;sequence[pos[i]] = j;sequence[pos[j]] = i;temp = pos[i];pos[i] = pos[j];pos[j] = temp;}int Partition(int p, int r){int i;int j;int x;x = r;i = p - 1;for(j = p; j < r; j++){if(cmp(x, j) > 0)//(cow[j] <= x){i++;exchange(i, j);}}exchange(i + 1, r);return i + 1;}int randPartition(int p, int r){int i;i = (rand() % (r - p)) + p;exchange(i, r);return Partition(p, r);}void randQsort(int p, int r){int q;if(p < r){q = randPartition(p, r);randQsort(p, q - 1);randQsort(q + 1, r);}}int main(){#ifndef ONLINE_JUDGE FILE *fin;fin = freopen( "test.txt", "r", stdin);if( !fin ){printf( "reopen in file failed...\n"); while(1){}return 0;}freopen( "out.txt", "w", stdout);#endifint i;int j;int N;int result;while(scanf("%d", &N)){if(N == 0){break;}for(i = 0; i < N; i++){scanf("%d%d", &cow[i].S, &cow[i].E);sequence[i] = i;pos[i] = i;}randQsort(0, N - 1);for(i = 0; i < N - 1; i++){//printf("%d %d\n", cow[pos[i]].S, cow[pos[i]].E);result = sequence[i];for(j = result + 1; j < N; j++){if(cmp(j, result) > 0){break;}}result = N - j;printf("%d ", result);}printf("0\n");}#ifndef ONLINE_JUDGE //fclose(stdout);fclose(stdin);#endifreturn 1;}1.4 计数排序
《算法导论》中计数排序的伪代码如下所示: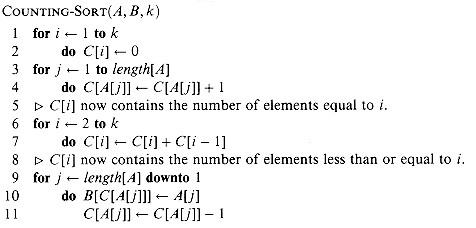
注意:10行和11行弄得这么复杂的原因是为了维持计数排序的稳定性。计数排序的稳定性对于使用该排序的基数排序的正确性来说非常重要。
计数排序的算法时间复杂度是Θ(k + n)。可以证明基于比较的排序算法下界为Ω(n lgn)。线性时间的排序算法不是基于比较的排序算法。
1.5 基数排序
虽然基数排序的时间复杂度是Θ(n),但是由于Θ记号中隐藏了常数因子的影响,所以比较基数排序和基于比较的排序算法的好坏需要考虑以下几个因素:
1. 算法的实现特性。排序算法通常可以比基数排序更为有效地利用硬件缓存。
2. 输入数据的特性。
3. 内存的速度。如果基数排序利用计数排序作为中间稳定排序,那么它就不是一个原地排序,而很多的Θ(n lgn)时间的比较排序算法可以做到原地排序。故此,如果内存容量比较宝贵,则原地排序算法比较可取。
一个非常好地利用了基数排序的例子是后缀数组的Skew构造算法。
1.6 实例
PKU JudgeOnline, 3664, Election Time.
PKU JudgeOnline, 3404, Bridge over a roughriver
PKU JudgeOnline, 1700, Crossing River.
PKU JudgeOnline, 3637, Shopaholic.
PKU JudgeOnline, 1674, Sorting by Swapping.
PKU JudgeOnline, 2231, Moo Volume.
本文章欢迎转载,请保留原始博客链接http://blog.csdn.net/fsdev/article
- 实用算法实践-第1篇排序
- 实用算法实践-第 3 篇堆排序
- 实用算法实践-第 32 篇 其它
- 实用算法实践-第 4 篇散列表
- 实用算法实践-第 22 篇字符串匹配
- 实用算法实践-第 28 篇 素数判别
- 实用算法实践-第 29 篇 计算几何学
- 实用算法实践-第 30 篇 组合数学
- 实用算法实践-第 31 篇 博弈游戏
- 实用算法实现-第 16 篇拓扑排序
- 实用算法实践-第 2 篇有序数组的二分查找
- 算法实践篇-基于快速排序原理的选择第i小元选择算法
- 算法实践篇-插入排序
- 算法实践篇-合并排序
- 算法实践篇-冒泡排序
- 算法实践篇-堆排序
- 算法实践篇-快速排序
- 算法实践篇-计数排序
- Firefox and Chrome’s WebGL validation on windows XP
- 怎样创建GWT+OSGi项目
- oracle vm import
- hibernate annotation之主键生成策略
- 网络编程中遇到的一些概念总结
- 实用算法实践-第1篇排序
- 普通字符设备LED驱动程序(IO映射内存实现)
- struts2.2.1配置
- 实用算法实践-第 3 篇堆排序
- FreeMarker使用实例
- 下载文件乱码问题
- 我对乔布斯及苹果的看法
- c语言编译--全过程
- 使用Spring Mail发送邮件


