享元模式
来源:互联网 发布:星际淘宝网txt下载 编辑:程序博客网 时间:2024/04/30 14:29
1 享元模式的日常应用
面向对象的思想确实很好地解决了抽象性的问题,以至于在面向对象的眼中,万事万物一切皆对象。不可避免的是,采用面向对象的编程方式,可能会增加一些资源和性能上的开销。不过,在大多数情况下,这种影响还不是太大,所以,它带来的空间和性能上的损耗相对于它的优点而言,基本上不用考虑。但是,在某些特殊情况下,大量细粒度对象的创建、销毁以及存储所造成的资源和性能上的损耗,可能会在系统运行时形成瓶颈。那么我们该如何去避免产生大量的细粒度对象,同时又不影响系统使用面向对象的方式进行操作呢?享元设计模式提供了一个比较好的解决方案。
公共交换电话网的使用方式就是生活中常见的享元模式的例子。公共交换电话网中的一些资源,例如拨号音发生器、振铃发生器和拨号接收器,都是必须由所有用户共享的,不可能为每一个人都配备一套这样的资源,否则公共交换电话网的资源开销也太大了。当一个用户拿起听筒打电话时,他根本不需要知道到底使用了多少资源,对用户而言所有的事情就是有拨号音,拨打号码,拨通电话就行了。所以,就有很有人会共用一套资源,非常节省,这就是享元模式的基本思想。
假如我们要开发一个类似MS Word的字处理软件,下面分析一下将如何来实现。对于这样一个字处理软件,它需要处理的对象既有单个字符,又有由字符组成的段落以及整篇文档,根据面向对象的设计思想,不管是字符、段落还是文档都应该作为单个的对象去看待。我们暂不考虑段落和文档对象,只考虑单个的字符,于是可以很容易的得到下面的结构图:
Java代码:
//抽象的字符类
public abstract classCharactor{
//属性
protected char letter;
protected int fontsize;
//显示方法
public abstract void display();
}
//具体的字符类A
public class CharactorA extendsCharactor{
//构造函数
public CharactorA(){
this.letter = 'A';
this.fontsize = 12;
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
}
//具体的字符类B
public class CharactorB extendsCharactor{
//构造函数
public CharactorB(){
this.letter = 'B';
this.fontsize = 12;
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
}
.Net代码:
//抽象的字符类
public abstract classCharactor{
//属性
protected char letter;
protected int fontsize;
//显示方法
public abstract void display();
}
//具体的字符类A
public class CharactorA :Charactor{
//构造函数
public CharactorA(){
this.letter = 'A';
this.fontsize = 12;
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
}
//具体的字符类B
public class CharactorB:Charactor{
//构造函数
public CharactorB(){
this.letter = 'B';
this.fontsize= 14;
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
}
我们的这段代码完全符合面向对象的思想,但是却为此搭上了太多的性能损耗,代价很昂贵。
一篇文档的字符数量很可能达到成千上万,甚至更多,那么在内存中就会同时存在大量的Charactor对象,这时候的内存开销可想而知。
我们对内存中的对象稍加分析就能发现,虽然内存中Character实例很多,但是里面有很多实例差不多是相同的,比如CharactorA类的实例就有可能出现过很多次,这些不同的CharactorA的实例之间只有部分状态不同而已。那么,我们是不是可以只创建一份CharactorA的实例,然后让整个系统共享这个实例呢?直接使用显然是行不通的。比如一份文档中使用了很多的字符A,虽然它们的属性letter相同,都是'A',但是它们的fontsize却不相同的,即字符大小并不相同。显然,对于实例中的相同状态是可以共享的,不同的状态就不能共享了。
为了解决这个问题,我们可以变换一下思路:首先将不可共享的状态从类里面剔除出去,即去掉fontsize这个属性,这时候我们再写一下代码:
Java代码:
//抽象的字符类
public abstract classCharactor{
//属性
protected char letter;
//显示方法
public abstract void display();
}
//具体的字符类A
public class CharactorA extendsCharactor{
//构造函数
public CharactorA(){
this.letter = 'A';
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
}
//具体的字符类B
public class CharactorB extendsCharactor{
//构造函数
public CharactorB(){
this.letter = 'B';
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
}
.Net代码:
//抽象的字符类
public abstract classCharactor{
//属性
protected char letter;
//显示方法
public abstract void display();
}
//具体的字符类A
public class CharactorA :Charactor{
//构造函数
public CharactorA(){
this.letter = 'A';
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
}
//具体的字符类B
public class CharactorB:Charactor{
//构造函数
public CharactorB(){
this.letter = 'B';
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
}
经过这次重构,类里面剩余的状态就可以共享了,下面我们要做的工作就是要控制Charactor类的创建过程。如果已经存在了“A”字符这样的实例,就不需要再创建,直接返回实例;如果没有,则创建一个新的实例,这跟单例模式的做法有点类似了。在单例模式中是由类自身维护一个唯一的实例,享元模式则引入一个单独的工厂类CharactorFactory来完成这项工作:
Java代码:
public class CharactorFactory{
private Hashtable<String,Charactor>charactors = new Hashtable<String,Charactor>();
//构造函数
public CharactorFactory(){
charactors.put("A", newCharactorA());
charactors.put("B", newCharactorB());
}
//获得指定字符实例
public Charactor getCharactor(String key){
Charactor charactor =(Charactor)charactors.get(key);
if (charactor == null){
if(key.equals("A")){
charactor = new CharactorA();
}else if(key.equals("B")){
charactor = new CharactorB();
}
charactors.put(key, charactor);
}
return charactor;
}
}
.Net代码:
//享元类工厂
public class CharactorFactory{
private Hashtable charactors = newHashtable();
//构造函数
public CharactorFactory(){
charactors.Add("A", newCharactorA());
charactors.Add("B", newCharactorB());
}
//获得指定字符实例
publicCharactor getCharactor(String key){
Charactor charactor = charactors[key] asCharactor;
if (charactor == null){
switch (key){
case "A": charactor =new CharactorA(); break;
case "B": charactor =new CharactorB(); break;
}
charactors.Add(key, charactor);
}
return charactor;
}
}
经过本次重构,已经可以使用同一个实例来存储可共享的状态,下面还需要做的工作就是要处理被剔除出去的那些不可共享的状态。缺少了这些不可共享的状态,Charactor对象就无法正常工作。
2 解决对象中不可共享状态的问题
我们先考虑一种比较简单的解决方案:对于不能共享的状态,不要在Charactor类中设置,而是由客户程序在自己的代码中进行设置:
Java代码:
//客户程序
public class ClinetTest{
publicstatic void main(String[] args){
Charactora = new CharactorA();
Charactorb = new CharactorB();
//显示字符A
display(a,12);
//显示字符B
display(b,14);
}
//设置字符的大小
publicvoid display(Charactor objChar, int nSize){
try{
System.out.println("字符:" +objChar.letter + ",大小:" + nSize);
}catch(Exceptionerr){
}
}
}
.Net代码:
//客户程序
public class ClinetTest{
publicstatic void Main(String[] args){
Charactora = new CharactorA();
Charactorb = new CharactorB();
//显示字符A
display(a,12);
//显示字符B
display(b,14);
}
//设置字符的大小
public void display(Charactor objChar, intnSize){
Console.WriteLine("字符:" +objChar.letter + ",大小:" + nSize);
}
}
按照这样的实现思路,可以发现如果有多个客户端程序使用的话,会出现大量的重复性的逻辑,就像上面这段代码中的display方法一样,需要所有的客户端都提供,因此,这段代码已经出现了臭味,非常不利于代码的复用和维护。另外,把这些状态和行为移到客户程序里面破坏了面向对象中封装的原则。
所以,我们再次转变我们的实现思路,把这些不可共享的状态仍然保留在Charactor对象中,把不同的状态通过参数化的方式,由客户程序注入。以下代码是我们最终实现的一个版本:
Java代码:
//抽象的字符类
public abstract classCharactor{
//属性
protected char letter;
protected int fontsize;
//显示方法
publicabstract void display();
//设置字体大小
publicabstract void setFontSize(int fontsize);
}
//具体的字符类A
public class CharactorA extendsCharactor{
//构造函数
public CharactorA(){
this.letter = 'A';
this.fontsize = 12;
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
//设置字体大小
publicvoid setFontSize(int fontsize){
this.fontsize = fontsize;
}
}
//具体的字符类B
public class CharactorB extendsCharactor{
//构造函数
public CharactorB(){
this.letter = 'B';
this.fontsize = 12;
}
//显示方法
public void display(){
try{
System.out.println(this.letter);
}catch(Exception err){
}
}
//设置字体大小
publicvoid setFontSize(int fontsize){
this.fontsize = fontsize;
}
}
//客户程序
public class ClinetTest{
publicstatic void main(String[] args){
Charactora = new CharactorA();
Charactorb = new CharactorB();
//设置字符A的大小
a.setFontSize(12);
//显示字符B
a.display();
//设置字符B的大小
b.setFontSize(14);
//显示字符B
b.display();
}
}
.Net代码:
//抽象的字符类
public abstract classCharactor{
//属性
protectedchar letter;
protectedint fontsize;
//显示方法
publicabstract void display();
//设置字体大小
publicabstract void setFontSize(int fontsize);
}
//具体的字符类A
public class CharactorA :Charactor{
//构造函数
publicCharactorA(){
this.letter = 'A';
this.fontsize = 12;
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
//设置字体大小
publicoverride void setFontSize(int fontsize){
this.fontsize = fontsize;
}
}
//具体的字符类B
public class CharactorB:Charactor{
//构造函数
publicCharactorB(){
this.letter = 'B';
this.fontsize= 14;
}
//显示方法
public override void display(){
Console.WriteLine(this.letter);
}
//设置字体大小
publicoverride void setFontSize(int fontsize){
this.fontsize = fontsize;
}
}
//客户程序
public class ClinetTest{
publicstatic void Main(String[] args){
Charactora = new CharactorA();
Charactorb = new CharactorB();
//设置字符A的大小
a.setFontSize(12);
//显示字符B
a.display();
//设置字符B的大小
b.setFontSize(14);
//显示字符B
b.display();
}
}
可以看到这样的实现明显优于第一种实现思路,这就是享元模式的基本思想。我们通过享元模式实现了节省存储资源的目的。
3 什么是享元模式
享元的英文是Flyweight,它是一个来自于体育方面的专业用语,在拳击、摔跤和举重比赛中特指最轻量的级别。把这个单词移植到软件工程里面,也是用来表示特别小的对象,即细粒度对象。至于为什么我们把Flyweight翻译为“享元”,可以理解为共享元对象,也就是共享细粒度对象。享元模式就是通过使用共享的方式,达到高效地支持大量的细粒度对象。它的目的就是节省占用的空间资源,从而实现系统性能的改善。
我们把享元对象的所有状态分成两类,其实前面的例子中letter和fontsize属性在运行时,就形成了两类不同的状态。
享元对象的第一类状态称为内蕴状态(InternalState)。它不会随环境改变而改变,存储在享元对象内部,因此内蕴状态是可以共享的,对于任何一个享元对象来讲,它的值是完全相同的。我们例子中Character类的letter属性,它代表的状态就是内蕴状态。
享元对象的第二类状态称为外蕴状态(ExternalState)。它会随环境的改变而改变,因此是不可以共享的状态,对于不同的享元对象来讲,它的值可能是不同的。享元对象的外蕴状态必须由客户端保存,在享元对象被创建之后,需要使用的时候再传入到享元对象内部。我们例子中Character类的fontsize属性,它代表的状态就是外蕴状态。
所以享元的外蕴状态与内蕴状态是两类相互独立的状态,彼此没有关联。
我们按照前面的分析,给出享元模式的类图:
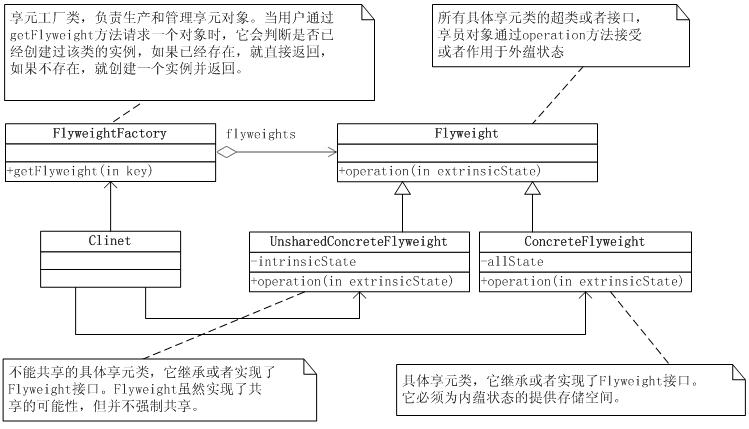
享元模式类图
抽象享元类(Flyweight)
它是所有具体享元类的超类。为这些类规定出需要实现的公共接口,那些需要外蕴状态(Exte的操作可以通过方法的参数传入。抽象享元的接口使得享元变得可能,但是并不强制子类实行共享,因此并非所有的享元对象都是可以共享的。
具体享元类(ConcreteFlyweight)
具体享元类实现了抽象享元类所规定的接口。如果有内蕴状态的话,必须负责为内蕴状态提供存储空间。享元对象的内蕴状态必须与对象所处的周围环境无关,从而使得享元对象可以在系统内共享。有时候具体享元类又称为单纯具体享元类,因为复合享元类是由单纯具体享元角色通过复合而成的。
不能共享的具体享元类(UnsharableFlyweight)
不能共享的享元类,又叫做复合享元类。一个复合享元对象是由多个单享元对象组成,这些组成的对象是可以共享的,但是复合享元类本身并不能共享。
享元工厂类(FlyweightFactoiy)
享元工厂类负责创建和管理享元对象。当一个客户端对象请求一个享元对象的时候,享元工厂需要检查系统中是否已经有一个符合要求的享元对象,如果已经有了,享元工厂角色就应当提供这个已有的享元对象;如果系统中没有适当的享元对象的话,享元工厂角色就应当创建一个新的合适的享元对象。
客户类(Client)
客户类需要自行存储所有享元对象的外蕴状态。
4 实现和使用享元模式需要注意的问题
面向对象虽然很好地解决了抽象性的问题,但是对于一个实际运行的软件系统,我们还需要考虑面向对象的代价问题,享元模式解决的就是面向对象的代价问题。享元模式采用对象共享的做法来降低系统中对象的个数,从而降低细粒度对象给系统带来的内存压力。
在具体实现方面,我们要注意对象状态的处理,一定要正确地区分对象的内蕴状态和外蕴状态,这是实现享元模式的关键所在。
享元模式的优点在于它大幅度地降低内存中对象的数量。为了做到这一点,享元模式也付出了一定的代价:
1、享元模式为了使对象可以共享,它需要将部分状态外部化,这使得系统的逻辑变得复杂。
2、享元模式将享元对象的部分状态外部化,而读取外部状态使得运行时间会有所加长。
另外,我们还有一个比较关心的问题:到底系统需要满足什么样的条件才能使用享元模式。对于这个问题,我们总结了以下几条:
1、一个系统中存在着大量的细粒度对象;
2、这些细粒度对象耗费了大量的内存。
3、这些细粒度对象的状态中的大部分都可以外部化;
4、这些细粒度对象可以按照内蕴状态分成很多的组,当把外蕴对象从对象中剔除时,每一个组都可以仅用一个对象代替。
5、软件系统不依赖于这些对象的身份,换言之,这些对象可以是不可分辨的。
满足以上的这些条件的系统可以使用享元对象。最后,使用享元模式需要维护一个记录了系统已有的所有享元的哈希表,也称之为对象池,而这也需要耗费一定的资源。因此,应当在有足够多的享元实例可供共享时才值得使用享元模式。如果只能够节省百八十个对象的话,还是没有必要引入享元模式的,毕竟性价比不高。
5 什么情况下使用享元模式
享元模式在一般的项目开发中并不常用,而是常常应用于系统底层的开发,以便解决系统的性能问题。
Java和.Net中的String类型就是使用了享元模式。如果在Java或者.NET中已经创建了一个字符串对象s1,那么下次再创建相同的字符串s2的时候,系统只是把s2的引用指向s1所引用的具体对象,这就实现了相同字符串在内存中的共享。如果每次执行s1=“abc”操作的时候,都创建一个新的字符串对象的话,那么内存的开销会很大。
如果大家有兴趣的话,可以用下面的程序进行测试,就会知道s1和s2的引用是否一致:
Java代码:
String s1 = "测试字符串1";
String s2 = "测试字符串1";
//“==”用来判断两个对象是否是同一个,equals判断字符串的值是否相等
if( s1 == s2 ){
System.out.println("两者一致");
}else{
System.out.println("两者不一致");
}
.Net代码:
String s1 = "测试字符串1";
String s2 = "测试字符串1";
if( Object.ReferenceEquals(s1,s2) ){
Console.WriteLine("两者一致");
}else{
Console.WriteLine("两者不一致");
}
程序运行后,输出的结果为“两者一致”,这说明String类的设计采用了享元模式。如果s1的内容发生了变化,比如执行了s1 += "变化"的语句,那么s1与s2的引用将不再一致。
至于Php作为一种弱类型语言,它的字符串类型是一种基本类型,不是对象。另外,它的执行方式与Java和.Net也有明显区别,每一个脚本文件执行开始,将会装入所有需要的资源;执行结束后,又将占用的资源就立即全部释放,所以它基本上不会产生类似的性能问题,它的字符串处理的设计,自然也使用不到享元模式。
- 深入浅出享元模式
- 享元模式
- 享元(FlyWeight)模式
- 享元模式
- 享元模式
- 享元模式
- 享元模式
- 享元模式Flyweight
- 享元模式
- 享元模式
- 享元模式
- FlyWeight 享元模式
- 享元模式(Flyweight)
- 享元模式
- 享元模式
- 享元模式
- 享元模式
- 享元模式 ---flyweight
- 第九周任务一:Complex类的扩展
- 12个小球称3次得到质量不同的那个小球
- IT 男,在大家的眼睛里
- 数据结构和算法------有序数组和二分查找
- Spring bean生命周期UML图示(10级学员 林常禹课堂总结)
- 享元模式
- 动态规划学习二
- 第九周任务(4)
- 第九周 任务三
- 酒店管理系统
- jquery的each方法
- TVP5150视频解码器学习
- Spring中自动装配(10级学员 郎志课堂总结)
- java UDP编程


