memcached源码剖析系列之内存存储机制
来源:互联网 发布:ubuntu卸载qq国际版 编辑:程序博客网 时间:2024/04/30 13:18
http://www.cnblogs.com/moonlove/tag/memcached/
一 内存分配管理机制
memcached是一个高性能的,分布式内存对象缓存系统,用于在动态系统中减少数据库负载,提升性能。memcached有一个很有特色的内存管理方式,为了提高效率,默认情况下采用了名为Slab Allocator的机制分配管理内存空间。
memcached文档中关于slab allocator有这么一段话:
the primary goal of the slabs subsystem in memcached was to eliminate memory fragmentation issues totally by using fixed-size memory chunks coming from a few predetermined size classes.
由此,我们可以看出,memcached使用预申请内存并分组成特定块的方式,旨在解决内存碎片的问题。
Memcached的内存管理方式还是比较简单易懂的,使用的是slab->chunk的组织方式管理内存。Slab是Memcached进行内存申请的最小单位,默认一般为1MB,可使用命令行参数进行自定义设置。然后使用分块机制将slab分成一定大小分成若干个chunks。如下图所示(此图来源于网络):

二 源码分析
1 关键数据结构
(1)settings结构体原型:
/* When adding a setting, be sure to update process_stat_settings *//** * Globally accessible settings as derived from the commandline. */struct settings { //最大内存, 默认64M,最大2G。通过-m 设定 size_t maxbytes; //最大连接数,默认1024 通过-c设定 int maxconns; //tcp 端口号,通过-p 设置 int port; //ucp 端口号,通过-U 设置 int udpport; //监听IP或SOCKET地址 ,通过-l设定 char *inter; //是否输出debug信息。由-v,-vvv参数设定 int verbose; //时间设定,当使用flsuh时,只需要修改本值,当取出的值时间小于本值时,将被忽略。 rel_time_t oldest_live; /* ignore existing items older than this */ //当内存存满时,是否淘汰老数据。默认是是。可用-M修改为否。此时内容耗尽时,新插入数据时将返回失败。 int evict_to_free; //socket模式,使用-s设定。 char *socketpath; /* path to unix socket if using local socket */ //socket文件的文件权限,使用-a设定 int access; /* access mask (a la chmod) for unix domain socket */ //slab分配增量因子,默认围1.25, 可通过-f设定 double factor; /* chunk size growth factor */ //给一个key+value+flags 分配的最小字节数。 默认值为48. 可通过-n修改。 int chunk_size; //工作线程数。默认围4, 可通过-t设定 int num_threads; /* number of worker (without dispatcher) libevent threads to run */ //状态详情的key前缀 char prefix_delimiter; /* character that marks a key prefix (for stats) */ //开启状态详情记录 int detail_enabled; /* nonzero if we're collecting detailed stats */ //每个event处理的请求数 int reqs_per_event; /* Maximum number of io to process on each io-event. *///开启cas,"cas"是一个存储检查操作。用来检查脏数据的存操作。在取出数据后,如果没有其他人修改此数据时,本进程才能够存储数据。默认为开启。需要版本:1.3+ bool use_cas; //使用协议, 试过-B参数设定。 可能值为:ascii, binary, or auto, 版本: 1.4.0+ enum protocol binding_protocol; //等待处理的排队队列长度。默认值为1024. int backlog; //单个item最大字计数。默认1M。可通过-I参数修改。在1.4.2版本之后,这个值可以大于1M,必须小于128M。但memcached会抛出警告,大于1M将导致整体运行内存的增加和内存性能的降低。 版本: 1.4.2+ int item_size_max; /* Maximum item size, and upper end for slabs */ //是否开启sasl bool sasl; /* SASL on/off */};(2)item结构体原型:
typedef struct _stritem { struct _stritem *next; struct _stritem *prev; struct _stritem *h_next; /* hash chain next */ rel_time_t time; /* least recent access */ rel_time_t exptime; /* expire time */ int nbytes; /* size of data */ unsigned short refcount; uint8_t nsuffix; /* length of flags-and-length string */ uint8_t it_flags; /* ITEM_* above */ uint8_t slabs_clsid;/* which slab class we're in */ uint8_t nkey; /* key length, w/terminating null and padding */ /* this odd type prevents type-punning issues when we do * the little shuffle to save space when not using CAS. */ union { uint64_t cas; char end; } data[]; /* if it_flags & ITEM_CAS we have 8 bytes CAS */ /* then null-terminated key */ /* then " flags length\r\n" (no terminating null) */ /* then data with terminating \r\n (no terminating null; it's binary!) */} item;(3)slabclass_t结构体原型
typedef struct { unsigned int size; /* sizes of items */ unsigned int perslab; /* how many items per slab */ void **slots; /* list of item ptrs */ unsigned int sl_total; /* size of previous array */ unsigned int sl_curr; /* first free slot */ void *end_page_ptr; /* pointer to next free item at end of page, or 0 */ unsigned int end_page_free; /* number of items remaining at end of last alloced page */ unsigned int slabs; /* how many slabs were allocated for this class */ void **slab_list; /* array of slab pointers */ unsigned int list_size; /* size of prev array */ unsigned int killing; /* index+1 of dying slab, or zero if none */ size_t requested; /* The number of requested bytes */} slabclass_t;(4)memcatchd.c文件中定义的部分宏
#define POWER_SMALLEST 1#define POWER_LARGEST 200#define CHUNK_ALIGN_BYTES 8#define DONT_PREALLOC_SLABS#define MAX_NUMBER_OF_SLAB_CLASSES (POWER_LARGEST + 1)
2 分配算法的实现
(1)memcatchd.c中main函数中运行状态的初始化
int main(){ … settings_init(); … //利用命令行参数信息,对setting进行设置 while (-1 != (c = getopt(argc, argv,…) {…} … //settings.factor 初始化为1.25,可以使用命令行参数-f进行设置 slabs_init(settings.maxbytes, settings.factor, preallocate);}settings_init()是初始化全局变量settings函数,在memcatchd.c文件实现
static void settings_init(void) { settings.use_cas = true; settings.access = 0700; settings.port = 11211; settings.udpport = 11211; /* By default this string should be NULL for getaddrinfo() */ settings.inter = NULL; settings.maxbytes = 64 * 1024 * 1024; /* default is 64MB */ settings.maxconns = 1024; /* to limit connections-related memory to about 5MB */ settings.verbose = 0; settings.oldest_live = 0; settings.evict_to_free = 1; /* push old items out of cache when memory runs out */ settings.socketpath = NULL; /* by default, not using a unix socket */ settings.factor = 1.25; settings.chunk_size = 48; /* space for a modest key and value */ settings.num_threads = 4; /* N workers */ settings.num_threads_per_udp = 0; settings.prefix_delimiter = ':'; settings.detail_enabled = 0; settings.reqs_per_event = 20; settings.backlog = 1024; settings.binding_protocol = negotiating_prot; settings.item_size_max = 1024 * 1024; /* The famous 1MB upper limit. */}从该设置setting的初始化函数可看出,settings.item_size_max = 1024 * 1024; 即每个slab默认的空间大小为1MB,settings.factor = 1.25; 默认设置item的size步长增长因子为1.25。使用命令行参数对setting进行定制后,调用slabs_init函数,根据配置的setting来初始化slabclass。slabs_init函数于Slabs.c文件中实现:
// slabs管理器初始化函数:limit默认64MB,prealloc默认false,可使用命令行参数’L’进行设置。void slabs_init(const size_t limit, const double factor, const bool prealloc) { int i = POWER_SMALLEST - 1;//#define POWER_SMALLEST 1;i初始化为0 //item(_stritem):storing items within memcached unsigned int size = sizeof(item) + settings.chunk_size;//chunk_size:48 mem_limit = limit; //limit默认64MB//预分配为真时: if (prealloc) { /* Allocate everything in a big chunk with malloc */ mem_base = malloc(mem_limit); if (mem_base != NULL) {//mem_current:静态变量,记录分配内存块的基地址//mem_avail:可用内存大小 mem_current = mem_base; mem_avail = mem_limit; } else { fprintf(stderr, "Warning: Failed to allocate requested memory in" " one large chunk.\nWill allocate in smaller chunks\n"); } } //static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES]; //#define MAX_NUMBER_OF_SLAB_CLASSES (POWER_LARGEST + 1) //#define POWER_LARGEST 200 memset(slabclass, 0, sizeof(slabclass)); // /* settings.item_size_max: Maximum item size, and upper end for slabs,默认为1MB */ //item核心分配算法 while (++i < POWER_LARGEST && size <= settings.item_size_max / factor) { /* Make sure items are always n-byte aligned *///#define CHUNK_ALIGN_BYTES 8 if (size % CHUNK_ALIGN_BYTES) //确保size为CHUNK_ALIGN_BYTES的倍数,不够则向补足 size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES); slabclass[i].size = size; slabclass[i].perslab = settings.item_size_max / slabclass[i].size; //记录每个slab中item的个数 size *= factor; //每次循环size的大小都增加factor倍 if (settings.verbose > 1) { fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n", i, slabclass[i].size, slabclass[i].perslab); } } //补足一块大小为item_size_max的块 power_largest = i; slabclass[power_largest].size = settings.item_size_max; slabclass[power_largest].perslab = 1; if (settings.verbose > 1) { fprintf(stderr, "slab class %3d: chunk size %9u perslab %7u\n", i, slabclass[i].size, slabclass[i].perslab); } /* for the test suite: faking of how much we've already malloc'd */ { char *t_initial_malloc = getenv("T_MEMD_INITIAL_MALLOC"); if (t_initial_malloc) { mem_malloced = (size_t)atol(t_initial_malloc); } }#ifndef DONT_PREALLOC_SLABS //已经定义了 { char *pre_alloc = getenv("T_MEMD_SLABS_ALLOC"); if (pre_alloc == NULL || atoi(pre_alloc) != 0) { slabs_preallocate(power_largest); } }#endif}在memcached的内存管理机制中,使用了一个slabclass_t类型(类型声明见上“关键数据结构”一节)的数组slabclass对划分的slab及进行统一的管理
slabclass的声明:static slabclass_t slabclass[MAX_NUMBER_OF_SLAB_CLASSES];
每一个slab被划分为若干个chunk,每个chunk里保存一个item,每个item同时包含了item结构体、key和value(注意在memcached中的value是只有字符串的)。slab按照自己的id分别组成链表,这些链表又按id挂在一个slabclass数组上,整个结构看起来有点像二维数组。
在定位item时,使用slabs_clsid函数,传入参数为item大小,返回值为classid:
/* * Figures out which slab class (chunk size) is required to store an item of * a given size. * Given object size, return id to use when allocating/freeing memory for object * 0 means error: can't store such a large object */unsigned int slabs_clsid(const size_t size) { int res = POWER_SMALLEST; if (size == 0) return 0; while (size > slabclass[res].size) if (res++ == power_largest) /* won't fit in the biggest slab */ return 0; //分配的值不能满足 return res; //返回第一个大于size的索引值}根据返回的索引值即可定位到满足该size的slabclass项。从源码中可以看出:chunk的size初始值为sizeof(item)+settings.chunk_size(key 和 value所使用的最小空间,默认为48);chunk的大小以factor的倍数进行增长,最高为slab的最大值的一半,最后一个slab的大小为slab的最大值,这也是memcached所能允许分配的最大的item值。
本小节到此结束,在下一小节中将继续分析memcached的存储机制并分析该机制的优缺点。
注:本系列文章基于memcached-1.4.6版本进行分析。
reference:
[1] http://blog.developers.api.sina.com.cn/?p=124&cpage=1#comment-1506
[2] http://kb.cnblogs.com/page/42732/
在上一节中已经分析了memcached的内存分配管理初始化机制,在这节中我们将详细分析memcached中slab的管理与分配机制。
slabclass[MAX_NUMBER_OF_SLAB_CLASSES]数组是slab管理器(类型见上节),是memcached内存管理的核心数据结构,起着非常重要的作用。
slabclass[i]的内存示意图如下图所示:
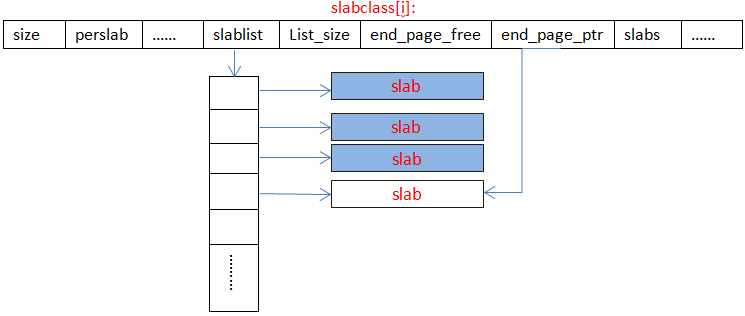
(1) size和perslab保存着每个slab分配的chunk的大小,及可分配的chunk数。
(2) slablist是一个二维指针,指向一个指针列表,列表的长度为list_size * sizeof(void*),列表中的一项指向一个slab。
(3) end_page_ptr是一个指向最新分配的slab的指针。
源码:
(1)do_slabs_newslab()函数实现
//为该id的slab链分配一个新的slabstatic int do_slabs_newslab(const unsigned int id) { slabclass_t *p = &slabclass[id]; int len = p->size * p->perslab; char *ptr;//grow_slab_list():如果slabs已经用完了,增长链表的长度//memory_allocate():为新slab分配memory if ((mem_limit && mem_malloced + len > mem_limit && p->slabs > 0) || (grow_slab_list(id) == 0) || ((ptr = memory_allocate((size_t)len)) == 0)) { MEMCACHED_SLABS_SLABCLASS_ALLOCATE_FAILED(id); return 0; } memset(ptr, 0, (size_t)len);//p->end_page_ptr:指向新分配的slab,p->end_page_free为新slab空余items数 p->end_page_ptr = ptr; p->end_page_free = p->perslab; p->slab_list[p->slabs++] = ptr; mem_malloced += len; MEMCACHED_SLABS_SLABCLASS_ALLOCATE(id); return 1;}这个函数的作用是当一个slab用光后,又有新的item要插入这个id,那么它就会重新申请新的slab,申请新的slab时,对应id的slab链表就要增长(由grow_slab_list()函数来实现),这个链表是成倍增长的,初始化值为16。
(2)grow_slab_list()函数实现
static int grow_slab_list (const unsigned int id) { slabclass_t *p = &slabclass[id];//p->slabs:已经分配的slab数,p->list_size:slab链表的长度 if (p->slabs == p->list_size) {//表示slabs已经用完 size_t new_size = (p->list_size != 0) ? p->list_size * 2 : 16; void *new_list = realloc(p->slab_list, new_size * sizeof(void *)); if (new_list == 0) return 0; p->list_size = new_size; p->slab_list = new_list; } return 1;}(3)memory_allocate()函数实现
static void *memory_allocate(size_t size) { void *ret; if (mem_base == NULL) { /* We are not using a preallocated large memory chunk */ ret = malloc(size); } else { ret = mem_current; if (size > mem_avail) { return NULL; } /* mem_current pointer _must_ be aligned!!! */ if (size % CHUNK_ALIGN_BYTES) { size += CHUNK_ALIGN_BYTES - (size % CHUNK_ALIGN_BYTES); } mem_current = ((char*)mem_current) + size; if (size < mem_avail) { mem_avail -= size; } else { mem_avail = 0; } } return ret;}该函数为一个slab分配p->size * p->perslab大小的内存,并由slab_list中一个指针指向它。
另外,memcached不会释放掉已用完的item指针的内存,其使用结构体slabclass_t中的slots二维指针来保存释放出来的item指针,sl_total表示总的数量,sl_curr表示的是目前可用的已经释放出来的item数量。
每一次要分配内存的时候,首先根据需要分配的内存大小在slabclass数组中查找索引最小的一个大于所要求内存的slab,如果slots不为空,那么就从这里返回内存,否则去查找end_page_ptr,如果也没有,那么就只能返回NULL了.
每一次释放内存的时候,同样的找到应该返回内存的slab元素,改写前面提到的slot指针和sl_curr数。这个过程由do_slabs_alloc()和do_slabs_free()完成。
memcached的内存分配机制的缺点
memcached的内存分配是有冗余的:
(1) 当一个slab不能被它所拥有的chunk大小整除时,slab尾部剩余的空间就被丢弃了。
(2) memcached的另外一个内存冗余发生在保存item的过程中,item总是小于或等于chunk大小的,当item小于chunk大小时,就又发生了空间浪费。
在memcached内存存储机制剖析的前两篇文章中,已分析过memcached的内存管理器初始化机制及slab的管理分配机制。接下来我们就来探讨下对象item的分配管理及LRU机制。
1 item关键数据结构
(1)item结构体原型

typedef struct _stritem { struct _stritem *next; struct _stritem *prev; struct _stritem *h_next; /* hash chain next */ rel_time_t time; /* least recent access */ rel_time_t exptime; /* expire time */ int nbytes; /* size of data */ unsigned short refcount; uint8_t nsuffix; /* length of flags-and-length string */ uint8_t it_flags; /* ITEM_* above */ uint8_t slabs_clsid;/* which slab class we're in */ uint8_t nkey; /* key length, w/terminating null and padding */ /* this odd type prevents type-punning issues when we do * the little shuffle to save space when not using CAS. */ union { uint64_t cas; char end; } data[]; /* if it_flags & ITEM_CAS we have 8 bytes CAS */ /* then null-terminated key */ /* then " flags length\r\n" (no terminating null) */ /* then data with terminating \r\n (no terminating null; it's binary!) */} item;
(2)全局数组
static item *heads[LARGEST_ID];
保存各个slab class所对应的item链表的表头。
static item *tails[LARGEST_ID];
保存各个slab class所对应的item链表的表尾。
static unsigned int sizes[LARGEST_ID];
保存各个slab class所对应的items数目。
2 item分配机制的函数实现
(1)LRU机制
在前面的分析中已介绍过,memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible,透明),其存储空间即可重复使用。Memcached采用的是Lazy Expiration,即memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy(惰性)expiration。因此,memcached不会在过期监视上耗费CPU时间。
memcached会优先使用已超时的记录的空间,但即使如此,也会发生追加新记录时空间不足的情况,此时就要使用名为 Least Recently Used(LRU)机制来分配空间,即删除“最近最少使用”的记录。
(2)函数实现
Item的分配在函数do_item_alloc()中实现,函数原型为:
item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes);
参数含义:
* key - The key
* nkey - The length of the key
* flags - key flags
*exptime –item expired time
* nbytes - Number of bytes to hold value and addition CRLF terminator
函数的具体实现如下,由于do_item_alloc()太长,这里只贴出部分关键代码:
item *do_item_alloc(char *key, const size_t nkey, const int flags, const rel_time_t exptime, const int nbytes) { uint8_t nsuffix; item *it = NULL; char suffix[40]; size_t ntotal = item_make_header(nkey + 1, flags, nbytes, suffix, &nsuffix); //settings.use_cas:?cas"是一个存储检查操作,用来检查脏数据的存操作。 if (settings.use_cas) { ntotal += sizeof(uint64_t); } unsigned int id = slabs_clsid(ntotal);//获得slabclass索引值 if (id == 0) return 0; /* do a quick check if we have any expired items in the tail.. */ int tries = 50; item *search; //在item链表中遍历过期item for (search = tails[id]; tries > 0 && search != NULL; tries--, search=search->prev) { if (search->refcount == 0 && (search->exptime != 0 && search->exptime < current_time)) { …….} } //没有过期数据时,采用LRU算法,淘汰老数据 if (it == NULL && (it = slabs_alloc(ntotal, id)) == NULL) { /* ** Could not find an expired item at the tail, and memory allocation ** failed. Try to evict some items! */ tries = 50; /* If requested to not push old items out of cache when memory runs out, * we're out of luck at this point... */ // 当内存存满时,是否淘汰老数据。默认为真。可用-M修改为否。此时内容耗尽时,新插入数据时将返回失败。 …… it = slabs_alloc(ntotal, id); //返回新分配的slab的第一个item //item分配失败,做最后一次努力 if (it == 0) { itemstats[id].outofmemory++; /* Last ditch effort. There is a very rare bug which causes * refcount leaks. We've fixed most of them, but it still happens, * and it may happen in the future. * We can reasonably assume no item can stay locked for more than * three hours, so if we find one in the tail which is that old, * free it anyway. */ tries = 50; for (search = tails[id]; tries > 0 && search != NULL; tries--, search=search->prev) { //search->time:最近一次访问的时间 if (search->refcount != 0 && search->time + TAIL_REPAIR_TIME < current_time) { …… } it = slabs_alloc(ntotal, id); if (it == 0) { return NULL; } } } ……. it->next = it->prev = it->h_next = 0; it->refcount = 1; /* the caller will have a reference */ DEBUG_REFCNT(it, '*'); it->it_flags = settings.use_cas ? ITEM_CAS : 0; it->nkey = nkey; it->nbytes = nbytes; //零长数组 memcpy(ITEM_key(it), key, nkey); it->exptime = exptime; memcpy(ITEM_suffix(it), suffix, (size_t)nsuffix); it->nsuffix = nsuffix; return it;}
该函数首先调用item_make_header()函数计算出该item的总长度,如果脏数据检查标志设置的话,添加sizeof(uint64_t)的长度,以便从slabclass获得索引值(使用slabs_clsid()函数返回)。接着从后往前遍历item链表,注意全局数组heads[LARGEST_ID]和tails[LARGEST_ID]保存了slabclass对应Id的链表头和表尾。
从源码中我们可以看出,有三次遍历循环,每次最大遍历次数为50(tries表示),//在item链表中遍历过期item,如果某节点的item设置了过期时间并且该item已过期,则回收该item,,调用do_item_unlink()把它从链表中取出来。
若向前查找50次都没有找到过期的item,则调用slabs_alloc()分配内存,如果alloc失败,接着从链表尾开始向前找出一些没有人用的refcount=0的item,调用do_item_unlink(),再用slabs_alloc()分配内存,如果还失败,只能从链表中删除一些正在引用但过期时间小于current_time – CURRENT_REPAIR_TIME的节点,这个尝试又从尾向前尝试50次,OK,再做最后一次尝试再去slabs_alloc()分配内存,如果这次还是失败,那就彻底放弃了,内存分配失败。
Memcached的内存管理方式是非常精巧和高效的,它很大程度上减少了直接alloc系统内存的次数,降低函数开销和内存碎片产生几率,虽然这种方式会造成一些冗余浪费,但是这种浪费在大型系统应用中是微不足道的。
- Memcached源码剖析系列之内存存储机制(一)
- memcached源码剖析系列之内存存储机制(二)
- memcached源码剖析系列之内存存储机制
- Memcached源码剖析系列之内存存储机制(一)
- memcached源码剖析系列之内存存储机制(二)
- memcached源码剖析系列之内存存储机制(三)
- Memcached源码剖析系列之内存存储机制(一)
- memcached源码剖析之内存管理
- Memcached源码分析之内存管理
- Memcached源码分析之内存管理 【转】
- Memcached源码阅读之内存初始化
- Memcached源码分析之内存池
- Memcached源码分析之内存管理篇
- Memcached源码分析之内存管理篇
- Memcached源码分析之内存管理篇
- Memcached源码分析之内存管理
- Memcached源码分析之内存管理
- Memcached源码分析之内存管理
- svn的恢复到指定版本操作
- ios与android语音通用方案 编译libopencore-amr xcode4.5/ios6版本
- DIV布局如何正确的使用 id 和 class
- 也谈成功
- ActiveXObject函数详解
- memcached源码剖析系列之内存存储机制
- linux上chrome、vlc等程序root不能运行的解决办法
- 三一撤离湖南影响湖南GDP
- 检测收的sim卡的状态,并调用系统的打电话功能
- java基础要点(5)面向对象-静态
- KG—ARM-Thumb子程序调用规则—ATPCS
- Oracle jobs定时任务
- Select相关操作
- linux常用svn命令


