hbase的coprocessor机制来在hbase上增加sql解析引擎
来源:互联网 发布:三星移动网络定时开关 编辑:程序博客网 时间:2024/06/07 01:52
自己参与构建的一个产品,其场景是每天凌晨批量导入计算好的前一天相关的业务数据到前端存储(数据库或者nosql),然后供用户调用。业务场景有2个特点:
1.对于前端存储,存在大量的批量导入,数据量比较大,每天导入的数据达到数亿行。可以理解为凌晨集中写,然后白天只进行读。
2.查询来说相对简单,如果是存数据库的话,每个表大概会由3~4个列来构成一个组合索引,然后查询就是根据这个组合索引来进行。
产品刚上线的时候,前端存储是选用的mysql,后来由于mysql在写入时压力确实很大,而且也不想让所有的技术方案都绑定在关系数据库上,套用某知名DBA的话,我们自己需要拥有在不同存储上进行切换的能力,而且业务场景的2个特点,都比较符合hbase,所以决定选用hbase进行尝试。
但是这样问题又来了,产品刚上线的时候,使用的mysql,所以在业务实现上,使用了大量的sql,而且,我们也觉得sql是好东西(不要被nosql 这个名词所糊弄,其实这个名字取的有点不好,从我的理解来讲,nosql的起因是现有关系数据库做了太多的事情,比如事物,B+索引等,导致关系数据库本身代码很复杂,同时写入比较慢;而对于很多业务场景来说,其实它可能只需要用到关系数据库的部分功能,但是没有选择,却要承担关系数据库做了太多事情带来的恶果;而对于sql,一来其语义表达能力强,二来其本身代价也不大,先阶段毕竟还是IO是最耗时的,sql解析不是瓶颈,物美价廉,为啥不用),所以我们想让hbase也支持sql,这样相当于我们对选用的所有的存储都有一个统一的接口要求,即该存储的接口需要能支持sql。
从业务场景上,可以推出我们的需求:
1.数据是批量写的,不需要对写实现sql功能。
2.查询简单,可以理解为查询都可以落到rowkey上。
3.sql处理只读,不需要考虑事物等复杂的问题。
好了,既然需求已经比较清楚了,现在就要来看如何进行实现了,从架构层面来说,这个sql引擎有2个地方可以放,一个是放在客户端,即sql解析后,解析出startkey,endkey后,拼装成一个scan,发送给hbase server,拿到hbase server的返回的数据后,再根据sql里面的条件,对这些数据进行过滤,返回给业务层。还有一个就是将sql解析引擎放在hbase 服务端,sql引擎和hbase之间的数据传递直接在region server 的jvm进程内进行传递,sql引擎将数据过滤后,再返回给业务层。放在server 端相对于放在客户端的好处是如果sql引擎需要过滤大量的数据话,这些数据直接在服务端就被过滤掉,不需要耗费客户端和服务端之间的网络流量,性能会更高一些。so,在我们的实现里,我们选择在服务端放sql 引擎。
这个决定做了后,其实我们大的架构也基本定了,如下图所示:
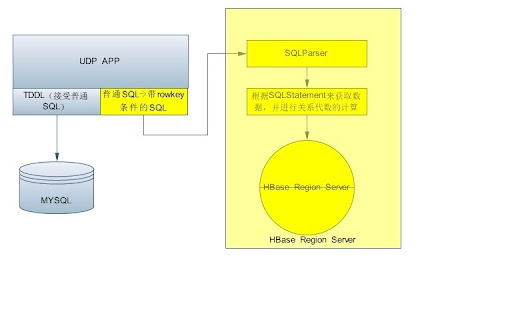
为了方便理解,其实大家可以将mysql认为是一个sql 解析引擎+一个存储引擎(实际上mysql也确实是这样做的,其架构上分成了server+各种存储引擎的插件,而sql解析就是在server这一层做掉的)。而现有的hbase则是一个存储引擎,你能往里面写入数据,也能从中获取数据,而我们现在要做的,就是要在其上增加一个sql 解析引擎,从而使的其看起来像个关系数据库。
好了,大的架构定了,那么如何将sql引擎部署到hbase上去,以及sql引擎如何与hbase打交道?这一块幸亏0.92的hbase里提供了coprocessor机制,我们可以将自己的sql引擎封装成一个coprocessor,来实现接收客户端的请求,并将请求的sql进行解析,转换成hbase能够识别的scan,利用scan获取数据,然后将获取回来的数据再根据sql进行过滤和计算等,然后返回给客户端。
这里sql的解析,使用的是druid,阿里巴巴B2B开源的一个项目(之所以用druid,因为我们是在淘宝,大家属于一个集团,有问题也好解决,sql解析本身有很多成熟的开源软件,所以如果你自己所在公司不是阿里巴巴集团的,其实可能还是选择其他成熟的开源项目更靠谱一些)。druid我就不详细介绍了,有兴趣的同学可以去看一下该开源项目,加深了解。
- hbase的coprocessor机制来在hbase上增加sql解析引擎
- HBase Coprocessor的分析
- hbase coprocessor的分析
- hbase的coprocessor使用
- HBASE coprocessor 的分析
- hbase的coprocessor使用
- hbase的coprocessor使用
- hbase coprocessor
- org.apache.hadoop.hbase.coprocessor.AggregateImplementation 来统计表的行数
- org.apache.hadoop.hbase.coprocessor.AggregateImplementation 来统计表的行数
- 【转载】HBase Coprocessor的分析
- hbase coprocessor小实践引发的对coprocessor异常处理机制的探究
- org.apache.hadoop.hbase.coprocessor.AggregateImplementation 来统计hbase表的行数
- Hbase总结:Hbase中的Coprocessor
- Hbase总结:Hbase中的Coprocessor
- Hbase的Coprocessor应用(1)
- hbase coprocessor 源码分析
- HBase Coprocessor Endpint运行机制
- 解决 fastboot no permission问题
- Android Call requires API level 11 (current min is 8)的解决方案
- 非常棒的二分查找所有情况的考虑
- linux mint13 android使用错误修改记录
- Android多媒体开发 Pro Android Media 第一章 Android图像编程入门 2
- hbase的coprocessor机制来在hbase上增加sql解析引擎
- SSRS报表开发三部曲(转)
- IIS 6.0中部署mvc
- 寒假训练--训练赛2--加密术
- libevent源码分析---时间管理模块
- Android编程之解决android-support-v4打包问题
- android Camera拍照 及 MediaRecorder录像 预览图像差90度
- github总结
- MINA之心跳协议运用


