算法导论 | 第22章基本的图算法
来源:互联网 发布:游戏支付软件 编辑:程序博客网 时间:2024/05/01 23:49
图的基本定义就不细讲了,可以参考“图的理论基础”,写的相当好。这里只是总结。
1:图的种类
图一般分为有向图和无向图;如果给每条边赋予一定的权值,那么这样的图叫网。
2:图的存储结构
常用的数组结构是“邻接矩阵”和“邻接表”。还有两种但是不常用:邻接多重表 和 十字链表。下面主要讲解邻接矩阵和邻接表。
-------邻接矩阵和邻接表的优缺点
①邻接表适用于稀疏图,邻接矩阵适用于稠密图
②另外,由于邻接矩阵简单明了,当图较小时,更多地采用邻接矩阵。
③如果一个图不是加权的,采用邻接矩阵还有一个好处:在储存邻接矩阵的每个元素时,可以只使用一个二进位,而不必用一个字的空间。
④需要快速判断两个结点之间是否有边相连,更多用邻接矩阵(用邻接链表需要遍历Adj[u])
(1)邻接矩阵
邻接矩阵是指用矩阵来表示图。它是采用矩阵来描述图中顶点之间的关系(及弧或边的权)。
假设图中顶点数为n,则邻接矩阵定义为:

无向图

有向图

通常采用两个数组来实现邻接矩阵:一个一维数组用来保存顶点信息,一个二维数组来用保存边的信息。
邻接矩阵的缺点就是比较耗费空间。
(2)邻接表
邻接表是图的一种链式存储表示方法。它是改进后的"邻接矩阵",它的缺点是不方便判断两个顶点之间是否有边,但是相对邻接矩阵来说更省空间。
无向图

有向图
3:邻接矩阵的表示和代码
(1)基本定义
// 邻接矩阵typedef struct _graph{ char vexs[MAX]; // 顶点集合 int vexnum; // 顶点数 int edgnum; // 边数 int matrix[MAX][MAX]; // 邻接矩阵}Graph, *PGraph;Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
(2)创建矩阵
参考代码:http://www.cnblogs.com/skywang12345/p/3707597.html
完整代码示例:https://github.com/wangkuiwu/datastructs_and_algorithm/blob/master/source/graph/basic/udg/c/matrix_udg.c
4:邻接表的表示和代码
(1)基本定义
// 邻接表中表对应的链表的顶点typedef struct _ENode{ int ivex; // 该边所指向的顶点的位置 struct _ENode *next_edge; // 指向下一条弧的指针}ENode, *PENode;// 邻接表中表的顶点typedef struct _VNode{ char data; // 顶点信息 ENode *first_edge; // 指向第一条依附该顶点的弧}VNode;// 邻接表typedef struct _LGraph{ int vexnum; // 图的顶点的数目 int edgnum; // 图的边的数目 VNode vexs[MAX];}LGraph;(01) LGraph是邻接表对应的结构体。
vexnum是顶点数,edgnum是边数;vexs则是保存顶点信息的一维数组。
(02) VNode是邻接表顶点对应的结构体。
data是顶点所包含的数据,而first_edge是该顶点所包含链表的表头指针。
(03) ENode是邻接表顶点所包含的链表的节点对应的结构体。
ivex是该节点所对应的顶点在vexs中的索引,而next_edge是指向下一个节点的。
(2)创建矩阵
参考代码:http://www.cnblogs.com/skywang12345/p/3707607.html
完整代码:https://github.com/wangkuiwu/datastructs_and_algorithm/blob/master/source/graph/basic/udg/c/list_udg.c
5:广度优先算法
(1)算法介绍
广度优先搜索算法(Breadth First Search),又称为"宽度优先搜索"或"横向优先搜索",简称BFS。
换句话说,广度优先搜索遍历图的过程是以v为起点,由近至远,依次访问和v有路径相通且路径长度为1,2...的顶点。
①:通过队列来实现!
②:广度优先搜索是很多重要的图算法的原型。在Prim最小生成树和Dijkstra单源最短路径算法中,都采用了与广度优先搜索类似的思想。
③:可以用来求最短路径问题,但只能用于无权图,即每条边的权重都是单位权重图。
(2)无向图
下面以"无向图"为例,来对广度优先搜索进行演示。还是以上面的图G1为例进行说明。
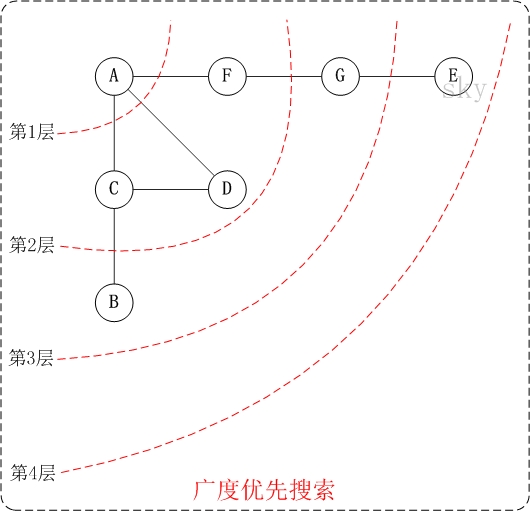
第1步:访问A。
第2步:依次访问C,D,F。
在访问了A之后,接下来访问A的邻接点。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,C在"D和F"的前面,因此,先访问C。再访问完C之后,再依次访问D,F。
第3步:依次访问B,G。
在第2步访问完C,D,F之后,再依次访问它们的邻接点。首先访问C的邻接点B,再访问F的邻接点G。
第4步:访问E。
在第3步访问完B,G之后,再依次访问它们的邻接点。只有G有邻接点E,因此访问G的邻接点E。
因此访问顺序是:A -> C -> D -> F -> B -> G -> E
(3)有向图
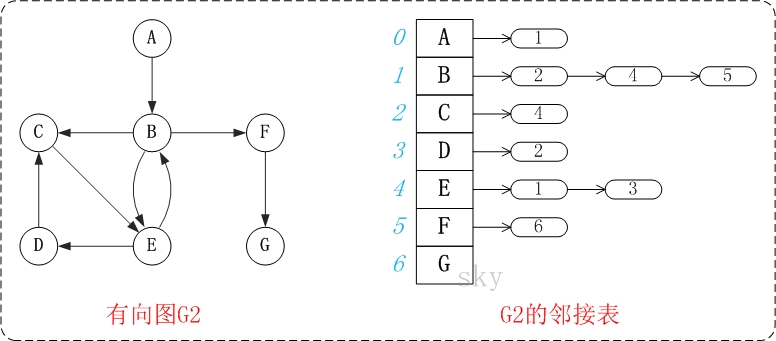
下面以"有向图"为例,来对广度优先搜索进行演示。还是以上面的图G2为例进行说明。
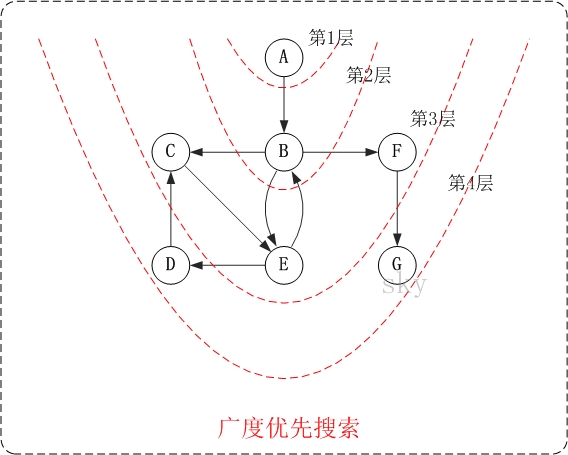
第1步:访问A。
第2步:访问B。
第3步:依次访问C,E,F。
在访问了B之后,接下来访问B的出边的另一个顶点,即C,E,F。前面已经说过,在本文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访问E,F。
第4步:依次访问D,G。
在访问完C,E,F之后,再依次访问它们的出边的另一个顶点。还是按照C,E,F的顺序访问,C的已经全部访问过了,那么就只剩下E,F;先访问E的邻接点D,再访问F的邻接点G。
因此访问顺序是:A -> B -> C -> E -> F -> D -> G
6:深度优先算法
(1)算法介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比较类似。
它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点v出发,首先访问该顶点,然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和v有路径相通的顶点都被访问到。 若此时尚有其他顶点未被访问到,则另选一个未被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。
1:显然,深度优先搜索是一个递归的过程。
2:应用在--有向图分解成强连通分量。
(2)无向图
下面以"无向图"为例,来对深度优先搜索进行演示。

对上面的图G1进行深度优先遍历,从顶点A开始。
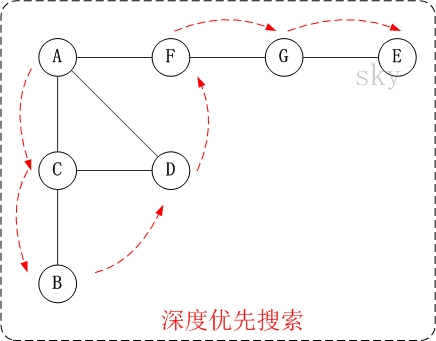
第1步:访问A。
第2步:访问(A的邻接点)C。
在第1步访问A之后,接下来应该访问的是A的邻接点,即"C,D,F"中的一个。但在本文的实现中,顶点ABCDEFG是按照顺序存储,C在"D和F"的前面,因此,先访问C。
第3步:访问(C的邻接点)B。
在第2步访问C之后,接下来应该访问C的邻接点,即"B和D"中一个(A已经被访问过,就不算在内)。而由于B在D之前,先访问B。
第4步:访问(C的邻接点)D。
在第3步访问了C的邻接点B之后,B没有未被访问的邻接点;因此,返回到访问C的另一个邻接点D。
第5步:访问(A的邻接点)F。
前面已经访问了A,并且访问完了"A的邻接点B的所有邻接点(包括递归的邻接点在内)";因此,此时返回到访问A的另一个邻接点F。
第6步:访问(F的邻接点)G。
第7步:访问(G的邻接点)E。
因此访问顺序是:A -> C -> B -> D -> F -> G -> E
(3)有向图
下面以"有向图"为例,来对深度优先搜索进行演示。

对上面的图G2进行深度优先遍历,从顶点A开始。
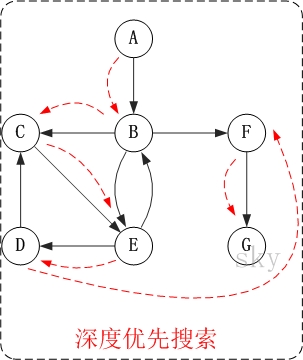
第1步:访问A。
第2步:访问B。
在访问了A之后,接下来应该访问的是A的出边的另一个顶点,即顶点B。
第3步:访问C。
在访问了B之后,接下来应该访问的是B的出边的另一个顶点,即顶点C,E,F。在本文实现的图中,顶点ABCDEFG按照顺序存储,因此先访问C。
第4步:访问E。
接下来访问C的出边的另一个顶点,即顶点E。
第5步:访问D。
接下来访问E的出边的另一个顶点,即顶点B,D。顶点B已经被访问过,因此访问顶点D。
第6步:访问F。
接下应该回溯"访问A的出边的另一个顶点F"。
第7步:访问G。
因此访问顺序是:A -> B -> C -> E -> D -> F -> G
7:广度优先和深度优先的实现
伪代码可以参考我之前写的《深度优先算法和广度优先算法》
想深入了解完整实现,参考《图的遍历》中下面的C代码实现,比如邻接矩阵实现的无向图
8:拓扑排序
(1)理论意义
将一个有向无环图进行排序,得到一个有序的线性序列。
例如,一个项目包括A、B、C、D四个子部分来完成,并且A依赖于B和D,C依赖于D。现在要制定一个计划,写出A、B、C、D的执行顺序。这时,就可以利用到拓扑排序,它就是用来确定事物发生的顺序的。
在拓扑排序中,如果存在一条从顶点A到顶点B的路径,那么在排序结果中B出现在A的后面。
为什么不能包含环?因为其选取第一个无依赖的顶点,然后放入队列再深度搜索。一旦有了环,就不能排出一个先后顺序。
(2)算法步骤
1. 构造一个队列Q(queue) 和 拓扑排序的结果队列T(topological);
2. 把所有没有依赖顶点的节点放入Q;
3. 当Q还有顶点的时候,执行下面步骤:
3.1 从Q中取出一个顶点n(将n从Q中删掉),并放入T(将n加入到结果集中);
3.2 对n每一个邻接点m(n是起点,m是终点);
3.2.1 去掉边<n,m>;
3.2.2 如果m没有依赖顶点,则把m放入Q;
注:顶点A没有依赖顶点,是指不存在以A为终点的边。
(3)举例说明
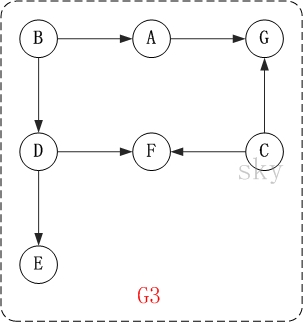
以上图为例,来对拓扑排序进行演示。

第1步:将B和C加入到排序结果中。
顶点B和顶点C都是没有依赖顶点,因此将C和C加入到结果集T中。假设ABCDEFG按顺序存储,因此先访问B,再访问C。访问B之后,去掉边<B,A>和<B,D>,并将A和D加入到队列Q中。同样的,去掉边<C,F>和<C,G>,并将F和G加入到Q中。
(01) 将B加入到排序结果中,然后去掉边<B,A>和<B,D>;此时,由于A和D没有依赖顶点,因此并将A和D加入到队列Q中。
(02) 将C加入到排序结果中,然后去掉边<C,F>和<C,G>;此时,由于F有依赖顶点D,G有依赖顶点A,因此不对F和G进行处理。
第2步:将A,D依次加入到排序结果中。
第1步访问之后,A,D都是没有依赖顶点的,根据存储顺序,先访问A,然后访问D。访问之后,删除顶点A和顶点D的出边。
第3步:将E,F,G依次加入到排序结果中。
因此访问顺序是:B -> C -> A -> D -> E -> F -> G
注意:遍历结点i的子节点的时候,会删掉i发出的边;当将结点i的子节点放入队列时,要考察该子节点是否含有“其他父节点”,如果有的话,就不放入队列!
(4)基本定义
// 邻接表中表对应的链表的顶点typedef struct _ENode{ int ivex; // 该边所指向的顶点的位置 struct _ENode *next_edge; // 指向下一条弧的指针}ENode, *PENode;// 邻接表中表的顶点typedef struct _VNode{ char data; // 顶点信息 ENode *first_edge; // 指向第一条依附该顶点的弧}VNode;// 邻接表typedef struct _LGraph{ int vexnum; // 图的顶点的数目 int edgnum; // 图的边的数目 VNode vexs[MAX];}LGraph;(01) LGraph是邻接表对应的结构体。 vexnum是顶点数,edgnum是边数;vexs则是保存顶点信息的一维数组。
(02) VNode是邻接表顶点对应的结构体。 data是顶点所包含的数据,而firstedge是该顶点所包含链表的表头指针。
(03) ENode是邻接表顶点所包含的链表的节点对应的结构体。 ivex是该节点所对应的顶点在vexs中的索引,而nextedge是指向下一个节点的。
(5)拓扑排序的实现
参考链接:拓扑排序
9:强连通分量
(1)主要应用深度优先算法
强连通分支定义:有向图G = (V, E)的一个强连通分支----一个最大顶点集合C ∈V,对于C中的每一对顶点u和v,有u->v和v->u;亦即,顶点u和v是互相可达的。
(2)步骤
先上伪代码:
STRONGLY-CONNECTED-COMPONENTS (G)1 call DFS (G) to compute finishing times f[u] for each vertex u2 compute GT3 call DFS (GT), but in the main loop of DFS, consider the vertices in order of decreasing f[u] (as computed in line 1)4 output the vertices of each tree in the depth-first forest formed in line 3 as a separate strongly connected component
②求图的转置GT
③在GT中选取结束时间点最晚的结点开始深度优先遍历。
④遍历得到的,就是所求的强连通分支。
10:相关例题
图的算法
- 算法导论代码 第22章 图的基本算法
- 算法导论 | 第22章基本的图算法
- 算法导论 第22章 图的基本算法 22.1 图的表示
- 算法导论 第22章 图的基本算法 22.1 图的表示
- 算法导论-第22章-基本的图算法-22.1 图的表示
- 算法导论 第22章 图的基本算法 22.4 拓扑排序
- 算法导论 第22章 图的基本算法 22.5 强联通分支
- 算法导论习题解-第22章基本的图算法
- 广度优先搜索(算法导论第22章-基本的图算法)
- 算法导论-第22章-基本的图算法-22.2 广度优先搜索(BFS)
- 算法导论-第22章-基本的图算法-22.3 深度优先搜索(DFS)
- 算法导论-第22章-基本的图算法-22.5 强连通分量
- 算法导论 第22章 图的基本算法(一)
- 算法导论 第22章 图的基本算法(二) 深度优先搜索
- 算法导论 第22章 图的基本算法(三) 拓扑排序
- 算法导论 第22章 图的基本算法(四) 强连通分支
- 算法导论-第22章-基本的图算法-22.5 强连通分量
- 《算法导论》第22章 基本的图算法 个人笔记
- 最大公因数、最小公倍数、因式分解
- Struts——三大组件(二)RequestProcessor
- OCM实验-手工建库
- 官方文档 恢复备份指南八 RMAN Backup Concepts
- NYOJ 91 阶乘之和
- 算法导论 | 第22章基本的图算法
- <ASP.NET4 从入门到精通>学习笔记3
- Java中,利用反射机制修改定义出来的String对象本身。
- 《Programming in Lua 3》读书笔记(七)
- 《ASP.NET4 从入门到精通》学习笔记4
- Problem 1049 - 斐波那契数
- Struts——ActionForm
- 关于PHP中数组的增删改 统计问题
- ip多播


