从图割到图像分割 - 图的构造
来源:互联网 发布:上海高通待遇 知乎 编辑:程序博客网 时间:2024/06/05 15:14
从图割到图像分割(二)——图的构造
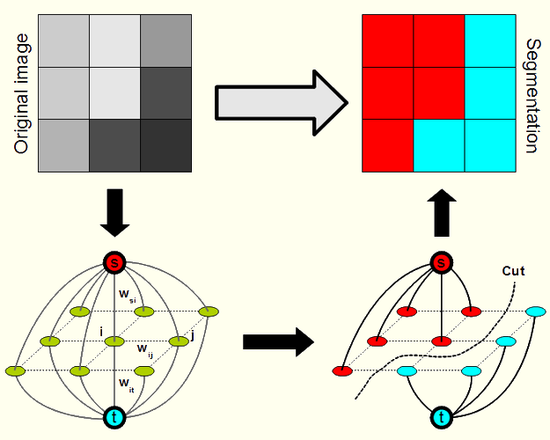
之前解释了为什么能用最大流最小割算法来做图像分割,其实更为正式的引用,即为众多paper所写的那样,图割其实是用来优化能量函数的,我是从自己的一些体会来写的,因为“能量函数”这东西,太过虚无飘渺,不够直观,不便于理解。
在我了解了为什么能够用过做图像分割后,又有问题困扰我:为什么我们所见到的图构建都是四邻域或八邻域的?为什么不是一个全域图(两两相连)?
这个问题似乎也有很多搞图像分割的大牛注意到了,他们最初或许是在实验中发现四邻域和八邻域已经很好了,但后来他们还是给为什么这样做提供了理论依据
Markov Random Field
马尔克夫随机场是解释这个问题的最有力理论依据,先看马尔克夫随机场定义:它包含两层意思:一是什么是马尔可夫,二是什么是随机场。
马尔可夫一般是马尔可夫性质的简称。它指的是一个随机变量序列按时间先后关系依次排开的时候,第N+1时刻的分布特性,与N时刻以前的随机变量的取值无关。拿天气来打个比方。如果我们假定天气是马尔可夫的,其意思就是我们假设今天的天气仅仅与昨天的天气存在概率上的关联,而与前天及前天以前的天气没有关系。其它如传染病和谣言的传播规律,就是马尔可夫的。
随机场包含两个要素:位置(site),相空间(phase space)。当给每一个位置中按照某种分布随机赋予相空间的一个值之后,其全体就叫做随机场。我们不妨拿种地来打个比方。“位置”好比是一亩亩农田;“相空间”好比是种的各种庄稼。我们可以给不同的地种上不同的庄稼,这就好比给随机场的每个“位置”,赋予相空间里不同的值。所以,俗气点说,随机场就是在哪块地里种什么庄稼的事情。
好了,明白了上面两点,就可以讲马尔可夫随机场了。还是拿种地打比方,如果任何一块地里种的庄稼的种类仅仅与它邻近的地里种的庄稼的种类有关,与其它地方的庄稼的种类无关,那么这些地里种的庄稼的集合,就是一个马尔可夫随机场。
在图割的图构造里面,其实就是:当前节点只与邻近的四邻域或八邻域节点相关,故可以只构建四邻域或八邻域图
图构造的数学模型
说到这里,先看看典型的能量函数模型:
$E(L)=\sum{p\in{P}}D_p(L_p) + \sum{(p,q)\in{N}}V_{p,q}(L_p,L_q)$
这里有
以上两项都叫做惩罚项,意味着突袭那个分割的每一次“割断”,都会带来惩罚,如何使得总惩罚最小,即可看作是最优的完成了图像分割的任务。
然而,假使要使得能量函数最优时即为最好的分割结果,上式每项就必须赋予相应的含义,否则构建一个与分割无关的能量函数模型,即使将能量函数最小化,也无任何意义。
我们知道基于图割的图像分割大多都是交互式分割,什么叫做交互式分割?就是用户提供一些先验知识,然后根据这些先验知识对原有的数学模型进行量化,得到一个可优化的数学表达式。例如,用户可以通过认定一张图像上的一个苹果是他所要的目标,则他在图像上圈定苹果,我们程序知道了用户圈定的点是属于前景点,则可以将所有类似苹果的像素点都归类为前景点,这就是交互式的一种方法。
在此也是,前面一项
也许由前面的信息就可以大致判断当前像素的归类了,那后面一项有什么意义呢?
后面一项表示相邻像素点间的约束信息,举个例子:如果当前像素属于前景点,那么它左边一个点或者右边一个点与当前点相似,那么它属于前景的概率是不是也很大?在前面一项不能准确判断的时候,这时候这个约束关系就作用明显了。
Tlink的构建
Tlink,在能量函数中一般称为数据项,即上式左半部分:T在这里表示Terminal,一般而言,源点表示的是前景,汇点表示的是背景。
如前面所说,Tlink的构建与所给信息相关,考虑到Tlink的权值的话,则如果当前像素属于前景,切断的应该是与汇点连接的Tlink,反之则切断与源点相连接的Tlink。
假设,将相似性归一化,则相似性可看作是属于某一类的概率值,如根据已有信息,得到某个归一化的相似性权值p,则可以说它属于前景的概率为p,这样属于背景的概率就是1-p了。
当然很多情况下,为了公平起见,还是会提供一些背景点,用类似前景Tlink的方法构建背景Tlink。
然而,这里就有个问题:在我有一堆点作为前景点的前提下,我如何算一个点与给定点的相似度?
事实上,这本身就是一个值得探讨的问题,我只是说说我见过的一些方法:
1)算距离平均值/得到中心点算距离;
2)算与最近/最远点的距离;
3)用已有点构建单高斯模型,用所构建的单高斯模型算相似性;
4)用已有点构建多高斯模型(GMM),用所构建的GMM来算相似性;
这些都是比较常用的方法,在所发表的文章中看,用的最多的是4,我想一来是效果好,而来是有更好的理论可以些(原来我这么揣测)
Nlink的构建
对比来说,Nlink的构建是比较简单的。这里N可以解释为Neighbor,在图的构造上即为相互邻接的像素点相连,Nlink表示“邻接”像素点之间的约束关系,即切断“邻接”像素点(换句话说,将邻接的像素点分为不同类)所需花费的惩罚,所以简单来说,就只需要弄清两个问题:
1)怎样算是“邻接”?
2)作为邻接的像素点,其权值如何设定?
一般来说,“邻接”都是采用四邻域或八领域,理由如前面所述,权值的设定,一般都采用高斯权值:
i与像素j的特征,这里的特征既可以指颜色特征,也可以指其它特征。
简略总结Tlink与Nlink的作用
Tlink作为数据项,尽可能的将像素归类为正确的类别,保证像素分类的正确性;
Nlink作为平滑项,尽可能的约束相邻像素不被切断,保持数据的平滑,在图像上,表现为边界平滑;
最终结果在以上两者的共同影响下得到!
- 从图割到图像分割 - 图的构造
- 从图割到图像分割 - 最大流算法
- 从图割到图像分割 - 多层图图割
- 基于图的图像分割
- 图像分割—基于图的图像分割
- 图像分割的关键
- 指纹图像的分割
- 图像分割的知识
- 图像分割—基于图的图像分割(Graph-Based Image Segmentation)
- 图像分割—基于图的图像分割(OpenCV源码注解)
- 图像分割—基于图的图像分割(Graph-BasedImageSegmentation)
- 图像分割—基于图的图像分割(Graph-BasedImageSegmentation)
- 图像分割—基于图的图像分割(Graph-BasedImageSegmentation)
- 图像分割—基于图的图像分割(Graph-Based Image Segmentation)
- 图像分割—基于图的图像分割(Graph-Based Image Segmentation)
- 图像分割—基于图的图像分割(Graph-BasedImageSegmentation)
- 图像分割—基于图的图像分割(Graph-Based Image Segmentation)
- 图像分割—基于图的图像分割(Graph-BasedImageSegmentation)
- Spring JdbcTemplate框架(二)——动态建表
- 20个设计模式和软件设计面试问题
- 从图割到图像分割 - 最大流算法
- android 自定义滚动上下回弹scollView
- Android中实现视频全屏播放
- 从图割到图像分割 - 图的构造
- Friend, Season 1, episode 1
- MFC透明图标
- Python实现类似局域网QQ群聊
- 从图割到图像分割 - 多层图图割
- MFC添加背景音乐
- MFC生成release文件
- 第一篇博客 来自2015年5月24日23:01:22,儿子已经睡着了....
- MFC删除边框后如何拖动窗口


