排序算法一:内部排序算法Python实现
来源:互联网 发布:deepin linux卸载软件 编辑:程序博客网 时间:2024/06/08 11:53
内部排序算法-Python实现
标签: Algorithm
- 内部排序算法-Python实现
- 检查排序算法的正确性代码
- 交换排序
- 1 冒泡排序
- 2 快速排序
- 插入排序
- 1 直接插入排序
- 2 折半插入排序
- 3 希尔排序
- 选择排序
- 1 简单选择排序
- 2 堆排序
- 归并排序
- 1 二路归并
- 线性时间排序
- 1 计数排序
- 2 基数排序RadixSort
- 3 桶排序BuckSort
- 比较
0. 检查排序算法的正确性代码
将排序算法的名称传入valid即可(默认随机生成10以内的6个数用排序算法进行排序;可根据实际情况进行调整)。
import randomdef valid(Sort): success = True for i in range(100): x = [] for j in range(6): x.append(random.randrange(10)) y = x[:] Sort(x) if not x == sorted(y): success = False print("x:") print(y) print("sort(x):") print(x) if success: print("Success!")1.交换排序
1.1 冒泡排序
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为较小的元素好比水中的气泡逐渐向上漂浮,较大的元素好比石块向下沉,每一趟有一块最大的石头沉到水底。
def BubbleSort(lists): count = len(lists) for i in range(count): order = True for j in range(0,count-1-i): if lists[j] > lists[j+1]: order = False lists[j], lists[j+1] = lists[j+1],lists[j] #swap if order: return1.2 快速排序
基本思想:
1)选择一个基准元素,通常选择第一个元素
2)通过一趟排序讲待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
3)此时基准元素在其排好序后的正确位置
4)然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序。
def QuickSort(lists): QSort(lists,0,len(lists)-1)def QSort(lists,start,end): if start >= end: return keyLoc = Partion(lists,start,end) QSort(lists,start,keyLoc) QSort(lists,keyLoc + 1,end)def Partion(lists,low,high): key = lists[low] while low < high: while high > low and lists[high] >= key: high -= 1 lists[low] = lists[high] while low < high and lists[low] < key: low += 1 lists[high] = lists[low] lists[low] = key return low2. 插入排序
2.1 直接插入排序
将一个记录插入到已排序好的有序表中,从而得到一个新,记录数增1的有序表。即:先将序列的第1个记录看成是一个有序的子序列,然后从第2个记录逐个进行插入,直至整个序列有序为止。
def InsertSort(lists): for i in range(1,len(lists)): value = lists[i] j = i - 1 while j >= 0 and lists[j] > value: lists[j+1] = lists[j] j -= 1 lists[j+1] = value2.2 折半插入排序
不再从前一个位置开始进行比较,而是利用前面有序的优点,进行“折半查找”,找到插入位置
def BInsertSort(lists): for i in range(1,len(lists)): if lists[i] < lists[i-1]: list[i] = lists[i-1] value =lists[i] low = 0 high = i-1 while low < high: mid = (low + high)//2 if lists[mid] <= value: low = mid + 1 else: high = mid - 1 for j in range(low,i-1): lists[j + 1] = lists[j] list[low] = value2.3 希尔排序
基本思想:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
操作方法:1. 选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;2.按增量序列个数k,对序列进行k趟排序;3.每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
增量序列有多种取法,但需:(1)最后一个增量值必须等于1 (2)应使增量序列中的值最好没有除1以外的公因子
下面代码中的增量序列为:2n−1
def ShellSort(lists): n = len(lists) dlta = [] t = 2 while t <= n: dlta.append(t-1) t *= 2 for i in range(len(dlta)-1,-1,-1): ShellInsert(lists,dlta[i])def ShellInsert(lists, k): for i in range(k): for j in range(i+k,len(lists),k): if lists[j] < lists[j-k]: value = lists[j] lists[j] = lists[j-k] m = j - k while m >= k and lists[m-k] > value: lists[m] = lists[m-k] m -= k lists[m] = value3. 选择排序
3.1 简单选择排序
基本思想: 寻找从i 到n的最小值,将最小值与i交换
def SelectSort(lists): n = len(lists) for i in range(n): minIndex = i for j in range(i+1,n): if lists[j] < lists[minIndex]: minIndex = j lists[i],lists[minIndex] = lists[minIndex],lists[i]3.2 堆排序
n个关键字序列Kl,K2,…,Kn称为(Heap),当且仅当该序列满足如下性质(简称为堆性质):ki<=k(2i)且ki<=k(2i+1)(1≤i≤ n/2),当然,这是小根堆,大根堆则换成>=号。k(i)相当于二叉树的非叶子结点,K(2i)则是左子节点,k(2i+1)是右子节点。
基本思想:首先对数组建大根堆,建堆通过对堆的调整实现,由于堆的调整建立在被调整的元素的下面的元素们满足堆的性质,因此建堆时从下向上调整。大根堆每次调整后堆顶的元素都是最大元素,将其与最后一个元素交换。
def HeapAdjust(lists, pos, end): value = lists[pos] cur = pos while cur < end//2: left = 2 * cur + 1 next_ = left right = left +1 if right < end and lists[right] > lists[next_]: next_ = right if lists[next_] <= value: break else: lists[cur] = lists[next_] cur = next_ lists[cur] = valuedef HeapSort(lists): for i in range(len(lists)//2-1,-1,-1): HeapAdjust(lists,i,len(lists)) for i in range(len(lists) -1,0,-1): lists[0],lists[i] = lists[i],lists[0] HeapAdjust(lists,0,i)对于大顶堆而言,只需保证非叶节点比它的2个孩子的值都大即可;对于堆这样的完全二叉树结构,设非叶节点个数为m,叶节点个数为n,根据分支数,有“2m - 1 = m + n - 1,或 2m = m + n-1”,因此非叶节点数等于叶节点数或比叶节点数少1;所以对于N个节点的堆,我们只需保证前N//2个节点满足性质即可。
4. 归并排序
4.1 二路归并
def Merge(lists,s1,e1,s2,e2): tmp = [] cur1, cur2 = s1, s2 while cur1 < e1 and cur2 < e2: if lists[cur1] <= lists[cur2]: tmp.append(lists[cur1]) cur1 += 1 else: tmp.append(lists[cur2]) cur2 += 1 cur ,e = (cur1,e1) if cur1 < e1 else (cur2,e2) while cur < e: tmp.append(lists[cur]) cur += 1 for i in range(len(tmp)): if s1 < e1: lists[s1] = tmp[i] s1 += 1 else: lists[s2] = tmp[i] s2 += 1def MSort(lists,start,end): if end - start < 2: return mid = (start + end) //2 MSort(lists,start,mid) MSort(lists,mid,end) Merge(lists,start,mid,mid,end)def MergeSort(lists): MSort(lists,0,len(lists))归并排序的时间复杂度可通过算法导论中的“递归树方法”求得。
(下面图片来源于:http://xwrwc.blog.163.com/blog/static/46320003201141582544245/) 
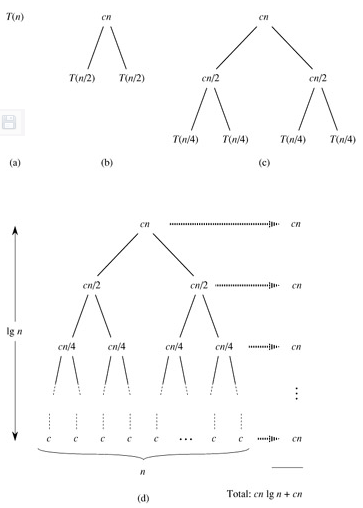
5. 线性时间排序
5.1 计数排序
假设:n个输入元素中的每一个元素都是介于0到k之间的整数。当k = O(n)时,计数排序的运行时间为
Θ (n).基本思想:对每一个输入元素x,确定出小于x的元素个数,就可以把x直接放到它在最终输出数组中的位置上。
注意:为了稳定排序,最后一个循环要从最大下标向前遍历;从0开始遍历也可进行正确排序,但是是非稳定排序。
代码1:
def CountingSort(lists): count = [0] * (max(lists) + 1) for i in range(len(lists)): count[lists[i]] += 1 for j in range(1,len(count)): count[j] += count[j-1] res = [0] * (len(lists) + 1) for i in range(len(lists)-1,-1,-1): count[lists[i]] -= 1 res[count[lists[i]]] = lists[i] # for j in range(len(lists)): # lists[j] = res[j] return res代码2:(不用使用res数组,但可能会运行的稍微慢些)
def CountingSort(lists): count = [0] * (max(lists) + 1) for i in range(len(lists)): count[lists[i]] += 1 index = 0 for m in range(len(count)): while(count[m] > 0): lists[index] = m index += 1 count[m] -= 15.2 基数排序(RadixSort)
原理:将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
实现:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
def RadixSort(lists,radix = 10): maxV = max(lists) d = 0 #d: number of digit while True: d += 1 maxV = maxV // 10 if maxV == 0: break; bucket = [[] for i in range(radix)] for i in range(1,d + 1): for val in lists: k = (val % (radix ** i))//(radix ** (i-1)) bucket[k].append(val) del lists[:] for val in bucket: lists.extend(val) bucket = [[] for i in range(radix)]一个错误版本(排序后lists的值不变):
def RadixSort(lists,radix = 10): maxV = max(lists) d = 0 # number of digit while True: d += 1 maxV = maxV // 10 if maxV == 0: break; for i in range(1,d + 1): bucket = [[] for i in range(radix)] for val in lists: k = (val % (radix ** i))//(radix ** (i-1)) bucket[k].append(val) del lists[:] for val in bucket: lists.extend(val)5.3 桶排序(BuckSort)
基本思想:假设输入是由一个随机过程产生的[0,1)区间上分布的实数。将区间[0, 1)划分为n个大小相等的子区间(桶),每桶大小1/n:[0, 1/n), [1/n, 2/n), [2/n, 3/n),…,[k/n, (k+1)/n), … 将n个输入元素分配到这些桶中 ,对桶中元素进行排序,然后将所有的桶中元素联系起来。
def BuckSort(A): n = len(A) bucket = [[] for j in range(n)] #allocate for i in range(n): bucket[int(n * A[i])].append(A[i]) #sort in the bucket for j in range(n): if len(bucket[j]) > 0: InsertSort(bucket[j]) #concatenate i = 0 del A[:] for values in bucket: A.extend(values)def InsertSort(lists): for i in range(1,len(lists)): value = lists[i] j = i - 1 while j >= 0 and lists[j] > value: lists[j+1] = lists[j] j -= 1 lists[j+1] = value时间复杂度:
T(n)=Θ(n)+∑n−1i=0O(n2i) .当输入符合均匀分布时,即可以以线性期望时间运行,即使输入不符合均匀分布,只要输入满足:各个桶尺寸的平方和与总的元素呈线性关系,那么仍然能一线性时间运行。
6.比较
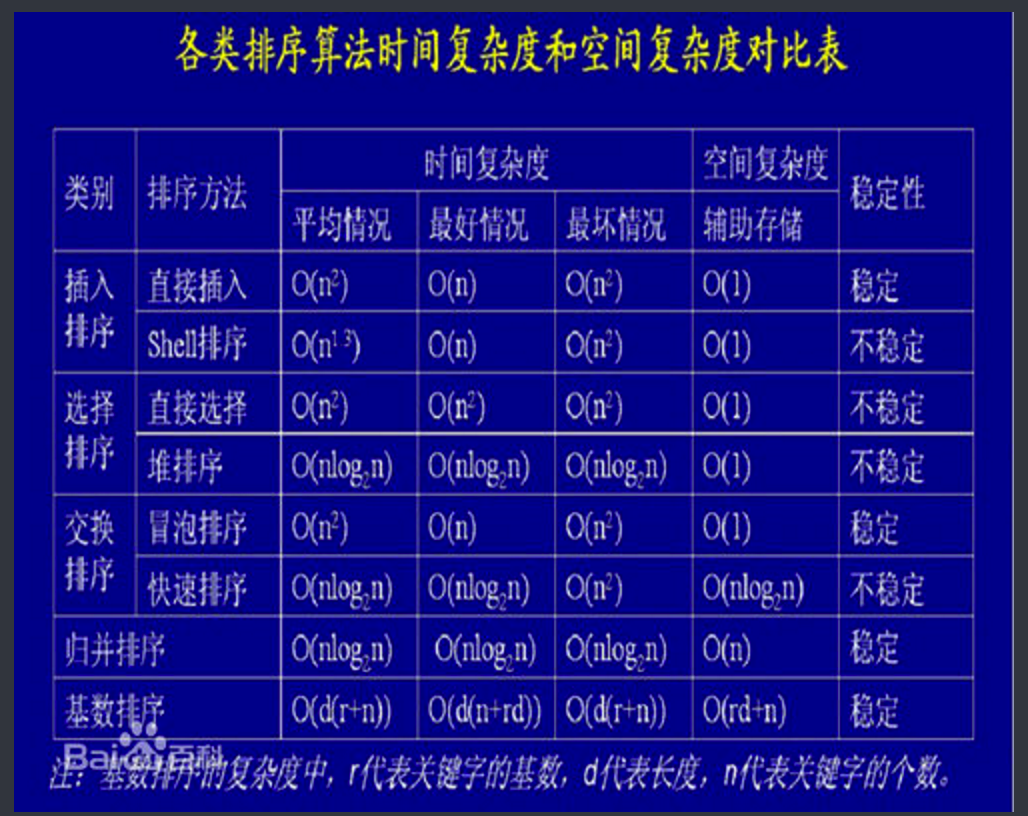
注意:快速排序的额外空间复杂度为递归调用中stack所需,在最坏情况下,需要n次嵌套,其所需空间为O(n)
- 排序算法一:内部排序算法Python实现
- 【排序】内部排序算法实现
- python实现排序算法一:快速排序
- Python实现经典内部排序算法(归并排序)
- 内部排序算法C++实现
- java实现内部排序算法
- 内部排序算法C++实现
- Python之快速排序算法实现(一)
- 排序算法python实现
- 排序算法Python实现
- Python实现排序算法
- 排序算法python实现
- 内部排序算法总结(use python)
- [算法 内部排序]冒泡排序
- 内部排序:冒泡排序算法
- 内部排序算法:插入排序
- 内部排序算法:归并排序
- 内部排序算法:堆排序
- 【已解决】Unable to start the daemon process
- Android 网络开源库-Retrofit(一)简单介绍
- Socket使用简明教程
- c++字符串分词
- 菜鸟数据
- 排序算法一:内部排序算法Python实现
- Android 软键盘遮挡PopupWindow解决办法
- 用法总结:NSNumber、NSString、NSDate、NSCalendarDate、NSData
- ZPL实例说明
- 从Java类库看设计模式(1)
- Java调试信息输出
- Xcode 蓝色文件夹和黄色文件夹的区别
- oracle和mysql mybatis批量更新
- Notification的理解及使用


