Stanford UFLDL教程 用反向传导思想求导
来源:互联网 发布:东莞信捷plc编程兼职 编辑:程序博客网 时间:2024/06/06 00:40
用反向传导思想求导
Contents
[hide]- 1简介
- 2示例
- 2.1示例1:稀疏编码中权重矩阵的目标函数
- 2.2示例2:稀疏编码中的平滑地形L1稀疏罚函数
- 2.3示例3:ICA重建代价
- 3中英文对照
- 4中文译者
简介
在 反向传导算法一节中,我们介绍了在稀疏自编码器中用反向传导算法来求梯度的方法。事实证明,反向传导算法与矩阵运算相结合的方法,对于计算复杂矩阵函数(从矩阵到实数的函数,或用符号表示为:从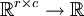 )的梯度是十分强大和直观的。
)的梯度是十分强大和直观的。
首先,我们回顾一下反向传导的思想,为了更适合我们的目的,将其稍作修改呈现于下:
- 对第 nl 层(最后一层)中的每一个输出单元i ,令
- 对
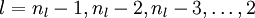 ,
,- 对第 l 层中的每个节点 i , 令
- 对第 l 层中的每个节点 i , 令
- 计算我们要的偏导数
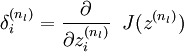
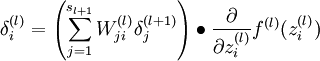
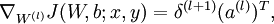
符号扼要重述:
- l 是神经网络的层数
- nl 第l层神经元的个数
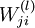 是l 层第i 个节点到第(l + 1) 层第j 个节点的权重
是l 层第i 个节点到第(l + 1) 层第j 个节点的权重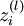 是第l 层第i 个单元的输入
是第l 层第i 个单元的输入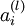 是第l 层第i 个节点的激励
是第l 层第i 个节点的激励 是矩阵的Hadamard积或逐个元素乘积,对
是矩阵的Hadamard积或逐个元素乘积,对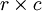 矩阵A 和 B ,它们的乘积是 矩阵
矩阵A 和 B ,它们的乘积是 矩阵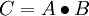 ,即
,即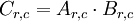
- f(l) 是第 l 层中各单元的激励函数
假设我们有一个函数 F , F 以矩阵X 为参数生成一个实数。我们希望用反向传导思想计算F 关于 X 的梯度,即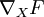 。大致思路是将函数F 看成一个多层神经网络,并使用反向传导思想求梯度。
。大致思路是将函数F 看成一个多层神经网络,并使用反向传导思想求梯度。
为了实现这个想法,我们取目标函数为 J(z) ,当计算最后一层神经元的输出时,会产生值F(X) 。对于中间层,我们将选择激励函数f(l) 。
稍后我们会看到,使用这种方法,我们可以很容易计算出对于输入 X 以及网络中任意一个权重的导数。
示例
为了阐述如何使用反向传导思想计算关于输入的导数,我们要在示例1,示例2中用 稀疏编码 章节中的两个函数。在示例3中,我们使用 独立成分分析一节中的一个函数来说明使用此思想计算关于权重的偏导的方法,以及在这种特殊情况下,如何处理相互捆绑或重复的权重。
示例1:稀疏编码中权重矩阵的目标函数
回顾一下 稀疏编码,当给定特征矩阵s 时,权重矩阵 A 的目标函数为:
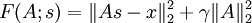
我们希望求 F 对于 A 的梯度,即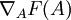 。因为目标函数是两个含A 的式子之和,所以它的梯度是每个式子的梯度之和。第二项的梯度很容易求,因此我们只考虑第一项的梯度。
。因为目标函数是两个含A 的式子之和,所以它的梯度是每个式子的梯度之和。第二项的梯度很容易求,因此我们只考虑第一项的梯度。
第一项, 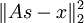 ,可以看成一个用s 做输入的神经网络的实例,通过四步进行计算,文字以及图形描述如下:
,可以看成一个用s 做输入的神经网络的实例,通过四步进行计算,文字以及图形描述如下:
- 把 A 作为第一层到第二层的权重。
- 将第二层的激励减 x ,第二层使用了单位激励函数。
- 通过单位权重将结果不变地传到第三层。在第三层使用平方函数作为激励函数。
- 将第三层的所有激励相加。
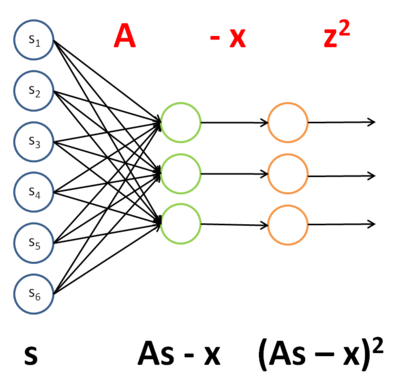
该网络的权重和激励函数如下表所示:
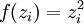
为了使 J(z(3)) = F(x) ,我们可令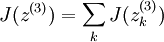 。
。
一旦我们将 F 看成神经网络,梯度 就很容易求了——使用反向传导得到:
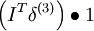 As1f'(zi) = 1
As1f'(zi) = 1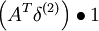 s
s
因此
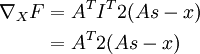
示例2:稀疏编码中的平滑地形L1稀疏罚函数
回顾 稀疏编码一节中对s 的平滑地形L1稀疏罚函数:
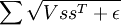
其中 V 是分组矩阵, s 是特征矩阵,ε 是一个常数。
我们希望求得 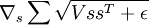 。像上面那样,我们把这一项看做一个神经网络的实例:
。像上面那样,我们把这一项看做一个神经网络的实例:

该网络的权重和激励函数如下表所示:
2Vf(zi) = zi3If(zi) = zi + ε4N/A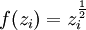
为使 J(z(4)) = F(x) ,我们可令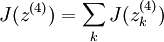 。
。
一旦我们把 F 看做一个神经网络,梯度 变得很容易计算——使用反向传导得到:
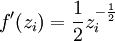 (VssT + ε)3f'(zi) = 1
(VssT + ε)3f'(zi) = 1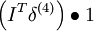 VssT2f'(zi) = 1
VssT2f'(zi) = 1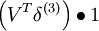 ssT1f'(zi) = 2zi
ssT1f'(zi) = 2zi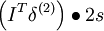 s
s
因此
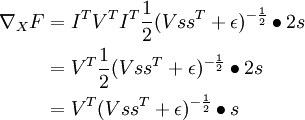
示例3:ICA重建代价
回顾 独立成分分析(ICA) 一节重建代价一项: 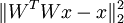 ,其中W 是权重矩阵,x 是输入。
,其中W 是权重矩阵,x 是输入。
我们希望计算 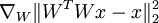 ——对于权重矩阵的导数,而不是像前两例中对于输入的导数。不过我们仍然用类似的方法处理,把该项看做一个神经网络的实例:
——对于权重矩阵的导数,而不是像前两例中对于输入的导数。不过我们仍然用类似的方法处理,把该项看做一个神经网络的实例:
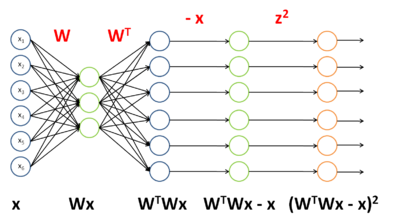
该网络的权重和激励函数如下表所示:
为使 J(z(4)) = F(x) ,我们可令 。
既然我们可将 F 看做神经网络,我们就能计算出梯度 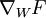 。然而,我们现在面临的难题是W 在网络中出现了两次。幸运的是,可以证明如果W 在网络中出现多次,那么对于 W 的梯度是对网络中每个W 实例的梯度的简单相加(你需要自己给出对这一事实的严格证明来说服自己)。知道这一点后,我们将首先计算delta:
。然而,我们现在面临的难题是W 在网络中出现了两次。幸运的是,可以证明如果W 在网络中出现多次,那么对于 W 的梯度是对网络中每个W 实例的梯度的简单相加(你需要自己给出对这一事实的严格证明来说服自己)。知道这一点后,我们将首先计算delta:
WTWx2f'(zi) = 1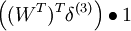 Wx1f'(zi) = 1
Wx1f'(zi) = 1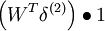 x
x为计算对于 W 的梯度,首先计算对网络中每个 W 实例的梯度。
对于 WT :
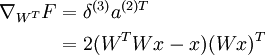
对于 W :
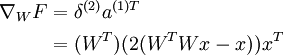
最后进行求和,得到对于 W 的最终梯度,注意我们需要对 WT 梯度进行转置,来得到关于 W 的梯度(原谅我在这里稍稍滥用了符号):
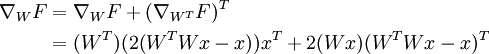
中英文对照
- 反向传导 backpropagation
- 稀疏编码 sparse coding
- 权重矩阵 weight matrix
- 目标函数 objective
- 平滑地形L1稀疏罚函数 Smoothed topographic L1 sparsity penalty
- 重建代价 reconstruction cost
- 稀疏自编码器 sparse autoencoder
- 梯度 gradient
- 神经网络 neural network
- 神经元 neuron
- 激励 activation
- 激励函数 activation function
- 独立成分分析 independent component analysis
- 单位激励函数 identity activation function
- 平方函数 square function
- 分组矩阵 grouping matrix
- 特征矩阵 feature matrix
- Stanford UFLDL教程 用反向传导思想求导
- 反向传导算法及用反向传导思想求导
- UFLDL 教程学习笔记(二)反向传导算法
- UFLDL 教程学习笔记(二)反向传导算法
- UFLDL 教程学习笔记(二)反向传导算法
- Stanford UFLDL教程 反向传播算法(BP算法)
- Stanford UFLDL教程 白化
- Stanford UFLDL教程 池化Pooling
- Stanford UFLDL教程 Exercise:Vectorization
- Stanford UFLDL教程 Softmax回归
- Stanford UFLDL教程 自我学习
- Stanford UFLDL教程 线性解码器
- Stanford UFLDL教程 MATLAB Modules
- Stanford UFLDL教程 数据预处理
- Stanford UFLDL教程 稀疏编码
- Stanford UFLDL教程 Exercise:Sparse Autoencoder
- Stanford UFLDL教程 矢量化编程
- Stanford UFLDL教程 神经网络向量化
- cocos2d-x学习笔记(7)MoveTo和MoveBy
- 使用connect by进行级联查询
- 自定义NavigationBar按钮
- VC++回顾----多线程
- 修改phpmyadmin密码后,weiphp后台一直无法登录,post not found
- Stanford UFLDL教程 用反向传导思想求导
- CSAPP——实验一 位运算
- Dialog 之AlertDialog(单选,多选,提示)
- UI 17 异步加载图片 KVO
- iOS XML解析方式
- PAT甲级(Advance Level)冬季考试总结20151205
- IBM SPSS Modeler 14.1安装
- Stanford UFLDL教程 稀疏编码
- HDU-1754I Hate It 线段树区间最值


