(数据挖掘-入门-6)十折交叉验证和K近邻
来源:互联网 发布:java杨辉三角几年里 编辑:程序博客网 时间:2024/05/21 22:23
主要内容:
1、十折交叉验证
2、混淆矩阵
3、K近邻
4、python实现
一、十折交叉验证
前面提到了数据集分为训练集和测试集,训练集用来训练模型,而测试集用来测试模型的好坏,那么单一的测试是否就能很好的衡量一个模型的性能呢?
答案自然是否定的,单一的测试集具有偶然性和随机性。因此本文介绍一种衡量模型(比如分类器)性能的方法——十折交叉验证(10-fold cross validation)
什么是十折交叉验证?
假设有个数据集,需要建立一个分类器,如何验证分类器的性能呢?
将数据集随机均为为10份,依次选择某1份作为测试集,其他9份作为训练集,训练出来的模型对测试集进行分类,并统计分类结果,就这样,重复10次实验,综合所有分类结果,就可以得到比较稳定的评价结果(当然,由于是随机划分数据集,因此每次运行结果都不一致)。
附:当然也可以选择k折交叉验证,最极端的就是留1交叉验证,每次只留一个样本做测试集,但这样的计算规模太大。
二、混淆矩阵
混淆矩阵:confuse matrix
假设有n个类别,那么分类结果的统计可以通过一个n*n的矩阵来表示,即混淆矩阵。
对角线即为分类正确的样本数。
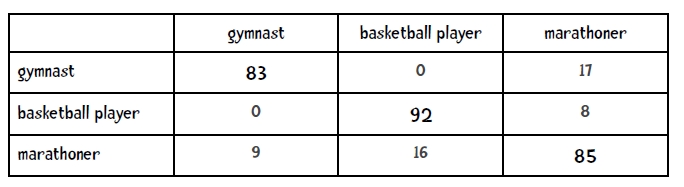
三、K近邻(KNN)
在协同过滤中已经提到过K近邻,就是选择离某个样本最近的K个样本,根据该K个样本来决定此样本的数值或类别。
如果是连续数值,那么K近邻可以作为回归方法,通过K个样本的矩阵权重来拟合数值;
如果是离散数值,那么K近邻可以作为分类方法,通过K个样本的多数投票策略来决定类别;
四、python实现
数据集:
mpgData.zip
pimaSmall.zip
pima.zip
代码:
1、切分数据


# divide data into 10 bucketsimport randomdef buckets(filename, bucketName, separator, classColumn): """the original data is in the file named filename bucketName is the prefix for all the bucket names separator is the character that divides the columns (for ex., a tab or comma and classColumn is the column that indicates the class""" # put the data in 10 buckets numberOfBuckets = 10 data = {} # first read in the data and divide by category with open(filename) as f: lines = f.readlines() for line in lines: if separator != '\t': line = line.replace(separator, '\t') # first get the category category = line.split()[classColumn] data.setdefault(category, []) data[category].append(line) # initialize the buckets buckets = [] for i in range(numberOfBuckets): buckets.append([]) # now for each category put the data into the buckets for k in data.keys(): #randomize order of instances for each class random.shuffle(data[k]) bNum = 0 # divide into buckets for item in data[k]: buckets[bNum].append(item) bNum = (bNum + 1) % numberOfBuckets # write to file for bNum in range(numberOfBuckets): f = open("%s-%02i" % (bucketName, bNum + 1), 'w') for item in buckets[bNum]: f.write(item) f.close()# example of how to use this code buckets("pimaSmall.txt", 'pimaSmall',',',8)
2、十折交叉验证
# # # Nearest Neighbor Classifier for mpg dataset #class Classifier: def __init__(self, bucketPrefix, testBucketNumber, dataFormat): """ a classifier will be built from files with the bucketPrefix excluding the file with textBucketNumber. dataFormat is a string that describes how to interpret each line of the data files. For example, for the mpg data the format is: "class num num num num num comment" """ self.medianAndDeviation = [] # reading the data in from the file self.format = dataFormat.strip().split('\t') self.data = [] # for each of the buckets numbered 1 through 10: for i in range(1, 11): # if it is not the bucket we should ignore, read in the data if i != testBucketNumber: filename = "%s-%02i" % (bucketPrefix, i) f = open(filename) lines = f.readlines() f.close() for line in lines[1:]: fields = line.strip().split('\t') ignore = [] vector = [] for i in range(len(fields)): if self.format[i] == 'num': vector.append(float(fields[i])) elif self.format[i] == 'comment': ignore.append(fields[i]) elif self.format[i] == 'class': classification = fields[i] self.data.append((classification, vector, ignore)) self.rawData = list(self.data) # get length of instance vector self.vlen = len(self.data[0][1]) # now normalize the data for i in range(self.vlen): self.normalizeColumn(i) ################################################## ### ### CODE TO COMPUTE THE MODIFIED STANDARD SCORE def getMedian(self, alist): """return median of alist""" if alist == []: return [] blist = sorted(alist) length = len(alist) if length % 2 == 1: # length of list is odd so return middle element return blist[int(((length + 1) / 2) - 1)] else: # length of list is even so compute midpoint v1 = blist[int(length / 2)] v2 =blist[(int(length / 2) - 1)] return (v1 + v2) / 2.0 def getAbsoluteStandardDeviation(self, alist, median): """given alist and median return absolute standard deviation""" sum = 0 for item in alist: sum += abs(item - median) return sum / len(alist) def normalizeColumn(self, columnNumber): """given a column number, normalize that column in self.data""" # first extract values to list col = [v[1][columnNumber] for v in self.data] median = self.getMedian(col) asd = self.getAbsoluteStandardDeviation(col, median) #print("Median: %f ASD = %f" % (median, asd)) self.medianAndDeviation.append((median, asd)) for v in self.data: v[1][columnNumber] = (v[1][columnNumber] - median) / asd def normalizeVector(self, v): """We have stored the median and asd for each column. We now use them to normalize vector v""" vector = list(v) for i in range(len(vector)): (median, asd) = self.medianAndDeviation[i] vector[i] = (vector[i] - median) / asd return vector ### ### END NORMALIZATION ################################################## def testBucket(self, bucketPrefix, bucketNumber): """Evaluate the classifier with data from the file bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber) f = open(filename) lines = f.readlines() totals = {} f.close() for line in lines: data = line.strip().split('\t') vector = [] classInColumn = -1 for i in range(len(self.format)): if self.format[i] == 'num': vector.append(float(data[i])) elif self.format[i] == 'class': classInColumn = i theRealClass = data[classInColumn] classifiedAs = self.classify(vector) totals.setdefault(theRealClass, {}) totals[theRealClass].setdefault(classifiedAs, 0) totals[theRealClass][classifiedAs] += 1 return totals def manhattan(self, vector1, vector2): """Computes the Manhattan distance.""" return sum(map(lambda v1, v2: abs(v1 - v2), vector1, vector2)) def nearestNeighbor(self, itemVector): """return nearest neighbor to itemVector""" return min([ (self.manhattan(itemVector, item[1]), item) for item in self.data]) def classify(self, itemVector): """Return class we think item Vector is in""" return(self.nearestNeighbor(self.normalizeVector(itemVector))[1][0]) def tenfold(bucketPrefix, dataFormat): results = {} for i in range(1, 11): c = Classifier(bucketPrefix, i, dataFormat) t = c.testBucket(bucketPrefix, i) for (key, value) in t.items(): results.setdefault(key, {}) for (ckey, cvalue) in value.items(): results[key].setdefault(ckey, 0) results[key][ckey] += cvalue # now print results categories = list(results.keys()) categories.sort() print( "\n Classified as: ") header = " " subheader = " +" for category in categories: header += category + " " subheader += "----+" print (header) print (subheader) total = 0.0 correct = 0.0 for category in categories: row = category + " |" for c2 in categories: if c2 in results[category]: count = results[category][c2] else: count = 0 row += " %2i |" % count total += count if c2 == category: correct += count print(row) print(subheader) print("\n%5.3f percent correct" %((correct * 100) / total)) print("total of %i instances" % total)tenfold("mpgData/mpgData/mpgData", "class num num num num num comment")
3、K近邻
# # K Nearest Neighbor Classifier for Pima dataset#import heapqimport randomclass Classifier: def __init__(self, bucketPrefix, testBucketNumber, dataFormat, k): """ a classifier will be built from files with the bucketPrefix excluding the file with textBucketNumber. dataFormat is a string that describes how to interpret each line of the data files. For example, for the mpg data the format is: "class num num num num num comment" """ self.medianAndDeviation = [] self.k = k # reading the data in from the file self.format = dataFormat.strip().split('\t') self.data = [] # for each of the buckets numbered 1 through 10: for i in range(1, 11): # if it is not the bucket we should ignore, read in the data if i != testBucketNumber: filename = "%s-%02i" % (bucketPrefix, i) f = open(filename) lines = f.readlines() f.close() for line in lines[1:]: fields = line.strip().split('\t') ignore = [] vector = [] for i in range(len(fields)): if self.format[i] == 'num': vector.append(float(fields[i])) elif self.format[i] == 'comment': ignore.append(fields[i]) elif self.format[i] == 'class': classification = fields[i] self.data.append((classification, vector, ignore)) self.rawData = list(self.data) # get length of instance vector self.vlen = len(self.data[0][1]) # now normalize the data for i in range(self.vlen): self.normalizeColumn(i) ################################################## ### ### CODE TO COMPUTE THE MODIFIED STANDARD SCORE def getMedian(self, alist): """return median of alist""" if alist == []: return [] blist = sorted(alist) length = len(alist) if length % 2 == 1: # length of list is odd so return middle element return blist[int(((length + 1) / 2) - 1)] else: # length of list is even so compute midpoint v1 = blist[int(length / 2)] v2 =blist[(int(length / 2) - 1)] return (v1 + v2) / 2.0 def getAbsoluteStandardDeviation(self, alist, median): """given alist and median return absolute standard deviation""" sum = 0 for item in alist: sum += abs(item - median) return sum / len(alist) def normalizeColumn(self, columnNumber): """given a column number, normalize that column in self.data""" # first extract values to list col = [v[1][columnNumber] for v in self.data] median = self.getMedian(col) asd = self.getAbsoluteStandardDeviation(col, median) #print("Median: %f ASD = %f" % (median, asd)) self.medianAndDeviation.append((median, asd)) for v in self.data: v[1][columnNumber] = (v[1][columnNumber] - median) / asd def normalizeVector(self, v): """We have stored the median and asd for each column. We now use them to normalize vector v""" vector = list(v) for i in range(len(vector)): (median, asd) = self.medianAndDeviation[i] vector[i] = (vector[i] - median) / asd return vector ### ### END NORMALIZATION ################################################## def testBucket(self, bucketPrefix, bucketNumber): """Evaluate the classifier with data from the file bucketPrefix-bucketNumber""" filename = "%s-%02i" % (bucketPrefix, bucketNumber) f = open(filename) lines = f.readlines() totals = {} f.close() for line in lines: data = line.strip().split('\t') vector = [] classInColumn = -1 for i in range(len(self.format)): if self.format[i] == 'num': vector.append(float(data[i])) elif self.format[i] == 'class': classInColumn = i theRealClass = data[classInColumn] #print("REAL ", theRealClass) classifiedAs = self.classify(vector) totals.setdefault(theRealClass, {}) totals[theRealClass].setdefault(classifiedAs, 0) totals[theRealClass][classifiedAs] += 1 return totals def manhattan(self, vector1, vector2): """Computes the Manhattan distance.""" return sum(map(lambda v1, v2: abs(v1 - v2), vector1, vector2)) def nearestNeighbor(self, itemVector): """return nearest neighbor to itemVector""" return min([ (self.manhattan(itemVector, item[1]), item) for item in self.data]) def knn(self, itemVector): """returns the predicted class of itemVector using k Nearest Neighbors""" # changed from min to heapq.nsmallest to get the # k closest neighbors neighbors = heapq.nsmallest(self.k, [(self.manhattan(itemVector, item[1]), item) for item in self.data]) # each neighbor gets a vote results = {} for neighbor in neighbors: theClass = neighbor[1][0] results.setdefault(theClass, 0) results[theClass] += 1 resultList = sorted([(i[1], i[0]) for i in results.items()], reverse=True) #get all the classes that have the maximum votes maxVotes = resultList[0][0] possibleAnswers = [i[1] for i in resultList if i[0] == maxVotes] # randomly select one of the classes that received the max votes answer = random.choice(possibleAnswers) return( answer) def classify(self, itemVector): """Return class we think item Vector is in""" # k represents how many nearest neighbors to use return(self.knn(self.normalizeVector(itemVector))) def tenfold(bucketPrefix, dataFormat, k): results = {} for i in range(1, 11): c = Classifier(bucketPrefix, i, dataFormat, k) t = c.testBucket(bucketPrefix, i) for (key, value) in t.items(): results.setdefault(key, {}) for (ckey, cvalue) in value.items(): results[key].setdefault(ckey, 0) results[key][ckey] += cvalue # now print results categories = list(results.keys()) categories.sort() print( "\n Classified as: ") header = " " subheader = " +" for category in categories: header += "% 2s " % category subheader += "-----+" print (header) print (subheader) total = 0.0 correct = 0.0 for category in categories: row = " %s |" % category for c2 in categories: if c2 in results[category]: count = results[category][c2] else: count = 0 row += " %3i |" % count total += count if c2 == category: correct += count print(row) print(subheader) print("\n%5.3f percent correct" %((correct * 100) / total)) print("total of %i instances" % total)print("SMALL DATA SET")tenfold("pimaSmall/pimaSmall/pimaSmall", "num num num num num num num num class", 3)print("\n\nLARGE DATA SET")tenfold("pima/pima/pima", "num num num num num num num num class", 3)
1 0
- (数据挖掘-入门-6)十折交叉验证和K近邻
- 数据挖掘:K近邻
- 数据挖掘十大算法--K近邻算法
- 数据挖掘十大经典算法之一:K近邻
- 数据挖掘5-K近邻
- (数据挖掘-入门-3)基于用户的协同过滤之k近邻
- 数据挖掘10大算法(6)-K最近邻(KNN)算法的实现(java和python版)
- 数据挖掘10大算法(6)--K近邻算法
- 数据挖掘算法(一)--K近邻算法 (KNN)
- 数据挖掘---分类算法之K近邻(KNN)算法
- 数据挖掘十大经典算法之K最近邻算法
- 机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
- 十折交叉验证和混淆矩阵
- K-折交叉验证
- K折交叉验证
- k折交叉验证
- k-折交叉验证
- K折交叉验证
- 【LEETCODE】20-Valid Parentheses
- 第十五周 项目1 插入排序
- 配置NGINX的ACCESS LOG
- 第12周项目1图基本算法库
- strtotime小笔记
- (数据挖掘-入门-6)十折交叉验证和K近邻
- 第十三周 Floyd 算法
- 第16周 项目1-交换排序之冒泡排序
- 自定义属性
- 用matlab给图像分块并保存子图
- (第十六周项目3)归并排序算法的改进
- 第十二周项目2-操作用邻接表存储的图
- 第14周项目1-(1)验证折半查找算法
- [ERROR] The goal you specified requires a project to execute but there is no POM in this directory


