数据挖掘-聚类-K-means算法Java实现
来源:互联网 发布:网络空间安全 研讨会 编辑:程序博客网 时间:2024/06/05 05:32
K-Means算法是最古老也是应用最广泛的聚类算法,它使用质心定义原型,质心是一组点的均值,通常该算法用于n维连续空间中的对象。
K-Means算法流程
step1:选择K个点作为初始质心
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
我们对每一个步骤都进行分析
step1:选择K个点作为初始质心
这一步首先要知道K的值,也就是说K是手动设置的,而不是像EM算法那样自动聚类成n个簇
其次,如何选择初始质心
最简单的方式无异于,随机选取质心了,然后多次运行,取效果最好的那个结果。这个方法,简单但不见得有效,有很大的可能是得到局部最优。
另一种复杂的方式是,随机选取一个质心,然后计算离这个质心最远的样本点,对于每个后继质心都选取已经选取过的质心的最远点。使用这种方式,可以确保质心是随机的,并且是散开的。
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
如何定义最近的概念,对于欧式空间中的点,可以使用欧式空间,对于文档可以用余弦相似性等等。对于给定的数据,可能适应与多种合适的邻近性度量。
其他问题
离群点的处理
离群点可能过度影响簇的发现,导致簇的最终发布会与我们的预想有较大出入,所以提前发现并剔除离群点是有必要的。
在我的工作中,是利用方差来剔除离群点,结果显示效果非常好。
簇分裂和簇合并
使用较大的K,往往会使得聚类的结果看上去更加合理,但很多情况下,我们并不想增加簇的个数。
这时可以交替采用簇分裂和簇合并。这种方式可以避开局部极小,并且能够得到具有期望个数簇的结果。
抽象了点,簇,和距离
Point.class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
publicclass Point { privatedouble x; privatedouble y; privateint id; privateboolean beyond;//标识是否属于样本 publicPoint(intid, doublex, doubley) { this.id = id; this.x = x; this.y = y; this.beyond = true; } publicPoint(intid, doublex, doubley, booleanbeyond) { this.id = id; this.x = x; this.y = y; this.beyond = beyond; } publicdouble getX() { returnx; } publicdouble getY() { returny; } publicint getId() { returnid; } publicboolean isBeyond() { returnbeyond; } @Override publicString toString() { return"Point{" + "id="+ id + ", x=" + x + ", y=" + y + '}'; } @Override publicboolean equals(Object o) { if(this== o) returntrue; if(o == null|| getClass() != o.getClass()) returnfalse; Point point = (Point) o; if(Double.compare(point.x, x) != 0)returnfalse; if(Double.compare(point.y, y) != 0)returnfalse; returntrue; } @Override publicint hashCode() { intresult; longtemp; temp = x != +0.0d ? Double.doubleToLongBits(x) : 0L; result = (int) (temp ^ (temp >>> 32)); temp = y != +0.0d ? Double.doubleToLongBits(y) : 0L; result = 31* result + (int) (temp ^ (temp >>> 32)); returnresult; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
publicclass Cluster { privateint id;//标识 privatePoint center;//中心 privateList<Point> members = newArrayList<Point>();//成员 publicCluster(intid, Point center) { this.id = id; this.center = center; } publicCluster(intid, Point center, List<Point> members) { this.id = id; this.center = center; this.members = members; } publicvoid addPoint(Point newPoint) { if(!members.contains(newPoint)) members.add(newPoint); else thrownew IllegalStateException("试图处理同一个样本数据!"); } publicint getId() { returnid; } publicPoint getCenter() { returncenter; } publicvoid setCenter(Point center) { this.center = center; } publicList<Point> getMembers() { returnmembers; } @Override publicString toString() { return"Cluster{" + "id="+ id + ", center=" + center + ", members=" + members + "}"; } }1
2
3
publicabstract class AbstractDistance { abstractpublic double getDis(Point p1, Point p2); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
publicclass Distence implementsComparable<Distence> { privatePoint source; privatePoint dest; privatedouble dis; privateAbstractDistance distance; publicDistence(Point source, Point dest, AbstractDistance distance) { this.source = source; this.dest = dest; this.distance = distance; dis = distance.getDis(source, dest); } publicPoint getSource() { returnsource; } publicPoint getDest() { returndest; } publicdouble getDis() { returndis; } @Override publicint compareTo(Distence o) { if(o.getDis() > dis) return-1; else return1; } }核心实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
publicclass KMeansCluster { privateint k;//簇的个数 privateint num = 100000;//迭代次数 privateList<Double> datas;//原始样本集 privateString address;//样本集路径 privateList<Point> data = newArrayList<Point>(); privateAbstractDistance distance = newAbstractDistance() { @Override publicdouble getDis(Point p1, Point p2) { //欧几里德距离 returnMath.sqrt(Math.pow(p1.getX() - p2.getX(), 2) + Math.pow(p1.getY() - p2.getY(), 2)); } }; publicKMeansCluster(intk, intnum, String address) { this.k = k; this.num = num; this.address = address; } publicKMeansCluster(intk, String address) { this.k = k; this.address = address; } publicKMeansCluster(intk, List<Double> datas) { this.k = k; this.datas = datas; } publicKMeansCluster(intk, intnum, List<Double> datas) { this.k = k; this.num = num; this.datas = datas; } privatevoid check() { if(k == 0) thrownew IllegalArgumentException("k must be the number > 0"); if(address == null&& datas == null) thrownew IllegalArgumentException("program can't get real data"); } /** * 初始化数据 * * @throws java.io.FileNotFoundException */ publicvoid init() throwsFileNotFoundException { check(); //读取文件,init data //处理原始数据 for(inti = 0, j = datas.size(); i < j; i++) data.add(newPoint(i, datas.get(i), 0)); } /** * 第一次随机选取中心点 * * @return */ publicSet<Point> chooseCenter() { Set<Point> center = newHashSet<Point>(); Random ran = newRandom(); introll = 0; while(center.size() < k) { roll = ran.nextInt(data.size()); center.add(data.get(roll)); } returncenter; } /** * @param center * @return */ publicList<Cluster> prepare(Set<Point> center) { List<Cluster> cluster = newArrayList<Cluster>(); Iterator<Point> it = center.iterator(); intid = 0; while(it.hasNext()) { Point p = it.next(); if(p.isBeyond()) { Cluster c = newCluster(id++, p); c.addPoint(p); cluster.add(c); }else cluster.add(newCluster(id++, p)); } returncluster; } /** * 第一次运算,中心点为样本值 * * @param center * @param cluster * @return */ publicList<Cluster> clustering(Set<Point> center, List<Cluster> cluster) { Point[] p = center.toArray(newPoint[0]); TreeSet<Distence> distence = newTreeSet<Distence>();//存放距离信息 Point source; Point dest; booleanflag = false; for(inti = 0, n = data.size(); i < n; i++) { distence.clear(); for(intj = 0; j < center.size(); j++) { if(center.contains(data.get(i))) break; flag = true; // 计算距离 source = data.get(i); dest = p[j]; distence.add(newDistence(source, dest, distance)); } if(flag == true) { Distence min = distence.first(); for(intm = 0, k = cluster.size(); m < k; m++) { if(cluster.get(m).getCenter().equals(min.getDest())) cluster.get(m).addPoint(min.getSource()); } } flag = false; } returncluster; } /** * 迭代运算,中心点为簇内样本均值 * * @param cluster * @return */ publicList<Cluster> cluster(List<Cluster> cluster) { // double error; Set<Point> lastCenter = newHashSet<Point>(); for(intm = 0; m < num; m++) { // error = 0; Set<Point> center = newHashSet<Point>(); // 重新计算聚类中心 for(intj = 0; j < k; j++) { List<Point> ps = cluster.get(j).getMembers(); intsize = ps.size(); if(size < 3) { center.add(cluster.get(j).getCenter()); continue; } // 计算距离 doublex = 0.0, y = 0.0; for(intk1 = 0; k1 < size; k1++) { x += ps.get(k1).getX(); y += ps.get(k1).getY(); } //得到新的中心点 Point nc = newPoint(-1, x / size, y / size, false); center.add(nc); } if(lastCenter.containsAll(center))//中心点不在变化,退出迭代 break; lastCenter = center; // 迭代运算 cluster = clustering(center, prepare(center)); // for (int nz = 0; nz < k; nz++) { // error += cluster.get(nz).getError();//计算误差 // } } returncluster; } /** * 输出聚类信息到控制台 * * @param cs */ publicvoid out2console(List<Cluster> cs) { for(inti = 0; i < cs.size(); i++) { System.out.println("No."+ (i + 1) + " cluster:"); Cluster c = cs.get(i); List<Point> p = c.getMembers(); for(intj = 0; j < p.size(); j++) { System.out.println("\t"+ p.get(j).getX() + " "); } System.out.println(); } } }K-Means算法是最古老也是应用最广泛的聚类算法,它使用质心定义原型,质心是一组点的均值,通常该算法用于n维连续空间中的对象。
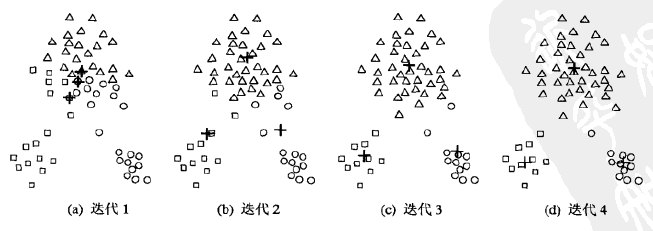
例如下图的样本集,初始选择是三个质心比较集中,但是迭代3次之后,质心趋于稳定,并将样本集分为3部分
贴上代码java版,以后有时间写个python版的
抽象了点,簇,和距离
Point.class
Cluster.class
抽象的距离,可以具体实现为欧式,曼式或其他距离公式
点对
代码还没有仔细优化,执行的效率可能还存在一定的问题
K-Means算法流程
step1:选择K个点作为初始质心
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
我们对每一个步骤都进行分析
step1:选择K个点作为初始质心
这一步首先要知道K的值,也就是说K是手动设置的,而不是像EM算法那样自动聚类成n个簇
其次,如何选择初始质心
最简单的方式无异于,随机选取质心了,然后多次运行,取效果最好的那个结果。这个方法,简单但不见得有效,有很大的可能是得到局部最优。
另一种复杂的方式是,随机选取一个质心,然后计算离这个质心最远的样本点,对于每个后继质心都选取已经选取过的质心的最远点。使用这种方式,可以确保质心是随机的,并且是散开的。
step2:repeat
将每个点指派到最近的质心,形成K个簇
重新计算每个簇的质心
until 质心不在变化
如何定义最近的概念,对于欧式空间中的点,可以使用欧式空间,对于文档可以用余弦相似性等等。对于给定的数据,可能适应与多种合适的邻近性度量。
其他问题
离群点的处理
离群点可能过度影响簇的发现,导致簇的最终发布会与我们的预想有较大出入,所以提前发现并剔除离群点是有必要的。
在我的工作中,是利用方差来剔除离群点,结果显示效果非常好。
簇分裂和簇合并
使用较大的K,往往会使得聚类的结果看上去更加合理,但很多情况下,我们并不想增加簇的个数。
这时可以交替采用簇分裂和簇合并。这种方式可以避开局部极小,并且能够得到具有期望个数簇的结果。
抽象了点,簇,和距离
Point.class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
publicclass Point { privatedouble x; privatedouble y; privateint id; privateboolean beyond;//标识是否属于样本 publicPoint(intid, doublex, doubley) { this.id = id; this.x = x; this.y = y; this.beyond = true; } publicPoint(intid, doublex, doubley, booleanbeyond) { this.id = id; this.x = x; this.y = y; this.beyond = beyond; } publicdouble getX() { returnx; } publicdouble getY() { returny; } publicint getId() { returnid; } publicboolean isBeyond() { returnbeyond; } @Override publicString toString() { return"Point{" + "id="+ id + ", x=" + x + ", y=" + y + '}'; } @Override publicboolean equals(Object o) { if(this== o) returntrue; if(o == null|| getClass() != o.getClass()) returnfalse; Point point = (Point) o; if(Double.compare(point.x, x) != 0)returnfalse; if(Double.compare(point.y, y) != 0)returnfalse; returntrue; } @Override publicint hashCode() { intresult; longtemp; temp = x != +0.0d ? Double.doubleToLongBits(x) : 0L; result = (int) (temp ^ (temp >>> 32)); temp = y != +0.0d ? Double.doubleToLongBits(y) : 0L; result = 31* result + (int) (temp ^ (temp >>> 32)); returnresult; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
publicclass Cluster { privateint id;//标识 privatePoint center;//中心 privateList<Point> members = newArrayList<Point>();//成员 publicCluster(intid, Point center) { this.id = id; this.center = center; } publicCluster(intid, Point center, List<Point> members) { this.id = id; this.center = center; this.members = members; } publicvoid addPoint(Point newPoint) { if(!members.contains(newPoint)) members.add(newPoint); else thrownew IllegalStateException("试图处理同一个样本数据!"); } publicint getId() { returnid; } publicPoint getCenter() { returncenter; } publicvoid setCenter(Point center) { this.center = center; } publicList<Point> getMembers() { returnmembers; } @Override publicString toString() { return"Cluster{" + "id="+ id + ", center=" + center + ", members=" + members + "}"; } }1
2
3
publicabstract class AbstractDistance { abstractpublic double getDis(Point p1, Point p2); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
publicclass Distence implementsComparable<Distence> { privatePoint source; privatePoint dest; privatedouble dis; privateAbstractDistance distance; publicDistence(Point source, Point dest, AbstractDistance distance) { this.source = source; this.dest = dest; this.distance = distance; dis = distance.getDis(source, dest); } publicPoint getSource() { returnsource; } publicPoint getDest() { returndest; } publicdouble getDis() { returndis; } @Override publicint compareTo(Distence o) { if(o.getDis() > dis) return-1; else return1; } }核心实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
publicclass KMeansCluster { privateint k;//簇的个数 privateint num = 100000;//迭代次数 privateList<Double> datas;//原始样本集 privateString address;//样本集路径 privateList<Point> data = newArrayList<Point>(); privateAbstractDistance distance = newAbstractDistance() { @Override publicdouble getDis(Point p1, Point p2) { //欧几里德距离 returnMath.sqrt(Math.pow(p1.getX() - p2.getX(), 2) + Math.pow(p1.getY() - p2.getY(), 2)); } }; publicKMeansCluster(intk, intnum, String address) { this.k = k; this.num = num; this.address = address; } publicKMeansCluster(intk, String address) { this.k = k; this.address = address; } publicKMeansCluster(intk, List<Double> datas) { this.k = k; this.datas = datas; } publicKMeansCluster(intk, intnum, List<Double> datas) { this.k = k; this.num = num; this.datas = datas; } privatevoid check() { if(k == 0) thrownew IllegalArgumentException("k must be the number > 0"); if(address == null&& datas == null) thrownew IllegalArgumentException("program can't get real data"); } /** * 初始化数据 * * @throws java.io.FileNotFoundException */ publicvoid init() throwsFileNotFoundException { check(); //读取文件,init data //处理原始数据 for(inti = 0, j = datas.size(); i < j; i++) data.add(newPoint(i, datas.get(i), 0)); } /** * 第一次随机选取中心点 * * @return */ publicSet<Point> chooseCenter() { Set<Point> center = newHashSet<Point>(); Random ran = newRandom(); introll = 0; while(center.size() < k) { roll = ran.nextInt(data.size()); center.add(data.get(roll)); } returncenter; } /** * @param center * @return */ publicList<Cluster> prepare(Set<Point> center) { List<Cluster> cluster = newArrayList<Cluster>(); Iterator<Point> it = center.iterator(); intid = 0; while(it.hasNext()) { Point p = it.next(); if(p.isBeyond()) { Cluster c = newCluster(id++, p); c.addPoint(p); cluster.add(c); }else cluster.add(newCluster(id++, p)); } returncluster; } /** * 第一次运算,中心点为样本值 * * @param center * @param cluster * @return */ publicList<Cluster> clustering(Set<Point> center, List<Cluster> cluster) { Point[] p = center.toArray(newPoint[0]); TreeSet<Distence> distence = newTreeSet<Distence>();//存放距离信息 Point source; Point dest; booleanflag = false; for(inti = 0, n = data.size(); i < n; i++) { distence.clear(); for(intj = 0; j < center.size(); j++) { if(center.contains(data.get(i))) break; flag = true; // 计算距离 source = data.get(i); dest = p[j]; distence.add(newDistence(source, dest, distance)); } if(flag == true) { Distence min = distence.first(); for(intm = 0, k = cluster.size(); m < k; m++) { if(cluster.get(m).getCenter().equals(min.getDest())) cluster.get(m).addPoint(min.getSource()); } } flag = false; } returncluster; } /** * 迭代运算,中心点为簇内样本均值 * * @param cluster * @return */ publicList<Cluster> cluster(List<Cluster> cluster) { // double error; Set<Point> lastCenter = newHashSet<Point>(); for(intm = 0; m < num; m++) { // error = 0; Set<Point> center = newHashSet<Point>(); // 重新计算聚类中心 for(intj = 0; j < k; j++) { List<Point> ps = cluster.get(j).getMembers(); intsize = ps.size(); if(size < 3) { center.add(cluster.get(j).getCenter()); continue; } // 计算距离 doublex = 0.0, y = 0.0; for(intk1 = 0; k1 < size; k1++) { x += ps.get(k1).getX(); y += ps.get(k1).getY(); } //得到新的中心点 Point nc = newPoint(-1, x / size, y / size, false); center.add(nc); } if(lastCenter.containsAll(center))//中心点不在变化,退出迭代 break; lastCenter = center; // 迭代运算 cluster = clustering(center, prepare(center)); // for (int nz = 0; nz < k; nz++) { // error += cluster.get(nz).getError();//计算误差 // } } returncluster; } /** * 输出聚类信息到控制台 * * @param cs */ publicvoid out2console(List<Cluster> cs) { for(inti = 0; i < cs.size(); i++) { System.out.println("No."+ (i + 1) + " cluster:"); Cluster c = cs.get(i); List<Point> p = c.getMembers(); for(intj = 0; j < p.size(); j++) { System.out.println("\t"+ p.get(j).getX() + " "); } System.out.println(); } } } 0 0
- 数据挖掘-聚类-K-means算法Java实现
- 数据挖掘-k-means算法实现
- 数据挖掘-K-means算法
- 数据挖掘算法-k-means
- 数据挖掘:K-Means算法的原理与Python实现
- 数据挖掘之k-means算法的Python实现
- 数据挖掘k-means聚类算法JAVA模拟
- 【数据挖掘】k-means聚类算法
- 数据挖掘 K-Means++聚类算法
- 数据挖掘之K-means算法
- 数据挖掘K-means算法必记。
- 数据挖掘实战之 K-means算法
- 数据挖掘算法之 k-means
- 数据挖掘-聚类分析:k-平均(k-Means)算法实现(C++)
- java实现k-means算法
- K-Means算法Java实现
- K-means算法(Java实现)
- 数据挖掘K-平均值(K-means)程序C实现
- bzoj1990 NOIP2007 树网的核 树的直径&单调队列维护最小值
- error:Error parsing XML:unbound prefix
- #菜鸟新手EclipseJavaEE&MySQL&Tomcat#关于一个Eclipse中登陆界面通过连接MySQL数据库进行验证的小体验(感谢qq群友引燃的解答让我解决这个小问题)
- Mahout机器学习平台之聚类算法详细剖析(含实例分析)
- Windows系统和Linux系统中的静态链接库与动态链接库(三)
- 数据挖掘-聚类-K-means算法Java实现
- 【oracle】使用oracle常见错误汇总
- 内存映射文件(专门读写大文件)
- cocos2dx 集成google 插屏广告 出现的bug
- TCP长连接与短连接的区别
- toString 和String.valueOf
- 安装xendesktop前的两个必要步骤
- 【已解决】(魅族)手机usb调试模式连接不上电脑
- poj1164The Castle(搜索)


