UVA 1584 - Circular Sequence(环状序列)(字典序)
来源:互联网 发布:组装服务器 知乎 编辑:程序博客网 时间:2024/04/27 04:01
1584 - Circular Sequence
Time limit: 3.000 seconds
Some DNA sequences exist in circular forms as in the following figure, which shows a circular sequence ``CGAGTCAGCT", that is, the last symbol ``T" in ``CGAGTCAGCT" is connected to the first symbol ``C". We always read a circular sequence in the clockwise direction.
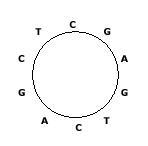
Since it is not easy to store a circular sequence in a computer as it is, we decided to store it as a linear sequence. However, there can be many linear sequences that are obtained from a circular sequence by cutting any place of the circular sequence. Hence, we also decided to store the linear sequence that is lexicographically smallest among all linear sequences that can be obtained from a circular sequence.
Your task is to find the lexicographically smallest sequence from a given circular sequence. For the example in the figure, the lexicographically smallest sequence is ``AGCTCGAGTC". If there are two or more linear sequences that are lexicographically smallest, you are to find any one of them (in fact, they are the same).
Input
The input consists of T test cases. The number of test cases T is given on the first line of the input file. Each test case takes one line containing a circular sequence that is written as an arbitrary linear sequence. Since the circular sequences are DNA sequences, only four symbols, A, C, G and T, are allowed. Each sequence has length at least 2 and at most 100.
Output
Print exactly one line for each test case. The line is to contain the lexicographically smallest sequence for the test case.
The following shows sample input and output for two test cases.
Sample Input
2 CGAGTCAGCT CTCC
Sample Output
AGCTCGAGTC CCCT题目大意:给你一个环状字符串,你可以从任意起点开始读,要求找出字典序最小的字符串。
思路:从字符串的每一个字符str[i]开始读字符串,让它和上一个字典序最小的比较,如果比上一个的字典序还小,那么就将minn更新为这个字符串的str[i]的i,然后继续比较。
这个函数的实现比较相似,毕竟是相同的思路
函数:
bool findmin(int n,int m)//查看以谁为新的字符串起点字典序最小{ int len=strlen(str); for(int i=0;i<len;i++) if(str[(n+i)%len]!=str[(m+i)%len]) return str[(n+i)%len]<str[(m+i)%len]; return false;//相等的情况}完整程序:
#include<iostream>#include<cstdio>#include<cstring>using namespace std;char str[105];bool findmin(int n,int m)//查看以谁为新的字符串起点字典序最小{ int len=strlen(str); for(int i=0;i<len;i++) if(str[(n+i)%len]!=str[(m+i)%len]) return str[(n+i)%len]<str[(m+i)%len]; return false;//相等的情况}int main(){ int t; cin>>t; while(t--) { cin>>str; int minn=0,len=strlen(str); for(int i=0;i<len;i++)//访问字符串的每一位 if(findmin(i,minn)) minn=i;//更新为大字典序的位置 for(int i=0;i<len;i++) printf("%c",str[(i+minn)%len]); printf("\n"); } return 0;}- UVA 1584 - Circular Sequence(环状序列)(字典序)
- Uva1584-环状序列-Circular Sequence-字典序
- UVa 1584 Circular Sequence(环状序列)
- uva 1584 Circular Sequence(环状串的最小字典序表示法)
- Uva1508 Circular Sequence 环状序列
- UVa1584 环状序列 (Circular Sequence)
- UVA 1584 Circular Sequence【字典序】
- 环状序列(Circular Sequence, ACM/ICPC Seoul 2004, UVa1584)
- UVa1584 Circular Sequence(环状序列) (java版本)
- 环状序列(Circular Sequence, ACM/ICPC Seoul 2004, UVa1584)
- UVa 1584 Circular Sequence(循环串 字典序)
- UVa 1584 Circular Sequence(环形串最小字典序)
- 环形字符串比较-环状序列3.6circular sequence
- UVa 1584 Circular Sequence
- UVa 1584 - Circular Sequence
- UVA 1584 - Circular Sequence
- UVA - 1584 Circular Sequence
- UVa 1584 - Circular Sequence
- HDU 1179 Ollivanders: Makers of Fine Wands since 382 BC.(匈牙利算法)
- 514 - Rails
- VS 字符集:Unicode和多字节字符集的区别与联系
- 如何删除微软visualstudio.com提供的远程TFS上的项目?
- intel realsense 开发序曲- sdk安装
- UVA 1584 - Circular Sequence(环状序列)(字典序)
- eclipse快捷方式收藏
- Cocos2dx 3.10 apk打包命令
- [Modern OpenGL系列(三)]用OpenGL绘制一个三角形
- python爬虫实战(一)----------爬取京东商品信息
- haartraining前将统一图片尺寸方法
- 3.spark streaming Job 架构和容错解析
- 通过preg_replace 函数将HTML 替换成文本
- 作业:C++作业5


