K-means(K均值)
来源:互联网 发布:边伯贤直播软件 编辑:程序博客网 时间:2024/05/14 11:20
K-means(K均值)
这一系列的博客前面介绍的线性回归(linear regression)、逻辑回归(logistics regression)、神经网络(neural network)和支持向量机(support vector machine)等算法都是监督学习算法(supervised learning)即事先知道训练集样本的类别。与之对应的还有无监督学习(unsupervised learning),在无监督学习中,训练样本的类别是未知的,目的是通过对无标记样本的学习来揭示数据的内在性质及规律,这一类学习任务中研究最多,应用最广,最具代表的就是聚类(cluster)。
聚类算法很多,如K-means、凝聚层次聚类和DBSCAN等,本篇博客只会介绍K-means(K均值)算法。本篇博客的结构如下:
一、详细介绍K-means算法的详细细节
二、K-means的优化目标
三、K-means初始质心的随机初始化
四、如何选择簇的个数
一、K-means算法的详细细节
K-means算法比较简单,是一种贪心策略的算法。首先,选取K个初始质心(K是用户指定的参数,即簇的个数)。把每个点指派到最近的质心,这样会形成K个点集,每个点集即为一个簇。然后,重新计算每个点集的质心,更新质心。重复以上步骤,直到簇不再发生变化(或者质心不发生变化)。
总结以上步骤,K-means基本算法如下:

看完以上的算法,下面用图来形象的表示下K-means算法的执行过程(质心用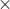 表示):
表示):



从上图大家能够看出K-means执行过程中质心的变化过程,以及最终形成两个簇。
以上只是K-means算法的基本框架及执行过程示意图,再详细的来说,表中算法:
步骤3:是通过计算样本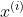 与质心
与质心 之间的距离
之间的距离 来把样本指派到距离其最近的质心(簇)中。
来把样本指派到距离其最近的质心(簇)中。
步骤4:通过计算簇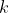 中所有向量的均值得到新的质心
中所有向量的均值得到新的质心 。
。
因此,综上,更加详细的K-means算法如下表所示:

二、K-means的优化目标
在K-means算法中使用误差的平方和(Sum of the Squared Error,SSE)来度量聚类的质量。在给定样本集 ,K-means算法希望最小化平方误差(SSE),即最小化目标函数:
,K-means算法希望最小化平方误差(SSE),即最小化目标函数:
因此,能够观察出上式表示了簇内样本围绕质心向量的紧密程度,SSE值越小则簇内样本相似度越高。但是最小化这个公式并不容易,因为如果想找到这个最优解需要枚举样本集D所有可能的簇划分,因此这是一个NP问题。所以K均值采用贪心策略,通过迭代优化来求近似解,这也就是为什么K-means有时候求得的划分是次优解。
Ng在课上给出的优化目标为:
这个应该是求的平均误差,最终的目的都是一样的。
三、初始质心的随机初始化
关于初始质心 的随机初始化,一般会这样选择:
的随机初始化,一般会这样选择:
- 期望簇的个数K应该小于样本数:
- 随机的选择K个训练样本作为初始质心:
但是这样选择有时候得到的是一个局部最优解,例如对于下图我们希望得到这样的最优解:

但往往可能得到这样的结果:

处理这样问题常用的方法是:多次运行,每次随机的选择一组初始质心,然后选择具有最小误差的簇集。比如:

但是这种方法只适应于簇的个数很小(10以内),如果簇的个数非常大,这种多次运行的方法基本上没什么影响。
PS:还有一些其他常用的技术进行初始化,如取一个样本,使用层次聚类技术对它聚类。然后从层次聚类中提取K个簇,并用这些簇的质心作为初始质心。该方法通常很有效,但是有以下局限:(1)样本相对较小,例如数千个(层次聚类开销较大)(2)K相对远小于样本大小。
四、如何选择簇的个数
首先说明,关于这个问题并没有一个标准答案,或者有什么方法能够自动决定簇的个数(或许已经有papper解决了自动选择的问题,我不太清楚)。目前常用的还是手动的决定簇的个数。Elbow method有时候能够帮助选择簇的个数,关于Elbow method就不多说了,大家可以自己去Wiki上看看https://en.wikipedia.org/wiki/Determining_the_number_of_clusters_in_a_data_set。直接上个图,让大家理解一下吧:

上图中圈起来的地方就是“Elbow”,类似于人手臂的肘部,如上图,如果簇的个数K与代价函数J的图像是这样的,我们倾向于选择K=3作为较好的簇的个数。但如果图像是这样的:

Elbow method则没有任何知道意义了,因此Elbow method并不是万能的。因此,有时候还要根据具体的实际应用需求来决定簇的个数。
0 0
- K-means(K均值)
- K-Means Algorithm(K-均值算法)
- k-Means(二分k-均值算法)
- k均值聚类(k-means)
- K均值聚类(K-means)
- k均值聚类(k-means)
- K-Means(K均值) 算法
- 经典算法(5):K-均值算法(K-Means)
- K均值聚类算法(K-Means Clustering Algorithm)
- 核K-均值聚类(Kernel K-means Clustering)
- k均值聚类(K-means)(转载)
- k均值聚类(K-Means Clustering)
- 4.k均值聚类(K-means)
- 聚类算法(一):k-均值 (k-means)算法
- 【学习笔记】机器学习-K均值(k-means)
- K-Means(K均值聚类算法)
- K-means(K均值原型聚类)
- 用K均值算法(K-means)做聚类分析
- C语言深度解剖读书笔记(1.关键字的秘密)
- selenium---git、testng、maven、jenkins构建job
- Go-Pholcus抓取IJGUC所有期刊
- JAX-WS
- 开始学习C#
- K-means(K均值)
- 一目了然解释getName()、getCanonicalName()和getSimpleName()的异同
- 两种方式实现checkBox readonly功能
- [Spring MVC] - SpringMVC的各种参数绑定方式
- 浅谈Autolayout-02代码实现Autolayout
- 两个链表的第一个公共结点
- 注解使用
- express创建项目
- Qt显示中文和使用中文路径


