Spark 源码解析 : DAGScheduler中的DAG划分与提交
来源:互联网 发布:软件的健壮性 编辑:程序博客网 时间:2024/06/06 00:18
一、Spark 运行架构
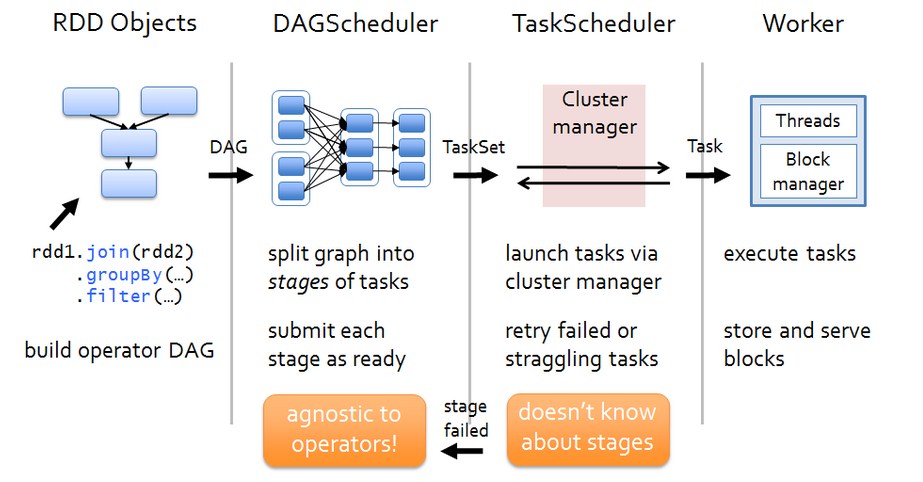


Spark 运行架构如下图:
各个RDD之间存在着依赖关系,这些依赖关系形成有向无环图DAG,DAGScheduler对这些依赖关系形成的DAG,进行Stage划分,划分的规则很简单,从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。完成了Stage的划分,DAGScheduler基于每个Stage生成TaskSet,并将TaskSet提交给TaskScheduler。TaskScheduler 负责具体的task调度,在Worker节点上启动task。
二、源码解析:DAGScheduler中的DAG划分
当RDD触发一个Action操作(如:colllect)后,导致SparkContext.runJob的执行。而在SparkContext的run方法中会调用DAGScheduler的run方法最终调用了DAGScheduler的submit方法:
def submitJob[T, U](rdd: RDD[T],func: (TaskContext, Iterator[T]) => U,partitions: Seq[Int],callSite: CallSite,resultHandler: (Int, U) => Unit,properties: Properties): JobWaiter[U] = {// Check to make sure we are not launching a task on a partition that does not exist.val maxPartitions = rdd.partitions.lengthpartitions.find(p => p >= maxPartitions || p < 0).foreach { p =>throw new IllegalArgumentException("Attempting to access a non-existent partition: " + p + ". " +"Total number of partitions: " + maxPartitions)}val jobId = nextJobId.getAndIncrement()if (partitions.size == 0) {// Return immediately if the job is running 0 tasksreturn new JobWaiter[U](this, jobId, 0, resultHandler)}assert(partitions.size > 0)val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)//给eventProcessLoop发送JobSubmitted消息eventProcessLoop.post(JobSubmitted(jobId, rdd, func2, partitions.toArray, callSite, waiter,SerializationUtils.clone(properties)))waiter}
DAGScheduler的submit方法中,像eventProcessLoop对象发送了JobSubmitted消息。eventProcessLoop是DAGSchedulerEventProcessLoop类的对象
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
DAGSchedulerEventProcessLoop,接收各种消息并进行处理,处理的逻辑在其doOnReceive方法中:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {//Job提交case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)case StageCancelled(stageId) =>dagScheduler.handleStageCancellation(stageId)case JobCancelled(jobId) =>dagScheduler.handleJobCancellation(jobId)case JobGroupCancelled(groupId) =>dagScheduler.handleJobGroupCancelled(groupId)case AllJobsCancelled =>dagScheduler.doCancelAllJobs()case ExecutorAdded(execId, host) =>dagScheduler.handleExecutorAdded(execId, host)case ExecutorLost(execId) =>dagScheduler.handleExecutorLost(execId, fetchFailed = false)case BeginEvent(task, taskInfo) =>dagScheduler.handleBeginEvent(task, taskInfo)case GettingResultEvent(taskInfo) =>dagScheduler.handleGetTaskResult(taskInfo)case completion: CompletionEvent =>dagScheduler.handleTaskCompletion(completion)case TaskSetFailed(taskSet, reason, exception) =>dagScheduler.handleTaskSetFailed(taskSet, reason, exception)case ResubmitFailedStages =>dagScheduler.resubmitFailedStages()}
可以把DAGSchedulerEventProcessLoop理解成DAGScheduler的对外的功能接口。它对外隐藏了自己内部实现的细节。无论是内部还是外部消息,DAGScheduler可以共用同一消息处理代码,逻辑清晰,处理方式统一。
接下来分析DAGScheduler的Stage划分,handleJobSubmitted方法首先创建ResultStage
try {//创建新stage可能出现异常,比如job运行依赖hdfs文文件被删除finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)} catch {case e: Exception =>logWarning("Creating new stage failed due to exception - job: " + jobId, e)listener.jobFailed(e)return}
然后调用submitStage方法,进行stage的划分。
首先由finalRDD获取它的父RDD依赖,判断依赖类型,如果是窄依赖,则将父RDD压入栈中,如果是宽依赖,则作为父Stage。
看一下源码的具体过程:
private def getMissingParentStages(stage: Stage): List[Stage] = {val missing = new HashSet[Stage] //存储需要返回的父Stageval visited = new HashSet[RDD[_]] //存储访问过的RDD//自己建立栈,以免函数的递归调用导致val waitingForVisit = new Stack[RDD[_]]def visit(rdd: RDD[_]) {if (!visited(rdd)) {visited += rddval rddHasUncachedPartitions = getCacheLocs(rdd).contains(Nil)if (rddHasUncachedPartitions) {for (dep <- rdd.dependencies) {dep match {case shufDep: ShuffleDependency[_, _, _] =>val mapStage = getShuffleMapStage(shufDep, stage.firstJobId)if (!mapStage.isAvailable) {missing += mapStage //遇到宽依赖,加入父stage}case narrowDep: NarrowDependency[_] =>waitingForVisit.push(narrowDep.rdd) //窄依赖入栈,}}}}}//回溯的起始RDD入栈waitingForVisit.push(stage.rdd)while (waitingForVisit.nonEmpty) {visit(waitingForVisit.pop())}missing.toList}
getMissingParentStages方法是由当前stage,返回他的父stage,父stage的创建由getShuffleMapStage返回,最终会调用newOrUsedShuffleStage方法返回ShuffleMapStage
private def newOrUsedShuffleStage(shuffleDep: ShuffleDependency[_, _, _],firstJobId: Int): ShuffleMapStage = {val rdd = shuffleDep.rddval numTasks = rdd.partitions.lengthval stage = newShuffleMapStage(rdd, numTasks, shuffleDep, firstJobId, rdd.creationSite)if (mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {//Stage已经被计算过,从MapOutputTracker中获取计算结果val serLocs = mapOutputTracker.getSerializedMapOutputStatuses(shuffleDep.shuffleId)val locs = MapOutputTracker.deserializeMapStatuses(serLocs)(0 until locs.length).foreach { i =>if (locs(i) ne null) {// locs(i) will be null if missingstage.addOutputLoc(i, locs(i))}}} else {// Kind of ugly: need to register RDDs with the cache and map output tracker here// since we can't do it in the RDD constructor because # of partitions is unknownlogInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)}stage}
现在父Stage已经划分好,下面看看你Stage的提交逻辑
/** Submits stage, but first recursively submits any missing parents. */private def submitStage(stage: Stage) {val jobId = activeJobForStage(stage)if (jobId.isDefined) {logDebug("submitStage(" + stage + ")")if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {val missing = getMissingParentStages(stage).sortBy(_.id)logDebug("missing: " + missing)if (missing.isEmpty) {logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")//如果没有父stage,则提交当前stagesubmitMissingTasks(stage, jobId.get)} else {for (parent <- missing) {//如果有父stage,则递归提交父stagesubmitStage(parent)}waitingStages += stage}}} else {abortStage(stage, "No active job for stage " + stage.id, None)}}
提交的过程很简单,首先当前stage获取父stage,如果父stage为空,则当前Stage为起始stage,交给submitMissingTasks处理,如果当前stage不为空,则递归调用submitStage进行提交。
到这里,DAGScheduler中的DAG划分与提交就讲完了,下次解析这些stage是如果封装成TaskSet交给TaskScheduler以及TaskSchedule的调度过程。
2 0
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
- [spark] DAGScheduler划分stage源码解析
- [spark] DAGScheduler 提交stage源码解析
- spark源码学习(五)--- DAGScheduler中的stage的划分
- spark源码学习(六)--- DAGScheduler中的task的划分
- [Spark源码剖析] DAGScheduler划分stage
- 源码-DAGScheduler及Stage划分提交
- DAGScheduler源码解析之Stage划分
- [Spark源码剖析] DAGScheduler提交stage
- Spark DAGScheduler 功能及源码解析
- DAGScheduler源码解析之作业提交
- Spark源码-DAGScheduler中stage划分和task最佳位置
- Spark源码分析之DAGScheduler以及stage的划分
- 【Spark】DAGScheduler源码浅析
- spark源码之Job执行(1)stage划分与提交
- spark源码之Job执行(1)stage划分与提交
- DAGScheduler源码解析(一)
- Spark源码阅读笔记:DAGScheduler
- Makefile (三) 总述
- Git命令行下自动保存用户名和密码
- [主席树区间覆盖 线段树] UNR #1 火车管理
- Android短信发送,监听,及其工具类封装
- ubuntu14.04系统相关
- Spark 源码解析 : DAGScheduler中的DAG划分与提交
- 转义字符
- UIProgressView 进度表
- IO
- APUE 8-1 fork函数实例
- 【嵌入式学习日记】2016年7月19日
- CC2540协议栈下开发流程
- linux vim 删除命令记录
- Spring整合Redis数据库(maven项目)


