CS231笔记的笔记:图像分类
来源:互联网 发布:如何正确下载软件 编辑:程序博客网 时间:2024/04/27 10:01
想对这两天看CS231N笔记有个总结,首先感谢斯坦福提供资源,杜客(智能单元)的翻译。
图像分类笔记
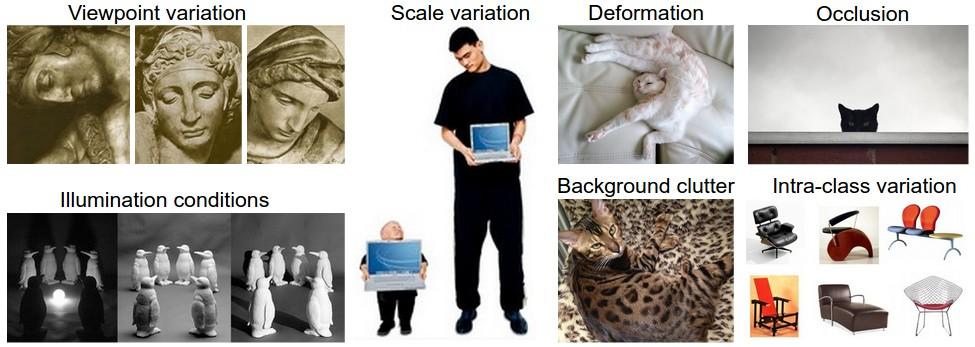
目前存在的问题:
视角变化(Viewpoint variation):同一个物体,摄像机可以从多个角度来展现。
大小变化(Scale variation):物体可视的大小通常是会变化的(不仅是在图片中,真实世界中大小也是变化的)。
形变(Deformation):很多东西的形状并非一成不变,会有很大变化。
遮挡(Occlusion):目标物体可能被挡住。有时候只有物体的一小部分(可以小到几个像素)是可见的。
光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认。
类内差异(Intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。这一类物体有许多不同的对象,每个都有自己的外形。
1、 Nearest Neighbor分类器
核心思想:
训练过程:将训练样本存入内存
测试过程:将测试样本于内存中的训练样本进行比较,标记为内存中与其差异值最小的那张图片的label。
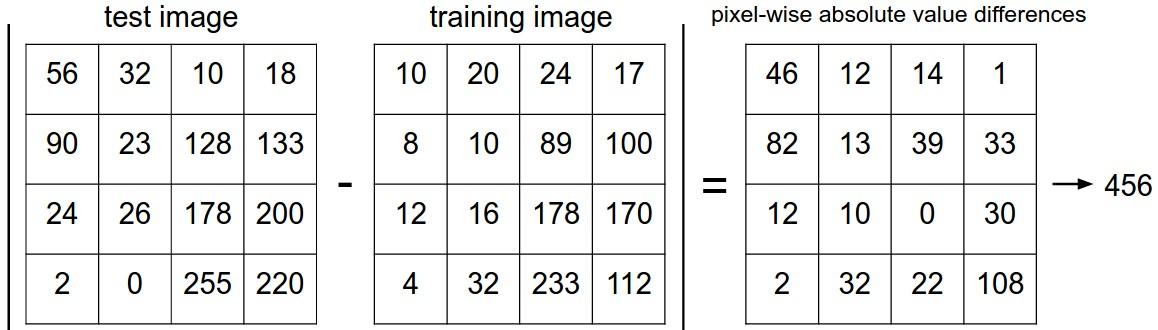
距离计算:L1和L2,后者更加不能容忍图像向量之间的差异值。相对来说,L2倾向于接受多个中等程度的差异
k-Nearest Neighbor分类器
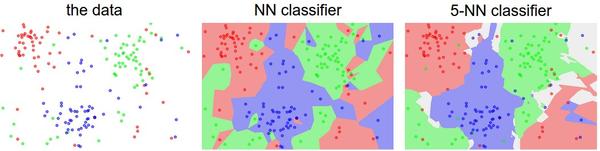
核心思想:上述NN方法,只在训练样本中找到一个最优模板,而K-NN则是找出K个最优模板,然后将其中比例最高的label作为测试样本的label。
k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。如图,NN中存在不正确分类很多孤岛,而5-NN则避免了这些。其中灰色区域代表投票结果中,多个最高票。
关于K的选择,这是个超参数(和L1,L2选择一样,理解为参数选择吧?)调优的问题。
1、最重要的,不要拿测试集来对模型进行调优!!!!测试集只能用一次,一旦这么做,实际上是把测试集作为了训练集,这会导致过拟合。
2、验证集调优:从训练集中,取出一部分,如10000中取1000作为验证集。前9000进行训练,验证集进行测试和调优。
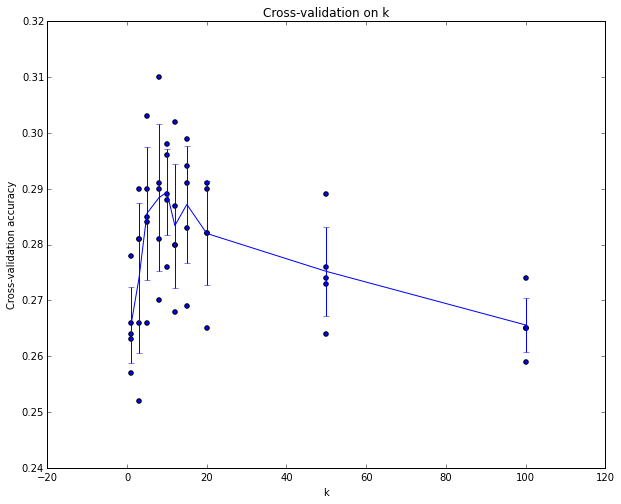
3、交叉验证:当训练集很小的情况下可以采用,将训练集分为N份,随机选取N-1份作为训练集,剩余一份作为验证集,组合一遍后,将N次验证的平均准确率作为验证准确率。方法和结果如图。

Nearest Neighbor分类器的优劣
1、训练很快,但是测试非常慢。这神经网络相反,非常不利于实用
2、理解、实现简单
3、在低维度,可以实用。但是不适合图像,因为图像都是高纬度的(多个像素),高纬度中的距离是反直觉的,如下图,后三者于第一张的距离是一样的,但是感官上差别很大。

小结
简要说来:• 介绍了图像分类问题。在该问题中,给出一个由被标注了分类标签的图像组成的集合,要求算法能预测没有标签的图像的分类标签,并根据算法预测准确率进行评价。
• 介绍了一个简单的图像分类器:最近邻分类器(Nearest Neighbor classifier)。分类器中存在不同的超参数(比如k值或距离类型的选取),要想选取好的超参数不是一件轻而易举的事。
• 选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的超参数,最后保留表现最好那个。
• 如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
• 一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
• 最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储所有训练数据,并且在测试的时候过于耗费计算能力。
• 最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和颜色被分类,而不是语义主体分身。
实际应用k-NN
如果你希望将k-NN分类器用到实处(最好别用到图像上,若是仅仅作为练手还可以接受),那么可以按照以下流程:1. 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。在后面的小节我们会讨论这些细节。本小节不讨论,是因为图像中的像素都是同质的,不会表现出较大的差异分布,也就不需要标准化处理了。
2. 如果数据是高维数据,考虑使用降维方法,比如PCA(wiki ref, CS229ref, blog ref)或随机投影。
3. 将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。如果需要预测的超参数很多,那么就应该使用更大的验证集来有效地估计它们。如果担心验证集数量不够,那么就尝试交叉验证方法。如果计算资源足够,使用交叉验证总是更加安全的(份数越多,效果越好,也更耗费计算资源)。
4. 在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
5. 如果分类器跑得太慢,尝试使用Approximate Nearest Neighbor库(比如FLANN)来加速这个过程,其代价是降低一些准确率。
6. 对最优的超参数做记录。记录最优参数后,是否应该让使用最优参数的算法在完整的训练集上运行并再次训练呢?因为如果把验证集重新放回到训练集中(自然训练集的数据量就又变大了),有可能最优参数又会有所变化。在实践中,不要这样做。千万不要在最终的分类器中使用验证集数据,这样做会破坏对于最优参数的估计。直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的kNN分类器在该数据上的性能表现。
0 0
- CS231笔记的笔记:图像分类
- cs231笔记的笔记2:线性分类器
- cs231笔记的笔记:神经网络1
- cs231学习笔记二 线性分类器、SVM、Softmax
- CS231课程笔记翻译
- CS231 笔记 卷积神经网络
- cs231学习笔记一 图像识别与KNN
- cs231课程笔记翻译--学习
- 斯坦福大学CS231课程笔记1
- 斯坦福大学CS231课程笔记2
- 图像分类笔记
- CS231N图像分类笔记总结
- CS231n课程笔记--图像分类
- CS231n课程笔记翻译:图像分类笔记
- MATLAB学习笔记之二 图像的分类和显
- 利用CNN进行图像分类学习笔记
- CS231n课程图像分类学习笔记
- 【OpenCV学习笔记 015】SVM图像分类
- 正向代理,反向代理和透明代理
- jsp中include的用法笔记
- 编程——折纸问题
- Python函数式编程之map() reduce()
- Cent OS 下安装Apache 详细教程
- CS231笔记的笔记:图像分类
- Scala学习第四弹 访问修饰符
- CSS选择器
- C++中实现cin输入的结束
- 门面模式【Facade Pattern】
- Singleton
- 身份证 验证
- 禁用sublime自动更新提示
- Httpurlconnection多文件上传问题。


