bfs与dfs
来源:互联网 发布:苹果手机怎么改网络 编辑:程序博客网 时间:2024/04/29 12:11
搜索专题进行了一周,大概总结一些
资料来源:http://blog.csdn.net/lulipeng_cpp/article/details/7524133
http://blog.csdn.net/grit_icpc/article/details/47444923
一般来说,广搜常用于找单一的最短路线,或者是规模小的路径搜索,它的特点是"搜到就是最优解", 而深搜用于找多个解或者是"步数已知(好比3步就必需达到前提)"的标题,它的空间效率高,然则找到的不必定是最优解,必需记实并完成全数搜索,故一般情况下,深搜需要很是高效的剪枝(优化).
像搜索最短路径这些的很显著若是用广搜,因为广搜的特征就是一层一层往下搜的,保证当前搜到的都是最优解,当然,最短路径只是一方面的操作,像什么起码状态转换也是可以操作的。
深搜就是优先搜索一棵子树,然后是另一棵,它和广搜对比,有着内存需要相对较少的所长,八皇后标题就是典范楷模的操作,这类标题很显著是不能用广搜往解决的。或者像图论里面的找圈的算法,数的前序中序后序遍历等,都是深搜
深搜和广搜的分歧之处是在于搜索次序的分歧。
深搜的实现近似于栈,每次选择栈顶元素往扩年夜,
广搜则是操作了队列,先被扩年夜的的节点优先拿往扩年夜。
搜索树的形态:深搜层数良多,广搜则是很宽。
深搜合适找出所有方案,广搜则用来找出最佳方案
深搜和广搜的分歧:
深搜并不能保证第一次碰着方针点就是最短路径,是以要搜索所有可能的路径,是以要回溯,标识表记标帜做了之后还要打消失踪,是以统一个点可能被访谒良多良多次。而广搜因为它的由近及远的结点扩年夜次序,结点老是以最短路径被访谒。一个结点假如第二次被访谒,第二次的路径确定不会比第一次的短,是以就没有需要再从这个结点向周围扩年夜――第一次访谒这个结点的时辰已经扩年夜过了,第二次再扩年夜只会获得更差的解。是以做过的标识表记标帜不必往失踪。是以统一个点至多只可能被访谒一次。每访谒一个结点,与它相连的边就被搜检一次。是以最坏情况下,所有边都被搜检一次,是以时刻复杂度为O(E)。1、所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次。
2、实现bfs和dfs都需要解决的一个问题就是如何存储图。一般有两种方法:邻接矩阵和邻接表。这里为简单起
见,均采用邻接矩阵存储,说白了也就是二维数组。
3、本文章的小测试部分的测试实例是下图:
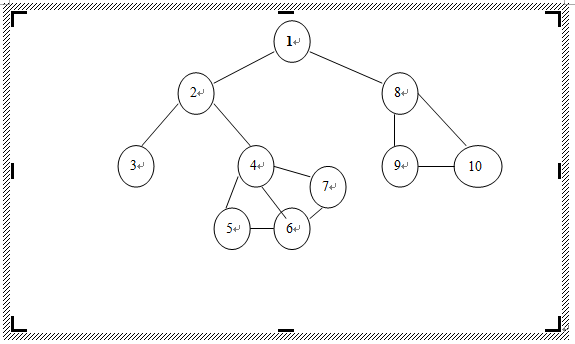
一、深度优先搜索遍历
1、从顶点v出发深度遍历图G的算法
① 访问v
② 依次从顶点v未被访问的邻接点出发深度遍历。
2、一点心得:dfs算法最大特色就在于其递归特性,使得算法代码简洁。但也由于递归使得算法难以理解,原因
在于递归使得初学者难以把握程序运行到何处了!一点建议就是先学好递归,把握函数调用是的种种。
3、算法代码:#include<iostream>using namespace std;int a[11][11];bool visited[11];void store_graph() //邻接矩阵存储图{int i,j;for(i=1;i<=10;i++)for(j=1;j<=10;j++)cin>>a[i][j];}void dfs_graph() //深度遍历图{void dfs(int v);memset(visited,false,sizeof(visited));for(int i=1;i<=10;i++) //遍历每个顶点是为了防止图不连通时无法访问每个顶点if(visited[i]==false)dfs(i);}void dfs(int v) //深度遍历顶点{int Adj(int x);cout<<v<<" "; //访问顶点vvisited[v]=true;int adj=Adj(v);while(adj!=0){if(visited[adj]==false) dfs(adj); //递归调用是实现深度遍历的关键所在adj=Adj(v);}}int Adj(int x) //求邻接点{for(int i=1;i<=10;i++)if(a[x][i]==1 && visited[i]==false)return i;return 0;}int main(){cout<<"初始化图:"<<endl;store_graph();cout<<"dfs遍历结果:"<<endl;dfs_graph();return 0;}4、小测试
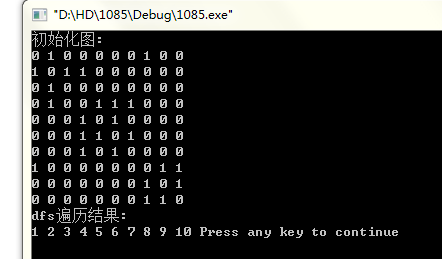
二、广度优先搜索遍历
1、从顶点v出发遍历图G的算法买描述如下:
①访问v
②假设最近一层的访问顶点依次为vi1,vi2,vi3...vik,则依次访问vi1,vi2,vi3...vik的未被访问的邻接点
③重复②知道没有未被访问的邻接点为止
2、一点心得:bfs算法其实就是一种层次遍历算法。从算法描述可以看到该算法要用到队列这一数据结构。我这
里用STL中的<queue>实现。该算法由于不是递归算法,所以程序流程是清晰的。
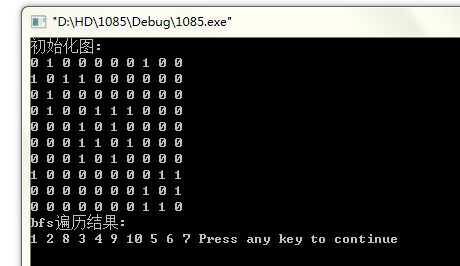
3、算法代码:#include<iostream>#include<queue> using namespace std;int a[11][11];bool visited[11];void store_graph() {for(int i=1;i<=10;i++)for(int j=1;j<=10;j++)cin>>a[i][j];}void bfs_graph() {void bfs(int v);memset(visited,false,sizeof(visited));for(int i=1;i<=10;i++) if(visited[i]==false)bfs(i);}void bfs(int v){int Adj(int x);queue<int> myqueue;int adj,temp;cout<<v<<" ";visited[v]=true;myqueue.push(v);while(!myqueue.empty()) //队列非空表示还有顶点未遍历到{temp=myqueue.front(); //获得队列头元素myqueue.pop(); //头元素出对adj=Adj(temp);while(adj!=0){if(visited[adj]==false){cout<<adj<<" ";visited[adj]=true;myqueue.push(adj); //进对}adj=Adj(temp);}}}int Adj(int x) {for(int i=1;i<=10;i++)if(a[x][i]==1 && visited[i]==false)return i;return 0;}int main(){cout<<"初始化图:"<<endl;store_graph();cout<<"bfs遍历结果:"<<endl;bfs_graph();return 0;}4、小测试:
- BFS 与 DFS
- bfs与dfs
- DFS与BFS
- DFS与BFS
- dfs与bfs实现
- bfs与dfs
- 【图】BFS与DFS
- BFS与DFS总结
- bfs与dfs
- DFS与BFS
- dfs与bfs
- dfs与bfs
- BFS与DFS
- DFS 与 BFS
- DFS与BFS
- BFS与DFS
- BFS与DFS
- DFS与BFS遍历
- 《JavaScript 闯关记》之单体内置对象
- MYSQL千万级数据量的优化方法积累
- UVA 12118 图+欧拉路
- 试探法
- 单片机栈溢出的一种检测方法
- bfs与dfs
- 基于codeigniter框架写的网站日志系统适配器(支持写入本地文件、数据库、远程服务器)
- mysql主从同步
- 坑爹的问题,Spark On Yarn ERROR spark.SparkContext: Error initializing SparkContext.
- SPI、I2C、UART三种串行总线协议的区别和SPI接口介绍
- ubuntu下 离线安装apt-get 、python包
- QT之TCP通信简单实现
- 商人的诀窍
- Dll数据封装


