最近在学习NLP相关内容, 学到Visualizing Representations部分的时候,老师推荐读这篇文章。本文介绍了比较新的,而且实用的高维数据可视化方法,并且包含一些例子,里面没有太多的公式和算法,浅显易懂,适合入门的朋友阅读。
本文于2015年1月26日发表于colah的github博客,原文链接:http://colah.github.io/posts/2015-01-Visualizing-Representations/
个人水平不高,如有错误希望大家指正。另外一些专业术语,我也不知道如何翻译的,或者是比较复杂的术语,可能会以原型或缩略词在文中出现。
下文中有一词表示(representation)可能比较晦涩难懂,你可以简单的理解成数据在该处变换和重塑的抽象或者说数据的描述形式,作者给出的意思是:The representation perspective is an abstraction over inputs. Instead of trying to understand what the neural network does to a single input, we try to understand what it does to the space of inputs, to the data manifold. It’s a step up the ladder of abstraction. Later, we will take a second step, allowing us to look at the space of neural networks, instead of a single one.
以下是译文:
前言
在前面的博文中,我曾经提到过一些高维数据可视化(visualizing high-dimensional data)的技术。从它本身来说,是个非常有趣的技术点,但是往往我们的目标不在于此。在我看来,这项技术现存的不足,对于我们进一步理解机器学习和深度神经网络的内部机制,造成的了极大的障碍。
深度神经网络(Deep neural networks,后称:神经网络、网络)是一种解决机器学习问题的手段。过去几年中,它使得计算机视觉(computer vision)和语音识别(speechrecognition )领域有了巨大的突破,颇有拨云见日之感。这些技术手段在很多其他领域也已经有了非常具有价值的成果,比如:语言理解(language understanding)和机器翻译(machine translation)。尽管如此,要想理解这些网络背后究竟做了什么,仍然是个巨大的挑战。
在我看来,降维(dimensionality reduction)不光是一种技术手段,还给我们进一步理解神经网络提供了很多线索。
不过,理解神经网络只是揭露了问题的表象,通过这去理解数据如何在内部运作的才是更重要的事情。在高维数据可视化的领域下,结合运用神经网络和降维是个非常有趣的技术点——这比单独使用降维要功能强大的多。
神经网络变换空间(Neural Networks Transform Space)
其实,不是所有的神经网络都难以理解的。实际上,低维神经网络还是相当容易理解的,比如:每层只有2到3个神经元(neurons)。
让我们一起来看看这么这数据集,一个平面内有两条曲线。给定一个位于曲线上的点,我们的神经网络就可以预测说来它来自哪一条曲线。
接下来,我们使用一个具有一层输入和一层输出的神经网络,按直线对其进行分类,如图:
在这个例子中,仅仅通过一条直线,是无法特别理想的分类的。所以,只含有一个输入层和一个输出层的神经网络,不能在这个例子中很好的分类。
但是在实践中,往往神经网络还会加上很多中间层,我们称为隐含层(hidden layers)。它们会对数据进行重塑和变换,使其能够更好的分类。如下图:
在这里,我们将数据的版本和不同层的表示(representation)一一对应。输入层是原始数据,中间的隐含层是对原始数据的变形,使数据能更容易的进行分类。
低维神经网络是非常容易理解的,因为我们可以非常直观的看到数据的展示,以及隐含层是以何种方式对数据进行变形的。所以,如果你对内部的机制感兴趣的话,直接看看就知道了。(这里只提到了一点点,如果你对这部分感兴趣,还可以参考我之前写的博文 神经网络、流型和拓补(Neural Networks, Manifolds, and Topology))
不幸的是,神经网络常常都不是低维的。它的强大之处就是对高维数据进行分类。比如说,计算机视觉的数据,往往有成百上千个纬度,隐含层也需要对这么多的纬度进行转换。
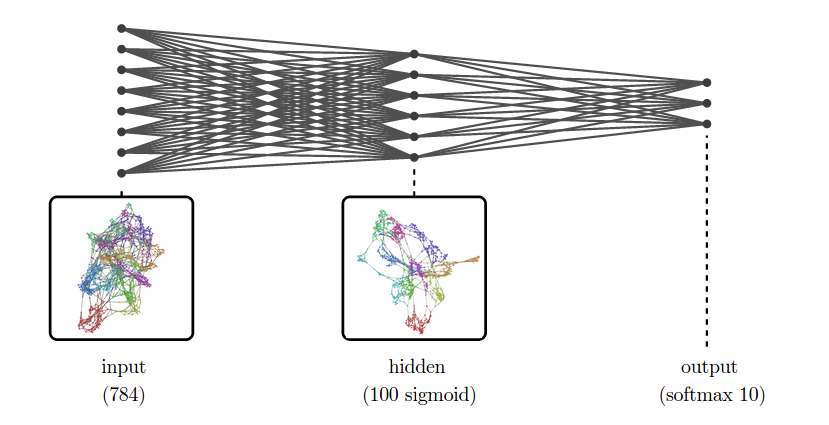
例如,我们要对MNIST(译者注:一个入门级的计算机视觉数据集,它包含各种手写数字图片)进行分类。输入层是一个784维的向量,即使使用一个非常简单神经网络,我们也需要一个隐含层来处理高维数据。更具体的说,假设我们有一个隐含层,它很有100个Sigmoid(译者注:一个良好的阈值函数,能将变量映射到0-1之间)神经元。
由于我们不能直接观察高维数据,所以我们尝试展示降维以后的数据。下图是一个MNIST神经网络的训练示意图,我们可以看到在原始数据和隐含层之间拥有很多的连接,这意味着数据的转换和重塑:
在输入层中,我们可以看到数据的展示结果是非常混乱的。在下一层我们可以看到,由于模型已经经过训练了,隐含层已经知道如何将数据转化成新的表示,因此,数据结果看起来要分的更开一些。
在深度学习中,这种方式(通过降维进行高维数据可视化)在评估模型的时候应用的极其广泛。
除了理解神经网络内部的进行机制之外,评估模型展示可以帮助我们进步了解数据本身。就算是用一些非常复杂的降维手段,很多真实世界的数据集也是难以理解的,它们的结构往往是复杂和混沌的。但是,更高维的展示正满满变的更加容易和理性,并且更助于人类阅读。
(值得一提的是,降维这个概念并不新潮,事实上,它已经变的非常的普遍。一个更好的例子是Andrej Karpathy的visualizations of a high-level ImageNet representation(译者注:这是一篇有关t-SNE可视化的文章),然而我的贡献更多的在于关注它的实现和发展)
示例 1: Word Embeddings
Word Embedding(译者注:将单词用向量来表示,比如:apple=[0.1,-0.2,0.3],orange=[0.3,0.2,-0.5],后文会有具体介绍。另一种常见的表现形式是:将整个文档作为一个向量,词典里的词汇数量作为向量里的元素数量,词汇的词频作为元素的值,这样的矩阵中有大量的0,特别稀疏,在下一个例子中也会有提到。)是一种非常有意义的单词表现形式,特别是在使用神经网络来解决语言问题的时候。
对于这些任务,输入网络中的是一个或者多个单词(这里的单词都指的是英文单词),每个单词都可以被表示成一个高维空间向量,每个维度都对应的是单词表中的一个单词(维度高大几万)。网络将这种高维数据和空间进行转换和压缩,把这些高维向量映射到低维中去(几百个维度),这就被称为word embedding。
在word embedding中,每个单词都是一个几百维的向量。这些向量有一些特别有用的属性,接下来将可视化这些属性。我们将会看到,意思相似的单词,空间距离也较为相近。
(除了邻近性,这些embedding还有很多其他有趣的特性。例如:这些向量的空间方向似乎有语义含义,进一步说,单词向量之间的差的构成是非常相似的,比如,“女人”和“男人”之间的差,和“女王”和“国王”之间的差是近似的:v(woman)-v(man)≈v(queen)-v(king).对于更多有关内容,你可以参考我之前的博文Deep Learning, NLP, and Representations)
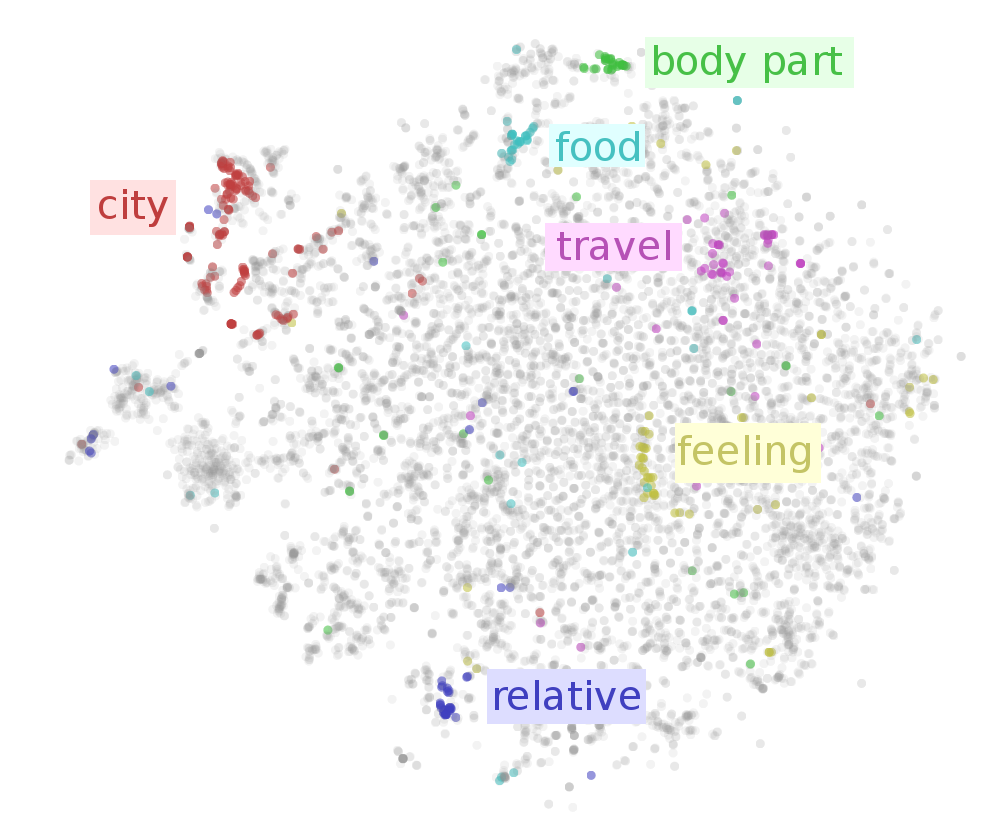
为了在二维空间中展示embedding的结果,我们需要选择一些合适的降维方法。如果我们需要表示单词语义之间的关系(比如近义词关系),我们可以选择t-SNE(译者注:一种热门有效的高维数据可视化方法,使用概率表示相对性,经过多次迭代后可以将邻近数据变的更加分开,可以参考h博文:从SNE到t-SNE再到LargeVis)。因为这种方法可以使得高维相邻的点,在二维空间上更加的接近。
通过下面的t-SNE图,我们可以看到二维空间邻近的点,语义上也存在相似的关系。但是,这里的单词量太大,为了看的更清楚,我们高亮了具有部分相似语义的单词:城市,身体部分,食物,旅游,感觉,亲属。
我们以上看到的只是例子,在后面的交互可视化中,你可以选择高亮具有不同语义的单词,还可以单独查看每个点对应的单词。(译者注:以下为屏幕截图,我选择查看“室外游戏.n.01”和"食物.n.01",可以看到鼠标位置周围有一些游戏,目前显示的是棒球,原始的交互程序是由JavaScript编写,嵌入到原始网页中,请点击原始网页链接查看。另外,这种词汇标记法xxx.x.xx是代表“单词.词性.序号”,来自WordNet)
![]()

示例 2: 维基百科中的Paragraph Vector
Paragraph vector是由 Le & Mikolov在2014年提出的,是由多个向量组成,用于表示一大段文本。它有很多种形式,在这里我们用的是最简单的一种,用来表示基于词袋模型(bag of words)的一些特征。
对于word embedding,我们通过向量学习来解决一些基于单词的语言问题。对于paragraph vector,我们通过向量学习来预测哪些单词在给定的段落中。
详细的说,神经网络可以针对不同的段落进行学习,得到单词的近似低维统计量。这种神经网络的隐含层中,我们可以得到表示每个段落的向量。这些向量具有一些很有价值的特性,比如,具有相似含义的段落也会非常的相近。
最近,谷歌有一些非常厉害的大牛, Andrew Dai, Quoc Le, 和Greg Corrado,他们决定对于一些有趣的数据集创建paragraph vector,其中之一就是维基百科,对每个英文的维基百科文章都创建一个向量。很有幸我能参加这个项目,并做了一些可视化的工作。
由于维基百科文章数量太大,我们可视化了它们的一个子集,然后我们用t-SNE进行计算,因为我们想知道哪些文章内容是相近的。
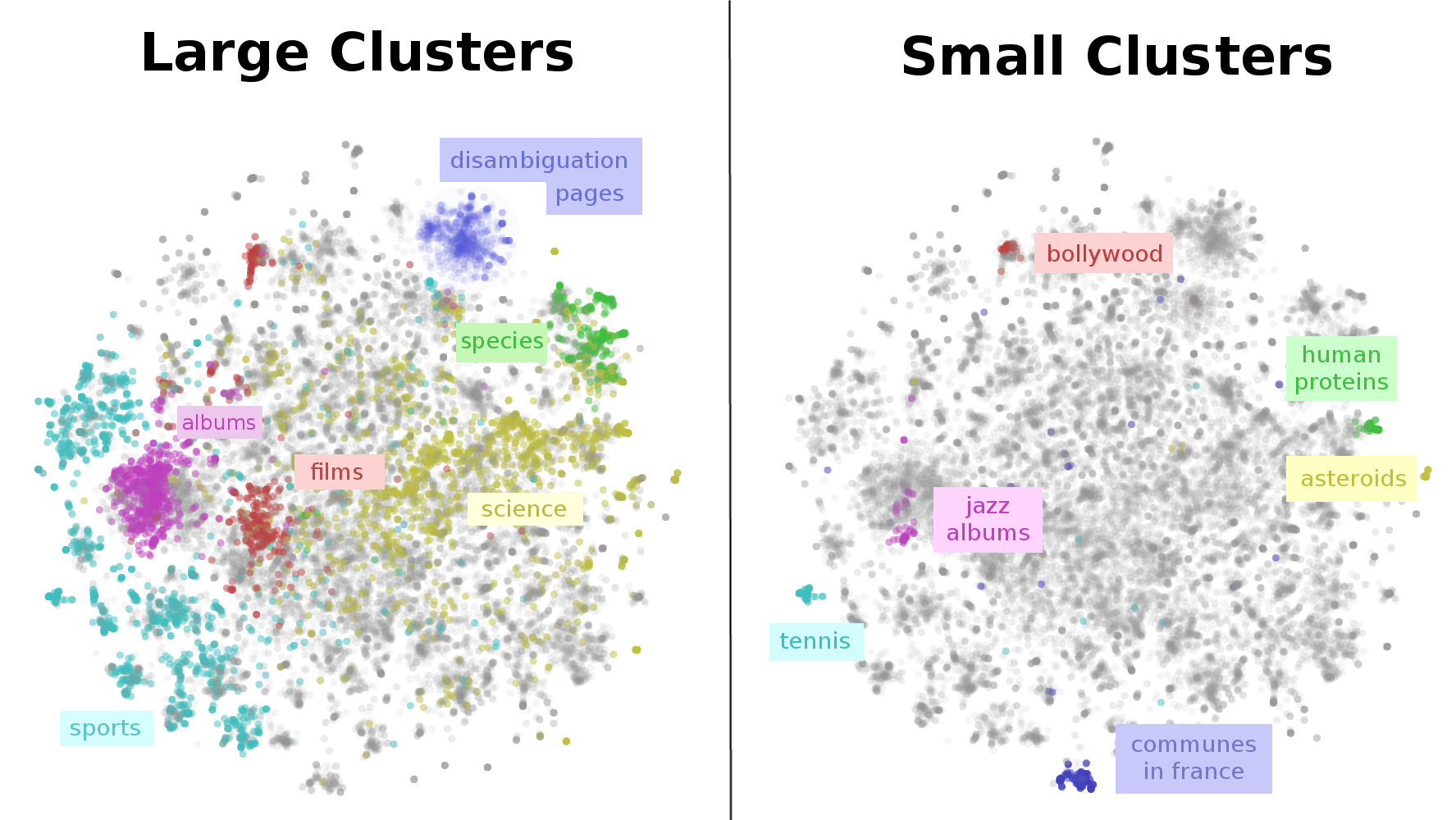
下图就是我们对整个维基百科进行可视化后的结果——一幅维基百科的地图。从左图可以看到,大部分的词条都属于以下几个领域:体育、音乐(歌曲和唱片)、电影、物种和科学。为什么和体育有关的词条这么多,看起来是因为体育是由很多个独立的小的子类组合起来的,像是运动员、球队、体育馆、赛季、联赛和游戏,同样的因素造成了其他几个大类。
上面的维基百科地图向我们展示了一个非常重要的结构。在一个巨大的体育簇(cluster)下,还有很多小的子簇(subcluster),比如:网球。非西方电影有多个分离的簇,像是宝莱坞。即使是看起来比较细的话题文章,像是人类蛋白质,也被分开了。
和上一个示例一样,这个例子同样提供了一个交互的界面来查询你感兴趣的话题(请点击原文链接),在图中对应的位置,和行程的簇。下图交互小程序的截图,我输入的是“电影”,显示的是电影在图中的位置,分为了上下两个大簇。
(另外,维基百科的分类实际上比远比你想的要广。For example, every human is included in the category applied ethics because humans are in peoplewhich is in personhood which is in issues in ethics which is in applied ethics.)
示例 3: 翻译模型
上面两个例子尽管很有趣,但是都有一点特殊。他们都是通过神经网络来处理数据,并且得到了非常好的展示。这种可视化效果非常炫酷而且有用,但是它们对于我们进一步理解神经网络并没有太大帮助。
那下面,让我们来一起看看cutting edge network做的一个真实例子:将英语翻译成法语,来自Sutskever et al. (2014)。
案例中,使用了两个递归神经网络(RNN),将英语句子翻译成法语句子。首先,一个单词一个单词的对英文句子进行处理,并表示它们。接下来,输入这些英文句子的表示,并连续的输出翻译后的单词。最后,使用多层长短期记忆人工神经网络(Long Short Term Memory)将这两个步骤放在一起进行联合训练。
我们可以看到,在左边的英语句子结束以后(EOS=“end of sentence”),通过中间的表示,得到的是右边的法语句子。这些表示非常重要,以某种方法,从英语的句子,我已经得到了某个用于信息编码的向量,将英语的句子转换为法语的句子。
通过t-SNE算法,进一步来分析我们的计算结果:
下面是程序截图,我输入的首字母是“According”
鼠标选择了另一个句子,我们再看一个以“According”开头的:
你可以看到,前一个说的是“受欢迎的戏服”,后一个说的是“中国反恐问题”。这两个句子内容几乎完全无关,但是可视化结果的距离非常的接近。这个结果让我们觉得惊讶:句子的表示主要是根据第一个单词进行的。
如果你自己的看,你可以看到更多结构化的内容。在有些地方,我们可以看到子簇的主题对应的是第二个词。在另一些地方,我们会发现是由一些相似的第一个词主导的,比如:“this”和“that”。但是总的来说,句子的转换和表示主要是由第一个词控制的。
这可能是由以下几个原因造成的:1.根据我们输入的句子,最开始处理的是第一个词,因此,神经网络可能强烈的认为第一个词是信息量最大的;2.第一个词可能是最难翻译的,因为翻译后面的词可以根据前面的信息来进行,像是马尔科夫链(Markov chain)。
尽管可能有更多的原因造成这个现象 ,但是我们依然觉得非常惊讶。我觉得,有更多的案例已经出现这种情况,只要将结果可视化一下,就可以很清楚的发现这种惊讶的现象。但是实际上,由于可视化存在困难,我们往往没能看到这样的结果。
高维数据可视化的模式
有关低维数据可视化,我们已经有了很多优秀的实践。例如,在学校中会学到的,“给坐标轴加上标题和单位”等。这些常用的规则有利于可视化和交流低维数据。
不幸的是,这些规则并不适用于高维数据可视化。如何给t-SNE图的坐标轴中加上标题?这种坐标轴并没有什么确切的含义,它们更是没有单位。在t-SNE图中,唯一有意义的东西就是,点与点之间是接近的。
在绘制t-SNE图的时候,还会有一些不寻常的挑战,我们可以看一下下面这个图:
先看看左手边的男性名字(译者注:这幅图本来就不是交互式的,作者故意让你鼠标点上去没有反应,来说明这个问题),但是在左边看不到任何有关男性名字的簇(是不是很沮丧啊,鼠标放上去也没反应)。尽管,这幅图中点的位置和之前示例中的位置一模一样,但是,如果你不能看到哪个点对应的是哪个单词,那这幅图完全是没有意义的。根据这幅图,我们最多只能判断:这些点不是随机的。
问题的关键就在于:就算是你知道你画的是什么,你也能够将高维数据生成低维的图像,但是低维图像中点的位置并不能解释任何数据,这样是没有意义的。
接下来,让我们来解决这个问题,让我们在图上加上一些提示框。现在,当把鼠标放上去的时候,你就可以看到指定点对应的位置了。(译者注:作者在这里就给图像加入了交互功能,用来说明以上的观点)
接下来,请你试着找找“身体”有关的单词。哈哈哈,你是不是没有耐心在成千上万个点找到与“身体”有关的单词啊,除非你记得之前的位置,要不然你肯定找不到。
所以说,仅仅只是观察点和对应单词的位置是远远不够的。因此,面对大量的数据,一个可行的方法是,用某种方式快速的强调某些数据,让人一下就能看清楚。
在这里,我个人总结出2点有关高维数据可视化的原则(基于我整三个月的工作经验):
- 必须有办法去获取独立的数据点
- 必须有办法去强调数据
交互可视化(interactive visualization)就可以轻松的满足以上两个原则,但是它并不是唯一的办法。在最初的t-SNE论文中,还有一种非常美观的对于MNIST的可视化方法Maaten & Hinton (2008),如下图:
通过直接将每个MNIST字符嵌入到图表中(译者注:在图中我们可以看到,不同的部分都是由很多很小的阿拉伯数字组成的,这种方式对应的是非交互可视化),Maaten和Hinton使得查看每个独立的点变的十分容易,并且每个点的对应的原始数据也一目了然。
不幸的是,这种方式仅仅是在处理简单的MNIST图像的时候管用。
Cho et al. (2014)有一篇关于短语分析的优秀论文,也使用到了t-SNE,下面是一部分短语分析结果的图表:
上图中,我们也能看出邻近的短语在语义上也存在很大程序的相似性。不幸的是,如果直接将所有的短语绘制到图标上是行不通的,因为它们实在是太庞大太臃肿了。老实说,对于这种数据集,除了交互可视化,我并没有看到其他更好的可视化方法。
几何指纹(Geometric Fingerprints)
接下来,让我们一起来看另一种非常有趣的表示,回到最简单的MNIST数据,来看看是如何进行的。这一次,我们选择使用PCA来对这个案例进行降维,主要有两个原因:1.它能使我们观察一些这些表示的几何指纹;2.相比之前讨论的其他降维算法,PCA有较小的随机性。
下面你看到的网络有5个Signoid隐含层,尽管实践中从来都不会使用这样的网络,但是它还有有一些有趣的特性。
上图你可以看到,网络隐含层的表示有点像高维立方体的映射,这是因为Sigmoid单元将数据的值映射到了接近0或1,中间值较少。如果你继续下去,会发现大量的数据点聚集在高维立方体的角落,少部分落在边缘。PCA最终会将数据点映射到一个二维空间里。
这种类立方体结构是Sigmoid隐含层的一种几何指纹。如果你使用其他的激励函数(Activation function)会有类似的几何指纹,下面让我们看看ReLU(Rectified linear unit,修正线性单元,f(x)=max(0,x))隐含层。
因为ReLU隐含层有更高的概率使得数值映射到0,所以很多的点都聚集在了原点和坐标轴上。如果将数据映射到二维空间中,它看起来会像是从原点发散出来的多条射线。
这些集合属性在只有几个神经元的时候会变的更加明显。
展示空间(The Space of Representations)
每次我们训练神经网络的时候,我们都会得到新的展示。就算是多次重复训练相同的网络,以上的论断也是成立的,因为对于一个数据集,很容易有多重不同的展示。
我们很少能看到这么多不同的展示,只要我们想这么做,它们也很容易被可视化。下面我们就来看看它们:
(译者注:这里作者实际上也提供的是一个交互程序,左边可以选择你想看的层次,右边鼠标放上去的时候可以看到对应点对应的数字图像。下面两幅图都是屏幕截图,选择是不同的展示,查看右边数据点的可视化效果。)
现在,当我们可以选择左边的项目来查看数据不同的表示,但是这一切实在是没有什么帮助。我们能从中看出什么吗?似乎没有。当然,这里面很有很多独特的展示,但是它们之间很难作比较,也无法有一个全局的视图。
接下来,让我们把注意力放在比较不同的展示上。一个非常微妙的事实是,两个极度相似的神经网络可能会在我们注意不到的地方造成巨大的不同。比如说,交换两个神经元的位置,它们的展示也可能会被旋转或翻面。
不管怎么说,我们会尽可能的去忽略掉那些不重要的差异,并将注意力放在更重要的差异点上。我们更需要一种标准的范式,来定义表示的不同。
在图中,数据点之间的距离似乎非常重要。所有其他可以忽略的差异点都是可以进行等距离变换的(isometries ),比如:二维空间内的旋转或交换并不改变数据点之间的相对距离。另一方面,数据点之间的距离是非常重要的,因为,更接近的数据点,可以认为它们的相似度更高,反之亦然。
幸好这里有一种简单的方式可以很好的处理等距离变换。对于任意一个表示X,存在一个相关的度量函数(metric function),dX,这个函数定义的是给定两点在当前表示X下的距离。对于另一个表示Y,如果dX=dY,当且仅当表示X和表示Y是等价的。这种度量函数精确的描述了我们需要的信息。
实际上,我们还不能直接使用dX这个定义,因为这个函数是在高维连续空间中的(译者注:因为在连续空间里,是无法计算所有的dX(Xm,Xn)的,因为有无限个Xn,这样一来无法比较dX和dY是否等价)。我们需要将它离散化,才能变得有用。
另外,我们还可以将Dx扁平化,把表示X的性质编码成一个向量。我们可以对很多不同的表示做同样的计算,得到一组高维向量。
很自然的,对于表示,我们还可以使用降维的手段,比如:t-SNE。Geoff Hinton把这种方法称作“meta-SNE”,除此之外,他还使用了很多别的降维手段。
在下图中(以下是程序截图,作者同样提供了一个交互程序),你可以看到三个方框。左边的最大,体现了一个表示空间,里面的每个点都对应了一个表示。这些点是通过对度量函数(类似上面的)扁平化后降维得到的。一种对这幅图像的解读方式是:表示之间的距离越近意味着,给定的表示之间,对于相似点的分类结果是一致的(译者注:比如存在两个不同的表示X和Y,存在两个(分类)相似数据点a和b,假如在图中XY的距离非常相近,那么在对XY可视化以后,ab在X中的距离和在Y中的距离都是非常近的),反之亦然。
然后,中间的方块是一种常见的对于MNIST的表示的可视化表达,就像我们前面提到的一样,当你把鼠标放在左边方框中的点上时,它会显示该店对应的表示。最后,当你鼠标放在中间方框中的某个点上时,右边的小方框显示的是该点所对应的MNIST字符。
这种可视化方式使我们可以从一个森林看到一棵树。
未完
0 0