GPU 共享内存地址映射方式
来源:互联网 发布:第三方数据公司 编辑:程序博客网 时间:2024/04/30 01:36
当一个warp中的不同线程访问一个bank中的不同的字地址时,就会发生bank冲突。
如果没有bank冲突的话,共享内存的访存速度将会非常的快,大约比全局内存的访问延迟低100多倍,但是速度没有寄存器快。然而,如果在使用共享内存时发生了bank冲突的话,性能将会降低很多很多。在最坏的情况下,即一个warp中的所有线程访问了相同bank的32个不同字地址的话,那么这32个访问操作将会全部被序列化,大大降低了内存带宽。
NOTE:不同warp中的线程之间不存在什么bank冲突。
共享内存的地址映射方式
要解决bank冲突,首先我们要了解一下共享内存的地址映射方式。
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的。下图中内存地址是按照箭头的方向依次映射的:
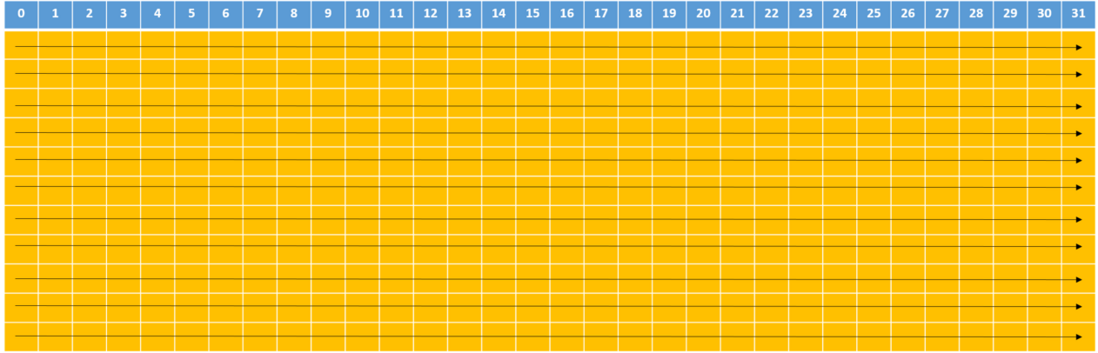
上图中数字为bank编号。这样的话,如果你将申请一个共享内存数组(假设是int类型)的话,那么你的每个元素所对应的bank编号就是地址偏移量(也就是数组下标)对32取余所得的结果,比如大小为1024的一维数组myShMem:
myShMem[4]: 对应的bank id为#4 (相应的行偏移量为0)
myShMem[31]: 对应的bank id为#31 (相应的行偏移量为0)
myShMem[50]: 对应的bank id为#18 (相应的行偏移量为1)
myShMem[128]: 对应的bank id为#0 (相应的行偏移量为4)
myShMem[178]: 对应的bank id为#18 (相应的行偏移量为5)
- GPU 共享内存地址映射方式
- GPU共享内存问题
- 内存映射,共享内存
- 地址映射与共享
- 地址映射与共享
- 地址映射与共享
- 地址映射与共享
- GPU共享内存小结---pycuda
- CreateFileMapping映射共享内存
- mmap 共享 内存映射
- 共享内存映射
- 共享内存(内存映射)
- 关于内存地址映射
- 内存地址映射
- Cache地址映射方式
- LINUX 内存映射方式
- 通过文件映射共享内存
- 共享内存映射2-理论
- 零度工作日记
- poj 3469 Dual Core CPU
- Java学习之方法重载
- 蓝桥杯 歌赛新规
- 自顶向下分析一个简单的语音识别系统(九)
- GPU 共享内存地址映射方式
- JAVA设计模式之原型模式
- bzoj 2300: [HAOI2011]防线修建
- HDU1269迷宫城堡(强连通分量)
- 小白学习Rxjava2,从零开始到实战(三) 操作符
- 使用Storm实现实时大数据分析
- 高德地图定位与导航
- Elasticsearch系列篇之创建document
- Linux系统nginx日志切割脚本


