强化学习进阶 第八讲 确定性策略方法
来源:互联网 发布:js date获取年月日 编辑:程序博客网 时间:2024/04/29 23:53
转载自知乎专栏 天津包子馅儿 的知乎
我们开始第八讲,确定性策略梯度的方法。要想完全理解本节课的内容,前面的内容一定要熟练掌握,另外本讲也假设读者对DQN网络很熟悉。若不熟的话可以看深度强化学习系列 第一讲 DQN - 知乎专栏。
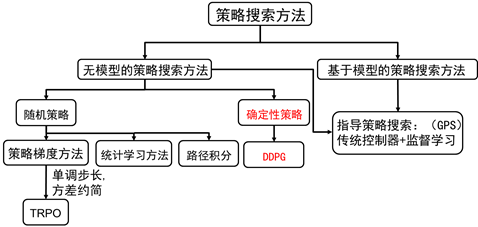
图8.1 策略搜索方法分类
我们还是从图8.1策略搜索方法的分类讲起。从图中我们可以看到,无模型的策略搜索方法可以分为随机策略搜索方法和确定性策略搜索方法。其中随机策略搜索方法又发展出了很多算法。可以说,差不多在2014年以前,学者们都在发展随机策略搜索的方法。因为,大家都认为确定性策略梯度是不存在的。直到2014年,强化学习算法大神Silver在论文《Deterministic Policy Gradient Algorithms》中提出了确定性策略理论,策略搜索方法中才出现确定性策略这个方法。2015年,DeepMind的大神们又将该理论跟DQN的成功经验结合起来,在论文《Continuous control with deep reinforcement learning》中提出DDPG的算法。本讲以这两篇论文为素材,给大家讲讲确定性策略
首先,我们讲讲什么是随机策略,什么是确定性策略。
随机策略的公式为:
(8.1)
其含义是,在状态s时,动作符合参数为的概率分布。比如常用的高斯策略:,当利用该策略进行采样时,在状态s处,采取的动作服从均值为 ,方差为 的正态分布。因此,我们可以总结说,采用随机策略时,即使在相同的状态,每次所采取的动作也很可能不一样。当然了,当采用高斯策略的时候,相同的策略,在同一个状态s处,采样的动作总体上看就算是不同,也差别不是很大,因为它们符合高斯分布,在均值附近的概率很大。
确定性策略的公式为:
(8.2)
跟随机策略不同,相同的策略(即相同时),在状态s时,动作是唯一确定的。
下面我们比较一下随机策略和确定性策略的优缺点。
确定性策略的优点:需要采样的数据少,算法效率高
首先,我们看一下随机策略,其梯度的计算公式为:
(8.3)
(8.3)表明,策略梯度公式是关于状态和动作的期望,在求期望时,需要对状态分布和动作分布进行求积分。这就要求在状态空间和动作空间采集大量的样本,这样求均值才能近似期望。
然而,确定性策略的动作是确定的,所以如果确定性策略梯度存在的化,策略梯度的求解不需要在动作空间进行采样积分。因此,相比于随机策略方法,确定性策略需要的样本数据要小。尤其是对那些动作空间很大的智能体,比如多关节机器人等,其动作空间维数很大。如果用随机策略,需要在这些动作空间中进行大量的采样。
通常来说,确定性策略方法的效率比随机策略的效率高十倍,这也是确定性策略方法最主要的优点。
相比于确定性策略,随机策略也有它自身的优点:随机策略将探索和改进集成到一个策略中
强化学习领域中的各路大神在过去十几年中乐忠于发展随机策略搜索方法也是有原因的。其中最重要的原因是随机策略本身自带探索,通过探索产生各种各样的数据,有好的数据,也有坏的数据,强化学习算法通过在这些好的数据中学到知识从而改进当前的策略。如图8.2所示,正是因为随机策略才产生了三条轨迹,这三条轨迹中有好的轨迹,通过向这些好的轨迹学习,策略可以得到快速改善。另外随机策略梯度理论也相对比较成熟,计算过程简单。
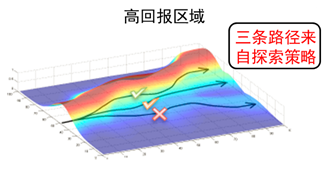
图8.2 随机策略学习过程
我们再回到确定性策略算法中。如公式(8.2)所示,给定状态s和策略参数时,动作是固定的。也就是说,当初试状态已知时,用确定性策略所产生的轨迹永远都是固定的,智能体无法探索其他的轨迹或访问其他的状态,从这个层面来说,智能体无法学习。我们知道,强化学习算法是通过智能体与环境交互来学习的。这里的交互是指探索性交互,即智能体会尝试很多动作,然后在这些动作中学到好的动作。
确定性策略无法探索环境,那么如何学习呢?
答案就是利用异策略学习方法,即off-policy. 异策略是指行动策略和评估策略不是一个策略。这里我们的行动策略是随机策略,以保证充足的探索。评估策略是确定性策略,即公式(8.2)。整个确定性策略的学习框架采用AC的方法。
这里再介绍下AC的方法,AC算法英文名为:Actor-Critic Algorithm. AC算法包括两个同等地位的元素,一个元素是Actor即行动策略,另一个元素是Critic, 即评估,这里是指利用函数逼近方法估计值函数。
我们先看看随机策略AC的方法是怎样的。
随机策略的梯度为:
如图8.3所示,其中Actor方法用来调整值; Critic方法逼近值函数:,其中为待逼近的参数,可用TD学习的方法对其进行评估。
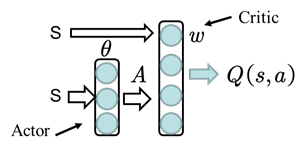
图8.3 AC方法网络结构
异策略随机策略梯度:
采样策略为.
为了给出确定性策略AC的方法,我们首先给出确定性策略梯度:
(8.5)
(8.5)即为确定性策略梯度。跟随机策略梯度(8.3)相比,少了对动作的积分,多了回报函数对动作的导数。
异策略确定性策略梯度为:
(8.6)
比较(8.6)和(8.4)我们发现,确定性策略梯度求解时少了重要性权重,这是因为重要性采样是用简单的概率分布区估计复杂的概率分布,而确定性策略的动作是确定值不是概率分布,另外确定性策略的值函数评估用的是Qlearning的方法,即用TD(0)来估计动作值函数并忽略重要性权重。
有了(8.6),我们便可以得到确定性策略异策略AC算法的更新过程了:
(8.7)
(8.7)的第一行和第二行是利用值函数逼近的方法更新值函数参数,第三行是利用确定性策略梯度的方法更新策略参数。
以上介绍的是确定性策略梯度方法,可以称为DPG的方法。有了DPG,我们再讲DDPG。
DDPG是深度确定性策略,所谓深度是指利用深度神经网络逼近行为值函数和确定性策略。
就像在DQN中讲的那样,当利用深度神经网络进行函数逼近的时候,强化学习算法常常不稳定。这是因为,对深度神经网络进行训练的时候往往假设输入的数据是独立同分布的,但强化学习的数据是顺序采集的,数据之间存在马尔科夫性,很显然这些数据并非独立同分布的。
为了打破数据之间的相关性,DQN用了两个技巧:经验回放和独立的目标网络。DDPG的算法便是将这两条技巧用到了DPG算法中。
DDPG的经验回放跟DQN完全相同,这里就不重复介绍了,忘记的同学可以去看之前的课程(深度强化学习系列 第一讲 DQN - 知乎专栏)。
这里我们重点介绍独立的目标网络。
DPG的更新过程如(8.7)所示,这里的目标值是(8.7)式中的第一行的前两项,即:
(8.8)
我们需要修改的就是(8.8)中的和,我们将这里的和单独拿出来,利用独立的网络对其进行更新。
DDPG的更新公式为:
最后,我们给出DDPG的伪代码:

图8.4 DDPG伪代码
- 强化学习进阶 第八讲 确定性策略方法
- 强化学习进阶 第六讲 策略梯度方法
- 强化学习进阶 第七讲 TRPO
- 强化学习基础 第三讲 蒙特卡罗方法
- 强化学习基础 第三讲 蒙特卡罗方法
- 强化学习入门第四讲 时间差分方法
- 强化学习入门第四讲 时间差分方法
- OpenAI详解进化策略方法:可替代强化学习
- 《强化学习》 第一讲 简介
- 深度强化学习--第一讲
- 强化学习之DP策略搜索
- 强化学习基本方法(一)
- 强化学习基本方法(二)
- 强化学习基本方法(三)
- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习入门第一讲 马尔科夫决策过程
- 强化学习入门 第五讲 值函数逼近
- 强化学习入门第一讲 马尔科夫决策过程
- JavaWeb编码处理——EncodingFilter
- 解析json数据巧记
- 对象3
- Android Intent信使使用
- 关于二叉树的所有操作
- 强化学习进阶 第八讲 确定性策略方法
- 对象4
- python爬取有关熊安新区的网易评论
- logback,logstash,elasticsearch配置,日志收集
- Java学习之使用Runtime.exec()启动、关闭Tomcat
- 如何解决Android中Hosts文件丢失或者说显示不了!(图解)
- 一个CTF工具分享站
- Treasure Exploration(POJ_2594) -有向图可重复点-最小路径覆盖
- 基于keras的二分类的网络训练代码


