弱分类器对Haar特征进行分类
来源:互联网 发布:苹果手机打不开淘宝 编辑:程序博客网 时间:2024/06/06 19:27
3. 再次介绍弱分类器以及为什么可以使用Haar特征进行分类
对于本算法中的矩形特征来说,弱分类器的特征值f(x)就是矩形特征的特征值。由于在训练的时候,选择的训练样本集的尺寸等于检测子窗口的尺寸,检测子窗口的尺寸决定了矩形特征的数量,所以训练样本集中的每个样本的特征相同且数量相同,而且一个特征对一个样本有一个固定的特征值。
对于理想的像素值随机分布的图像来说,同一个矩形特征对不同图像的特征值的平均值应该趋于一个定值k。
这个情况,也应该发生在非人脸样本上,但是由于非人脸样本不一定是像素随机的图像,因此上述判断会有一个较大的偏差。
对每一个特征,计算其对所有的一类样本(人脸或者非人脸)的特征值的平均值,最后得到所有特征对所有一类样本的平均值分布。
下图显示了20×20 子窗口里面的全部78,460 个矩形特征对全部2,706个人脸样本和4,381 个非人脸样本6的特征值平均数的分布图。由分布看出,特征的绝大部分的特征值平均值都是分布在0 前后的范围内。出乎意料的是,人脸样本与非人脸样本的分布曲线差别并不大,不过注意到特征值大于或者小于某个值后,分布曲线出现了一致性差别,这说明了绝大部分特征对于识别人脸和非人脸的能力是很微小的,但是存在一些特征及相应的阈值,可以有效地区分人脸样本与非人脸样本。
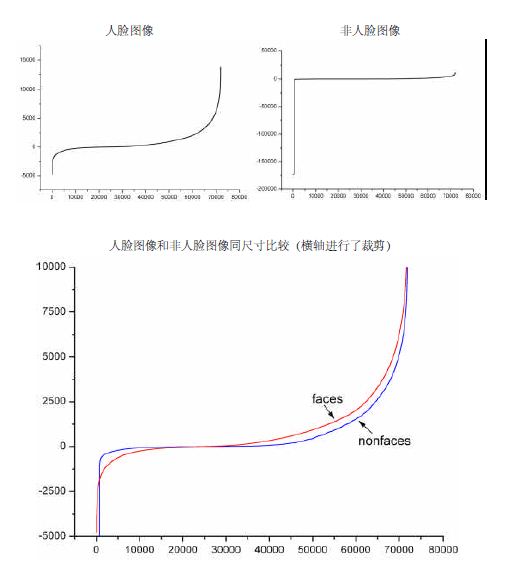
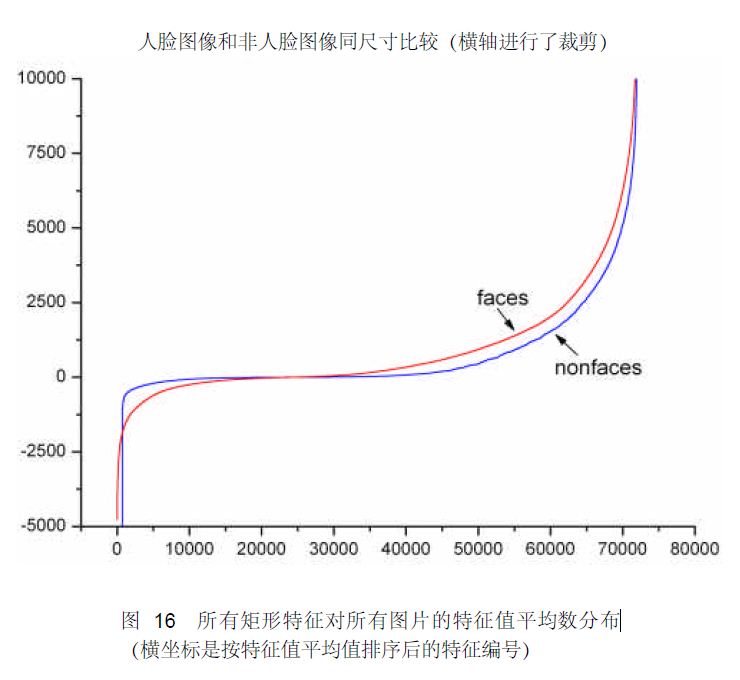
为了更好地说明问题,我们从78,460 个矩形特征中随机抽取了两个特征A和B,这两个特征遍历了2,706 个人脸样本和4,381 个非人脸样本,计算了每张图像对应的特征值,最后将特征值进行了从小到大的排序,并按照这个新的顺序表绘制了分布图如下所示:
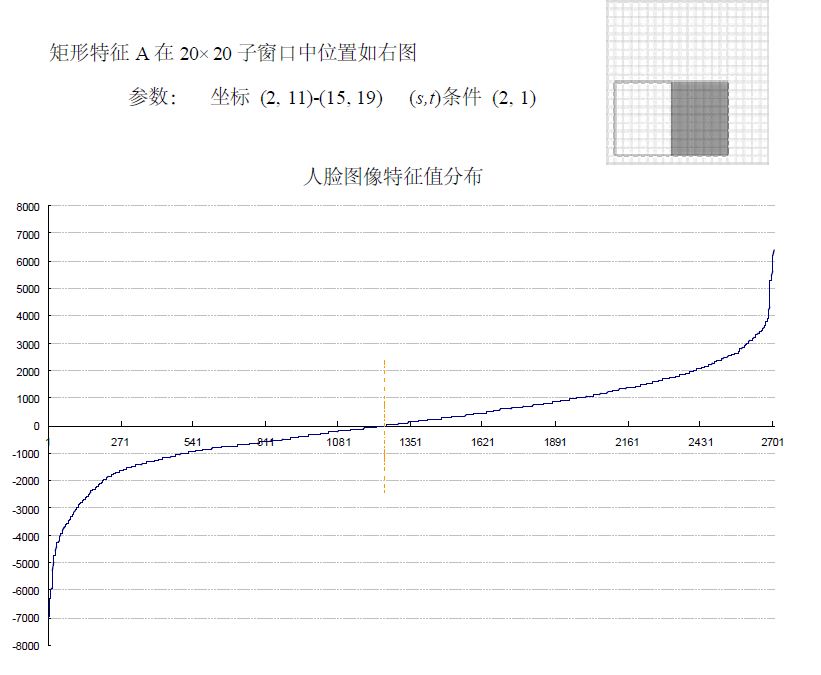

可以看出,矩形特征A在人脸样本和非人脸样本中的特征值的分布很相似,所以区分人脸和非人脸的能力很差。
下面看矩形特征B在人脸样本和非人脸样本中特征值的分布:
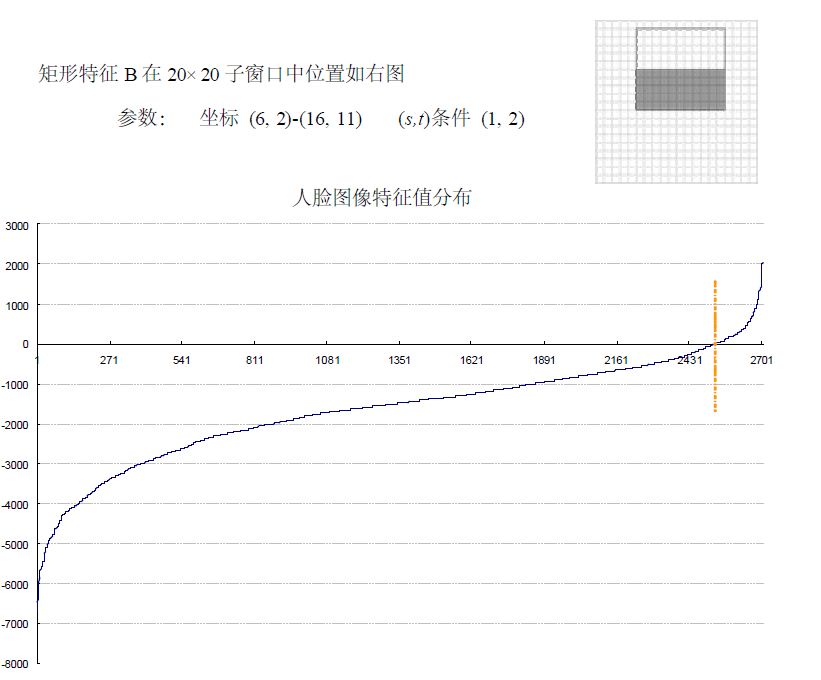
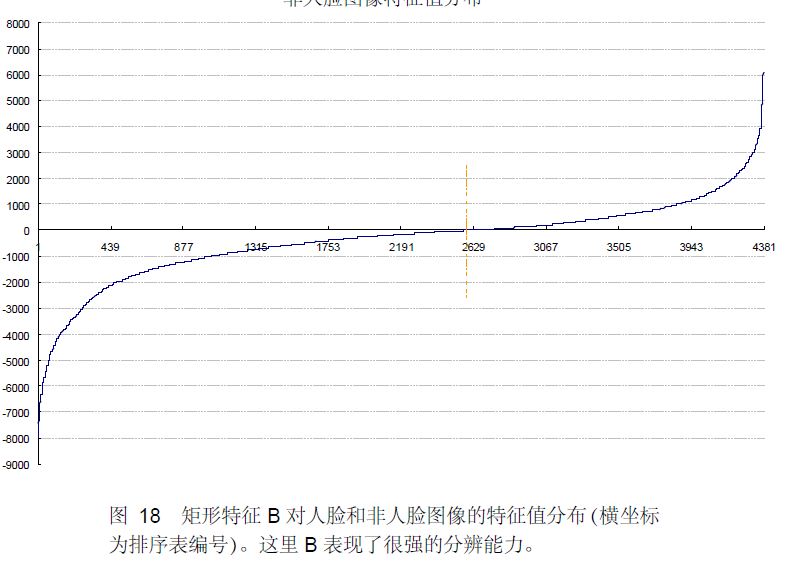
可以看出,矩形特征B的特征值分布,尤其是0点的位置,在人脸样本和非人脸样本中差别比较大,所以可以更好的实现对人脸分类。
由上述的分析,阈值q 的含义就清晰可见了。而方向指示符p 用以改变不等号的方向。
一个弱学习器(一个特征)的要求仅仅是:它能够以稍低于50%的错误率来区分人脸和非人脸图像,因此上面提到只能在某个概率范围内准确地进行区分就
已经完全足够。按照这个要求,可以把所有错误率低于50%的矩形特征都找到(适当地选择阈值,对于固定的训练集,几乎所有的矩形特征都可以满足上述要求)。每轮训练,将选取当轮中的最佳弱分类器(在算法中,迭代T 次即是选择T 个最佳弱分类器),最后将每轮得到的最佳弱分类器按照一定方法提升(Boosting)为强分类器
- 弱分类器对Haar特征进行分类
- Adaboost分类器 haar特征
- Adaboost分类器 haar特征 整理
- 用Haar特征训练分类器
- Adaboost分类器 haar特征 整理
- OpenCV Haar特征分类器的训练
- Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联
- 用opencv的traincascade.exe训练行人的HAAR、LBP和HOG特征的xml文件,并对分类器进行加载和检测
- Haar分类器 = Haar特征 + 积分图方法 + AdaBoost +级联强分类器
- Opencv Haar特征的鼻子分类器性能测试
- opencv之haar特征+AdaBoos分类器算法流程(二)
- opencv之haar特征+AdaBoos分类器算法流程(三)
- opencv训练分类器(HAAR,LBP等特征)
- 用HOG、LBP、Haar特征训练自己的分类器
- HAAR、LBP和HOG特征训练分类器
- 用haar特征训练自己的分类器
- 用haar特征训练自己的分类器
- Haar特征、积分图、Adaboost算法、分类器训练
- 算法----快排
- 13. Roman to Integer
- Java Servlet Filter过滤器
- 开发中常用到的标签
- 欢迎使用CSDN-markdown编辑器
- 弱分类器对Haar特征进行分类
- OpenCv+wxwidgets尝试
- parent > child
- 【第2期】量化大咖来了!带你探讨2017年A股套利机会
- MediaPlayer播放在线MP3资源时报出java.io.IOException: Prepare failed.: status=0x1异常
- 第7章 单例模式进阶
- 常见开源分布式存储系统
- Android Http和TCP协议编程
- DTW(Dynamic Time Warping)算法


