CNTK API文档翻译(3)——前馈神经网络
来源:互联网 发布:java date 编辑:程序博客网 时间:2024/05/29 04:20
这个教程的目的是为了让你熟悉使用CNTK组件来进行分类任务,如果你看了本系列的逻辑回归部分或者熟悉机器学习,可以跳过介绍部分。
介绍(见上期,本期略)
前馈神经网络模型
本次使用的数据集和上期逻辑回归教程使用的数据集一样,不过这期的模型会结合多个逻辑回归分类器,一次形成的分类边界就会比较复杂,而不是简单的线性模型,下图是我们的神经网络:

一个前馈神经网络是神经元之间不存在回路连接的人工神经网络,是神经网络领域的第一个也是最简单的人工神经网络,在这个网络中,数据沿一个方向传播:输入神经元通过隐藏神经元(如果有)到输出神经元,没有回路。
在本教程中,我们将使用模拟数据以不同的方式来完成上期说的五个步骤中的训练和测试模型。
# Import the relevant componentsfrom __future__ import print_functionimport matplotlib.pyplot as plt%matplotlib inlineimport numpy as npimport sysimport osimport cntk as Cfrom cntk import Trainer, learning_rate_schedule, UnitType, sgdfrom cntk.initializer import glorot_uniformfrom cntk.layers import default_options, Dense# Select the right target device when this notebook is being tested:if 'TEST_DEVICE' in os.environ: import cntk if os.environ['TEST_DEVICE'] == 'cpu': cntk.device.try_set_default_device(cntk.device.cpu()) else: cntk.device.try_set_default_device(cntk.device.gpu(0))数据生成(见上期,本期略)
模型创建
我们的前馈神经网络将有两个隐藏层,其中每个层有五十个神经元。
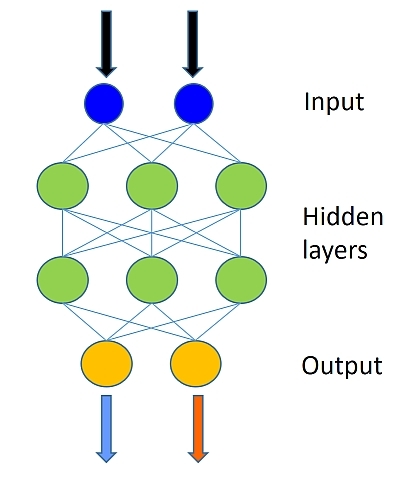
上图中每层绿色节点的数据设置为50,层数设置为2,分别使用变量num_hidden_layers和hidden_layers_dim表示。
num_hidden_layers = 2hidden_layers_dim = 50- 输入
# The input variable (representing 1 observation, in our example of age and size) $\bf{x}$ which # in this case has a dimension of 2. ## The label variable has a dimensionality equal to the number of output classes in our case 2. input = C.input(input_dim)label = C.input(num_output_classes)创建前馈神经网络
我们首先来定义前馈神经网络:输入层是m维输入向量(x),输出n(第一层隐藏层神经元个数)维向量到第一层隐藏层。每一个输入层的要素都通过权重连接到下一个图层,因此权重W应该是一个m×n的矩阵。所以第一步应该是计算第一层的值矩阵
其中b是n维向量,代表偏移量。
在linear_layer函数中,我们实现一下两部操作:
1. 让权重w和输入数据x相乘并把所有的输入数据的结果加起来
2. 加上偏移量b
def linear_layer(input_var, output_dim): input_dim = input_var.shape[0] weight = C.parameter(shape=(input_dim, output_dim)) bias = C.parameter(shape=(output_dim)) return bias + C.times(input_var, weight)下一步是把线性层的输出值使用一个非线性的函数(激活函数)转换成我们需要的数据(信号值)。Sigmoid函数和Tanh函数(Tanh函数详情可以阅读我的Python与人工神经网络第九期)都是比较流行的激活函数,这里我们会使用Sigmoid函数,Sigmoid函数的输出值通常会被用作下一个层或者输出层的输入值。
def dense_layer(input_var, output_dim, nonlinearity): l = linear_layer(input_var, output_dim) return nonlinearity(l)现在我们创建了一层隐藏层了,我们需要迭代一次,把第一个隐藏层的输出值当作下一个隐藏层的输出值(如果有多层就需要迭代多次,一下的代码是以多个隐藏层来写的)。
# Define a multilayer feedforward classification modeldef fully_connected_classifier_net(input_var, num_output_classes, hidden_layer_dim, num_hidden_layers, nonlinearity): h = dense_layer(input_var, hidden_layer_dim, nonlinearity) for i in range(1, num_hidden_layers): h = dense_layer(h, hidden_layer_dim, nonlinearity) return linear_layer(h, num_output_classes)- 输出
# Create the fully connected classfierz = fully_connected_classifier_net(input, num_output_classes, hidden_layers_dim, num_hidden_layers,C.sigmoid)上述的的神经网络是为了帮助我们理解如何使用原生的CNTK来构建神经网络,实际上如果使用层级库会更快和更方便,层级库提供了定义好的常用神经网络层来简化神经网络的设计。比如我们代码里面的dense_layer,就已经定义好了Dense 函数,用来组成我们的深度网络。我们可以直接传入输入变量,得到神经网络的输出值。
推荐任务:请你通读我们上述的模型定义部分和下面的create_model函数,证明下面的代码是对我们上面那么多代码的封装。
def create_model(features): with default_options(init=glorot_uniform(),activation=C.sigmoid): h = features for _ in range(num_hidden_layers): h = Dense(hidden_layers_dim)(h) last_layer = Dense(num_output_classes, activation = None) return last_layer(h)z = create_model(input)学习模型参数
现在神经网络创建好了,我们需要学习每一层的W和b,为了实现这点,我们跟上期一样,把输出层的输出值
训练(见上期,本期略)
评估/测试
现在我们完成了神经网络的训练,让我们使用一些在训练中没用过的数据来检验他一下,这叫测试。我们需要创建一些新数据,然后评估模型在他们上运行时候的平均成本函数值和差值。这在代码中使用trainer.test_minibatch完成。
# Generate new datatest_minibatch_size = 25features, labels = generate_random_data_sample(test_minibatch_size, input_dim, num_output_classes)trainer.test_minibatch({input : features, label : labels})运行代码会发现输出值error与我们训练时和的error值非常相近,表示我们的一般错误率还是很不错的,也就表示我们的模型对全新的数据表现也会很不错,这是避免过度拟合的关键。
我们处理了总体的误差,现在就需要生成每个样本在每个分类的概率了。eval函数将返回某个样本在所有分类的概率分布,如果你全程使用默认的参数,结果会是一个有两个元素的向量。首先让我们使用softmax函数将神经网络的输出值归一化。
out = C.softmax(z)让我们测试一下全新的数据:
predicted_label_probs = out.eval({input : features})print("Label :", [np.argmax(label) for label in labels])print("Predicted:", [np.argmax(row) for row in predicted_label_probs])Label : [1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1]
Predicted: [1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0, 1]
欢迎扫码关注我的微信公众号获取最新文章

- CNTK API文档翻译(3)——前馈神经网络
- CNTK API文档翻译(12)——CNTK进阶
- CNTK API文档翻译(7)——对MNIST数据使用卷积神经网络
- CNTK API文档翻译(17)——多对多神经网络处理文本数据(1)
- CNTK API文档翻译(18)——多对多神经网络处理文本数据(2)
- CNTK API文档翻译(17)——多对多神经网络处理文本数据(1)
- CNTK API文档翻译(1)——使用数列
- CNTK API文档翻译(2)——逻辑回归
- CNTK API文档翻译(4)——MNIST数据加载
- CNTK API文档翻译(14)——实验图像识别
- CNTK API文档翻译(15)——自然语言理解
- CNTK API文档翻译(16)——增强学习基础
- CNTK API文档翻译(19)——艺术风格转变
- CNTK API文档翻译(22)——取样Softmax函数
- CNTK API文档翻译(25)——后记
- CNTK API文档翻译(5)——对MNIST数据使用逻辑回归
- CNTK API文档翻译(6)——对MNIST数据使用多层感知机
- CNTK API文档翻译(9)——使用自编码器压缩MNIST数据
- linux高级I/O函数splice与tee
- thinkphp3.1验证码输出乱码问题
- 解析及注册BeanDefinitions。
- 写后端增删改查时所遇到的相关注解
- 35STL之算法基础
- CNTK API文档翻译(3)——前馈神经网络
- shell工具篇之sed
- Floyd--景点寻路
- EJB系列
- sso 原理详解
- jquery的DOM节点获取,节点内容获取和设置,样式写入
- java中的El表达式 与jstl标签库
- 索引分析
- java:15-抽象类与内部类


