CNTK API文档翻译(14)——实验图像识别
来源:互联网 发布:mysql服务占多大内存 编辑:程序博客网 时间:2024/05/29 04:50
这个动手实验展示了如何使用CNTK Python API中的卷积神经网络实现图像识别。本教程将从最简单的前馈卷积神经网络实现CIFAR数据集分类开始,之后会一点点的往我们的神经网络里面加入高级特性。最后你将实现一个VGG神经网络和残差神经网络(Residual Network),就想赢得ImageNet比赛的神经网络一样,只不过规模更小。
介绍
在本次实验中,你将练习如下类容:
- 理解CNTK中用于图像分类的一些API
- 写一个用于CIFAR数据分类的卷积神经网络。
- 通过添加如下内容改变神经网络的结构:
- 舍弃层(Dropout layer)
- 批量规范层(Batchnormalization laye)
- 实现一个VGG式的神经网络
- 介绍残差网络
- 实现和训练残差网络
准备
完成上一期的数据下载和数据准备工作是本期的教程的前提。本教程使用CNTK API V2.0,在做之前需要先安装CNTK 2.0。另外所有这些教程都是使用Python完成的,因此需要对Python有一个基本的了解。
在学习本教程之前,建议先学习本教程的第三期,不过并不是必须的。不管怎样,对深度学习有个基本的了解是有必要的,如果了解卷积操作就更好了。
数据集
我们将使用来自https://www.cs.toronto.edu/~kriz/cifar.html的CIFAR 10数据集,在本教程完成时,这个数据集包含50000个训练图片和10000个测试图片,所有的图片都是32×32×3的。每一张图片都已经被分好了一个类别,如下所示: 
上图来自:https://www.cs.toronto.edu/~kriz/cifar.html
卷积神经网络
我们建议你在开始本教程之前学完本系列教程的第七期。这里是一个关于卷积神经网络(CNN,Convolution Neural Network)的简短介绍。卷积神经网络是由一些列网络层组成的一种前馈神经网络,其中上一层的输出结果就是下一层的输入数据(部分复杂的结构会跳过一些层,我们会在本教程的结尾接触到)。一般来说,卷积神经网络前几个层都是卷积层和池化层交替出现的,结尾会是一个全连接层,用来分类。
卷积层
卷积层一般由多个2D卷积核组成,用来对输入图像或者上一层进行卷积计算,每个卷积核输出一个特征映射。 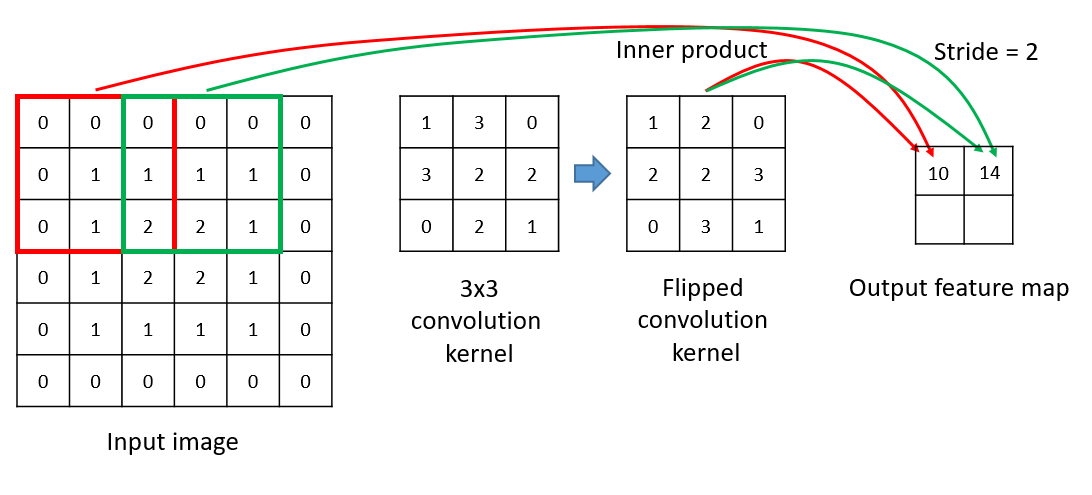
所有卷积核输出的特征映射组合起来,就是下一层的输入值。 
引用文献:Gradient-Based Learning Applied to Document Recognition, Proceedings of the IEEE, 86(11):2278-2324, November 1998 Y. LeCun, L. Bottou, Y. Bengio and P. Haffner
CNTK API
在CNTK Python API里面,卷积层表示如下:
def Convolution(filter_shape, # e.g. (3,3) num_filters, # e.g. 64 activation, # relu or None...etc. init, # Random initialization pad, # True or False strides) # strides e.g. (1,1)池化层
在大多数卷积神经网络视觉架构中,每个卷积层都会跟着一个池化层,他们保持交替出现,直到全连接层。
池化层的作用如下:
- 减少上一个层的大小,加快网络速度。
- 控制变量个数。
下图是一个步幅为2的最大只池化层的例子。 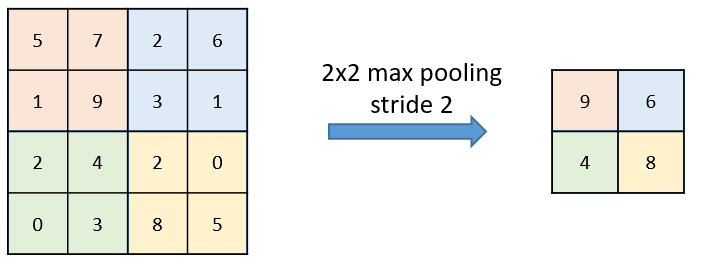
CNTK API
在CNTK Python API里面,池化层如下表示。
# Max poolingdef MaxPooling(filter_shape, # e.g. (3,3) strides, # (2,2) pad) # True or False# Average poolingdef AveragePooling(filter_shape, # e.g. (3,3) strides, # (2,2) pad) # True or False舍弃层
舍弃层有一个舍弃率参数,打个比方是0.5,则舍弃层从上一个图层中随机摘50%的节点,把他们舍弃掉,这是神经网络正则化的一种方式。
舍弃:一种防止神经网络过度拟合的简单方法——Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, Ruslan Salakhutdinov(我猜应该是来自他们联合发表的论文)
CNTK API
在CNTK Python API里面,舍弃层如下表示:
# Dropoutdef Dropout(prob) # dropout rate e.g. 0.5批量规范化(BN,Batch normalization)
批量规范是一种使每一层的输入数据的平均值是0,方差是1的方法。批量规范化让神经网络更快的收敛,让每一层的输入值都与0相差不远。批量规范话有两个需要训练的参数,分别是γ和β,神经网络通过这个参数来判定批量规范层表现是否OK。
批量规范化:通过减少内部协变量来加速深度神经网络的训练——Shift Sergey Ioffe, Christian Szegedy
CNTK API
在CNTK Python API里面,批量规范层如下表示:
# Batch normalizationdef BatchNormalization(map_rank) # For image map_rank=1CNTK
CNTK是一个高度灵活的计算图谱,其中的每个节点以张量为输入值,计算结果也输出成张量。图谱中的每个节点都使用Python API开放了出来,因此你可以灵活的使用API来创造自己的计算图谱。当然你也可以使用Python或者C++定义自己的节点,在CPU、GPU或者两者上运算。
在进行深度学习时,你可以使用CNTK底层API也可以直接使用CNTK网络层API,在本教程中我们开始使用底层API,最后改成网络层API。
我们先引入我们需要的模块。
# Use a function definition from future version (say 3.x from 2.7 interpreter)from __future__ import print_function import matplotlib.pyplot as pltimport mathimport numpy as npimport osimport PILimport systry: from urllib.request import urlopen except ImportError: from urllib import urlopenimport cntk as C在下面的代码中,我们通过检查在CNTK内部定义的环境变量来选择正确的设备(GPU或者CPU)来运行代码,如果不检查的话,会使用CNTK的默认策略来使用最好的设备(如果GPU可用的话就使用GPU,否则使用CPU)
if 'TEST_DEVICE' in os.environ: if os.environ['TEST_DEVICE'] == 'cpu': C.device.try_set_default_device(C.device.cpu()) else: C.device.try_set_default_device(C.device.gpu(0))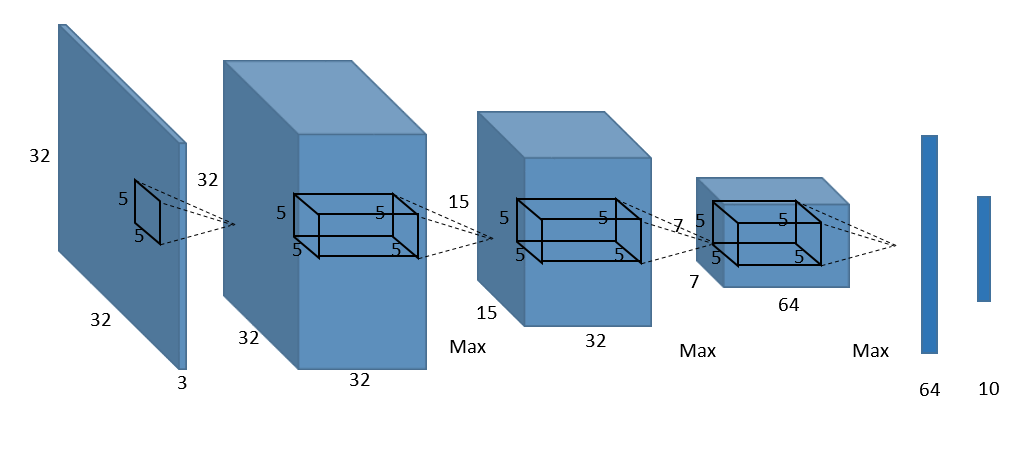
现在我们开始使用CNTK网络层API实现如上图所示的卷积神经网络。
def create_basic_model(input, out_dims): with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu): net = C.layers.Convolution((5,5), 32, pad=True)(input) net = C.layers.MaxPooling((3,3), strides=(2,2))(net) net = C.layers.Convolution((5,5), 32, pad=True)(net) net = C.layers.MaxPooling((3,3), strides=(2,2))(net) net = C.layers.Convolution((5,5), 64, pad=True)(net) net = C.layers.MaxPooling((3,3), strides=(2,2))(net) net = C.layers.Dense(64)(net) net = C.layers.Dense(out_dims, activation=None)(net) return net为了训练上面定义的模型,我们需要做两件事:
- 读取训练图像和他们相对应的标签
- 定义成本函数,计算每一个取样包的成本值并以此更新模型参数。
文件格式如下示例:
S:\data\CIFAR-10\train\00001.png 9
S:\data\CIFAR-10\train\00002.png 9
S:\data\CIFAR-10\train\00003.png 4
S:\data\CIFAR-10\train\00004.png 1
S:\data\CIFAR-10\train\00005.png 1
# Determine the data path for testing# Check for an environment variable defined in CNTK's test infrastructureenvvar = 'CNTK_EXTERNAL_TESTDATA_SOURCE_DIRECTORY'def is_test(): return envvar in os.environif is_test(): data_path = os.path.join(os.environ[envvar],'Image','CIFAR','v0','tutorial201') data_path = os.path.normpath(data_path)else: data_path = os.path.join('data', 'CIFAR-10')# model dimensionsimage_height = 32image_width = 32num_channels = 3num_classes = 10import cntk.io.transforms as xforms ## Define the reader for both training and evaluation action.#def create_reader(map_file, mean_file, train): print("Reading map file:", map_file) print("Reading mean file:", mean_file) if not os.path.exists(map_file) or not os.path.exists(mean_file): raise RuntimeError("This tutorials depends 201A tutorials, please run 201A first.") # transformation pipeline for the features has jitter/crop only when training transforms = [] # train uses data augmentation (translation only) if train: transforms += [ xforms.crop(crop_type='randomside', side_ratio=0.8) ] transforms += [ xforms.scale(width=image_width, height=image_height, channels=num_channels, interpolations='linear'), xforms.mean(mean_file) ] # deserializer return C.io.MinibatchSource(C.io.ImageDeserializer(map_file, C.io.StreamDefs( # first column in map file is referred to as 'image' features = C.io.StreamDef(field='image', transforms=transforms), # and second as 'label' labels = C.io.StreamDef(field='label', shape=num_classes) )))# Create the train and test readersreader_train = create_reader(os.path.join(data_path, 'train_map.txt'), os.path.join(data_path, 'CIFAR-10_mean.xml'), True)reader_test = create_reader(os.path.join(data_path, 'test_map.txt'), os.path.join(data_path, 'CIFAR-10_mean.xml'), False) 现在让我们写训练和验证循环逻辑。
## Train and evaluate the network.#def train_and_evaluate(reader_train, reader_test, max_epochs, model_func): # Input variables denoting the features and label data input_var = C.input_variable((num_channels, image_height, image_width)) label_var = C.input_variable((num_classes)) # Normalize the input feature_scale = 1.0 / 256.0 input_var_norm = C.element_times(feature_scale, input_var) # apply model to input z = model_func(input_var_norm, out_dims=10) # # Training action # # loss and metric ce = C.cross_entropy_with_softmax(z, label_var) pe = C.classification_error(z, label_var) # training config epoch_size = 50000 minibatch_size = 64 # Set training parameters lr_per_minibatch = C.learning_rate_schedule([0.01]*10 + [0.003]*10 + [0.001], C.UnitType.minibatch, epoch_size) momentum_time_constant = C.momentum_as_time_constant_schedule(-minibatch_size/np.log(0.9)) l2_reg_weight = 0.001 # trainer object learner = C.momentum_sgd(z.parameters, lr = lr_per_minibatch, momentum = momentum_time_constant, l2_regularization_weight=l2_reg_weight) progress_printer = C.logging.ProgressPrinter(tag='Training', num_epochs=max_epochs) trainer = C.Trainer(z, (ce, pe), [learner], [progress_printer]) # define mapping from reader streams to network inputs input_map = { input_var: reader_train.streams.features, label_var: reader_train.streams.labels } C.logging.log_number_of_parameters(z) ; print() # perform model training batch_index = 0 plot_data = {'batchindex':[], 'loss':[], 'error':[]} # loop over epochs for epoch in range(max_epochs): sample_count = 0 # loop over minibatches in the epoch while sample_count < epoch_size: # fetch minibatch. data = reader_train.next_minibatch(min(minibatch_size, epoch_size - sample_count), input_map=input_map) # update model with it trainer.train_minibatch(data) # count samples processed so far sample_count += data[label_var].num_samples # For visualization... plot_data['batchindex'].append(batch_index) plot_data['loss'].append(trainer.previous_minibatch_loss_average) plot_data['error'].append(trainer.previous_minibatch_evaluation_average) batch_index += 1 trainer.summarize_training_progress() # # Evaluation action # epoch_size = 10000 minibatch_size = 16 # process minibatches and evaluate the model metric_numer = 0 metric_denom = 0 sample_count = 0 minibatch_index = 0 while sample_count < epoch_size: current_minibatch = min(minibatch_size, epoch_size - sample_count) # Fetch next test min batch. data = reader_test.next_minibatch(current_minibatch, input_map=input_map) # minibatch data to be trained with metric_numer += trainer.test_minibatch(data) * current_minibatch metric_denom += current_minibatch # Keep track of the number of samples processed so far. sample_count += data[label_var].num_samples minibatch_index += 1 print("") print("Final Results: Minibatch[1-{}]: errs = {:0.1f}% * {}".format(minibatch_index+1, (metric_numer*100.0)/metric_denom, metric_denom)) print("") # Visualize training result: window_width = 32 loss_cumsum = np.cumsum(np.insert(plot_data['loss'], 0, 0)) error_cumsum = np.cumsum(np.insert(plot_data['error'], 0, 0)) # Moving average. plot_data['batchindex'] = np.insert(plot_data['batchindex'], 0, 0)[window_width:] plot_data['avg_loss'] = (loss_cumsum[window_width:] - loss_cumsum[:-window_width]) / window_width plot_data['avg_error'] = (error_cumsum[window_width:] - error_cumsum[:-window_width]) / window_width plt.figure(1) plt.subplot(211) plt.plot(plot_data["batchindex"], plot_data["avg_loss"], 'b--') plt.xlabel('Minibatch number') plt.ylabel('Loss') plt.title('Minibatch run vs. Training loss ') plt.show() plt.subplot(212) plt.plot(plot_data["batchindex"], plot_data["avg_error"], 'r--') plt.xlabel('Minibatch number') plt.ylabel('Label Prediction Error') plt.title('Minibatch run vs. Label Prediction Error ') plt.show() return C.softmax(z)pred = train_and_evaluate(reader_train, reader_test, max_epochs=5, model_func=create_basic_model)看看我们训练结果可视化的图片。 

当然,上面的代码还太简单,我们可以加更多的代码让他表现的更好。我们先使用更凝炼的代码实现上面的模型。
def create_basic_model_terse(input, out_dims): with C.layers.default_options(init=C.glorot_uniform(), activation=C.relu): model = C.layers.Sequential([ C.layers.For(range(3), lambda i: [ C.layers.Convolution((5,5), [32,32,64][i], pad=True), C.layers.MaxPooling((3,3), strides=(2,2)) ]), C.layers.Dense(64), C.layers.Dense(out_dims, activation=None) ]) return model(input)pred_basic_model = train_and_evaluate(reader_train, reader_test, max_epochs=10, model_func=create_basic_model_terse)现在我们已经训练好了这个模型,让我们来对下面这个卡车的图片分类。我们使用PIL(Python Imaging Library)读取这个图像。 
# Download a sample image # (this is 00014.png from test dataset)# Any image of size 32,32 can be evaluatedurl = "https://cntk.ai/jup/201/00014.png"myimg = np.array(PIL.Image.open(urlopen(url)), dtype=np.float32)在训练时,我们减掉了图像像素值的平均值,现在我们也要取一个平均值的近似值,把他减掉。
def eval(pred_op, image_data): label_lookup = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"] image_mean = 133.0 image_data -= image_mean image_data = np.ascontiguousarray(np.transpose(image_data, (2, 0, 1))) result = np.squeeze(pred_op.eval({pred_op.arguments[0]:[image_data]})) # Return top 3 results: top_count = 3 result_indices = (-np.array(result)).argsort()[:top_count] print("Top 3 predictions:") for i in range(top_count): print("\tLabel: {:10s}, confidence: {:.2f}%".format(label_lookup[result_indices[i]], result[result_indices[i]] * 100))# Run the evaluation on the downloaded imageeval(pred_basic_model, myimg)结果:
Top 3 predictions: Label: truck , confidence: 96.59% Label: ship , confidence: 2.31% Label: cat , confidence: 0.43%在最后一个全连接层上加上舍弃层,舍弃率0.25。
def create_basic_model_with_dropout(input, out_dims): with C.layers.default_options(activation=C.relu, init=C.glorot_uniform()): model = C.layers.Sequential([ C.layers.For(range(3), lambda i: [ C.layers.Convolution((5,5), [32,32,64][i], pad=True), C.layers.MaxPooling((3,3), strides=(2,2)) ]), C.layers.Dense(64), C.layers.Dropout(0.25), C.layers.Dense(out_dims, activation=None) ]) return model(input)pred_basic_model_dropout = train_and_evaluate(reader_train, reader_test, max_epochs=5, model_func=create_basic_model_with_dropout)结果数据可视化如下: 

在每层卷积层后以及最后的全连接层之前添加批量标准化层:
def create_basic_model_with_batch_normalization(input, out_dims): with C.layers.default_options(activation=C.relu, init=C.glorot_uniform()): model = C.layers.Sequential([ C.layers.For(range(3), lambda i: [ C.layers.Convolution((5,5), [32,32,64][i], pad=True), C.layers.BatchNormalization(map_rank=1), C.layers.MaxPooling((3,3), strides=(2,2)) ]), C.layers.Dense(64), C.layers.BatchNormalization(map_rank=1), C.layers.Dense(out_dims, activation=None) ]) return model(input)pred_basic_model_bn = train_and_evaluate(reader_train, reader_test, max_epochs=5, model_func=create_basic_model_with_batch_normalization)

让我们使用CNTK网络层API来实现一个VGG式的神经网络,下面是网络结构。(解释:从上到下表示层级吮吸,conv表示卷积层,3表示图片的三个色彩通道,64表示64×64,max表示最大值池化层,FC表示全连接层)
def create_vgg9_model(input, out_dims): with C.layers.default_options(activation=C.relu, init=C.glorot_uniform()): model = C.layers.Sequential([ C.layers.For(range(3), lambda i: [ C.layers.Convolution((3,3), [64,96,128][i], pad=True), C.layers.Convolution((3,3), [64,96,128][i], pad=True), C.layers.MaxPooling((3,3), strides=(2,2)) ]), C.layers.For(range(2), lambda : [ C.layers.Dense(1024) ]), C.layers.Dense(out_dims, activation=None) ]) return model(input)pred_vgg = train_and_evaluate(reader_train, reader_test, max_epochs=5, model_func=create_vgg9_model)

残差神经网络(ResNet,Residual Network )
深度神经网络面临的主要问题之一是如何在梯度下降时将最后一层的误差值传递到第一层。在深度神经网络中,梯度会随着层级的升高一点点减少,知道对网络没有影响。残差神经网络就是通过定义特定的映射路径来解决这个问题,如图。 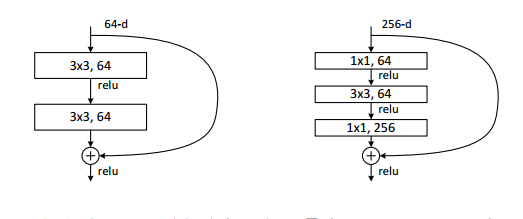
上面展示的块是两个折叠式结构:
- 反向传播时,梯度有直接到上层的路径而不改变其两级。
- 但是这种直接映射明显不是最优解,因此这种映射与最优解之前有一个残差,所以需要计算残差映射。
让我们实现残差网络块: 
def convolution_bn(input, filter_size, num_filters, strides=(1,1), init=C.he_normal(), activation=C.relu): if activation is None: activation = lambda x: x r = C.layers.Convolution(filter_size, num_filters, strides=strides, init=init, activation=None, pad=True, bias=False)(input) r = C.layers.BatchNormalization(map_rank=1)(r) r = activation(r) return rdef resnet_basic(input, num_filters): c1 = convolution_bn(input, (3,3), num_filters) c2 = convolution_bn(c1, (3,3), num_filters, activation=None) p = c2 + input return C.relu(p)def resnet_basic_inc(input, num_filters): c1 = convolution_bn(input, (3,3), num_filters, strides=(2,2)) c2 = convolution_bn(c1, (3,3), num_filters, activation=None) s = convolution_bn(input, (1,1), num_filters, strides=(2,2), activation=None) p = c2 + s return C.relu(p)def resnet_basic_stack(input, num_filters, num_stack): assert (num_stack > 0) r = input for _ in range(num_stack): r = resnet_basic(r, num_filters) return r所以整个模型是:
def create_resnet_model(input, out_dims): conv = convolution_bn(input, (3,3), 16) r1_1 = resnet_basic_stack(conv, 16, 3) r2_1 = resnet_basic_inc(r1_1, 32) r2_2 = resnet_basic_stack(r2_1, 32, 2) r3_1 = resnet_basic_inc(r2_2, 64) r3_2 = resnet_basic_stack(r3_1, 64, 2) # Global average pooling pool = C.layers.AveragePooling(filter_shape=(8,8), strides=(1,1))(r3_2) net = C.layers.Dense(out_dims, init=C.he_normal(), activation=None)(pool) return netpred_resnet = train_and_evaluate(reader_train, reader_test, max_epochs=5, model_func=create_resnet_model)训练结果可视化: 

欢迎扫码关注我的微信公众号获取最新文章

- CNTK API文档翻译(14)——实验图像识别
- CNTK API文档翻译(24)——使用深度迁移学习进行图像识别
- CNTK API文档翻译(12)——CNTK进阶
- CNTK API文档翻译(1)——使用数列
- CNTK API文档翻译(2)——逻辑回归
- CNTK API文档翻译(3)——前馈神经网络
- CNTK API文档翻译(4)——MNIST数据加载
- CNTK API文档翻译(15)——自然语言理解
- CNTK API文档翻译(16)——增强学习基础
- CNTK API文档翻译(19)——艺术风格转变
- CNTK API文档翻译(22)——取样Softmax函数
- CNTK API文档翻译(25)——后记
- CNTK API文档翻译(5)——对MNIST数据使用逻辑回归
- CNTK API文档翻译(6)——对MNIST数据使用多层感知机
- CNTK API文档翻译(7)——对MNIST数据使用卷积神经网络
- CNTK API文档翻译(9)——使用自编码器压缩MNIST数据
- CNTK API文档翻译(10)——使用LSTM预测时间序列数据
- CNTK API文档翻译(13)——CIFAR-10数据准备
- mysql代码自动生成器
- Linux/Centos下/lib64/libc.so.6: version `GLIBC_2.14' not found问题
- 京东JS面试题
- day23之数组循环右移k位+去除重复的字符。
- Java8 Stream的筛选和切片
- CNTK API文档翻译(14)——实验图像识别
- 浅谈JS中正则表达式(RegExp)的使用
- bzoj1677 [Usaco2005 Jan]Sumsets 求和(递推)
- 内存泄露从入门到精通三部曲之基础知识篇
- Linux内核中Netfilter架构介绍
- 进程间通信——信号量
- iOS Swift print了解和不换行
- TCP流量控制与拥塞控制浅析
- JQuery实现 任务清单案例


