Java8 LinkedList源码分析
来源:互联网 发布:vb.net chart控件使用 编辑:程序博客网 时间:2024/06/05 10:52
学习动机
Java Collection库中有三类:List,Queue,Set;而List接口,有三个子实现类:ArrayList,Vector,LinkedList。
LinkedList采用的双向链表结构,和ArrayList的数组结构不同,链表结构的优势就是便于大量的数据添加和删除,但对于ArrayList擅长的数据查询则并非擅长。
本文进行LinkedList源码的分析。
构造&成员属性
成员变量
//容器的size transient int size = 0; //类似于指针,记录着链表的第一个数据 transient Node<E> first; //连边的最后一个数据 transient Node<E> last;看一下Node的内部:
private static class Node<E> { E item;//存储的数据 Node<E> next;//指向链表的下一个数据 Node<E> prev;//链表的前一个数据 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}我们可以看到,LinkedList的内部实际上是有若干个相连的Node节点组成的,每个Node节点都包含着该节点的数据、前一个节点、后一个节点。、
构造方法如下:
public LinkedList() {}public LinkedList(Collection<? extends E> c) { this(); addAll(c);}构造方法很简单,第二个构造中传入了一个Collection集合,也只是执行了addAll(c)方法。
add()方法分析
准备
照常理我们要尝试分析add()相关方法了,在这之前我们先看一下几个核心的元素插入方法:
private void linkFirst(E e)
void linkLast(E e)
void linkBefore(E e, Node succ)
//将数据作为FirstNode插入链表 private void linkFirst(E e) { //取得链表第一个元素 final Node<E> f = first; //初始化数据,新建一个Node对象,该对象中数据为要插入的新数据 //同时,该数据的前一个节点为null(当然因为它是首个节点) //该数据的后一个节点为之前的first节点 final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) //如果之前的首个节点(现在应该是第二个)为空,说明执行该插入操作前,链表为空 //新节点既是首节点,也是尾节点(因为现在链表元素size = 1) last = newNode; else //否则说明之前不是空链表 //之前的首个节点的前一个节点变成新的首节点 f.prev = newNode; size++; modCount++; } //将数据作为LastNode插入链表 void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; } //将数据插入到某个链表节点之前 void linkBefore(E e, Node<E> succ) { // assert succ != null; final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }理解任意一个核心方法,剩下两个方法也就不难理解了,我们以linkBefore为例:
步骤1:执行linkBefore时,LinkedList的数据结构

步骤2:执行final Node newNode = new Node<>(pred, e, succ);

步骤3:执行pred.next = newNode;

add()方法
public boolean add(E e) { //其实只是执行linkLast方法将数据添加到链表末尾 linkLast(e); return true;}public void add(int index, E element) { checkPositionIndex(index); //将元素插入,也是执行了linklast或linkBefore方法 if (index == size) linkLast(element); else linkBefore(element, node(index));}//将Collection中元素插入LinkedList最后public boolean addAll(Collection<? extends E> c) { //如果我们在构造中传入一个Collection,实际会走下面的代码 return addAll(size, c);}//将Collection中元素插入LinkedList指定indexpublic boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index);//检查是否越界,若越界抛出IndexOutOfBoundsException异常 //先将集合转化为数组 Object[] a = c.toArray(); int numNew = a.length; //如果数组为空,返回false,方法执行结束 if (numNew == 0) return false; Node<E> pred, succ; if (index == size) { //说明是通过构造初始化链表,此时链表中数据为空 succ = null;//succ: 索引位置从指定集合插入的第一个元素 pred = last;//pred: 插入数组的第一个元素节点 } else { //node(index)方法是获取对应index的Node对象 succ = node(index); pred = succ.prev; } //将数组中元素转换为一个链表,pred永远代表第一个Node节点 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } //将新的链表插入原有链表 if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; } //size修改,修改次数modCount++ size += numNew; modCount++; return true;}add相关方法基本就这些,当然还有两个简单的,特此列出,不赘述:
public void addFirst(E e) { linkFirst(e);}public void addLast(E e) { linkLast(e);}remove代码分析
先看一下remove相关的核心方法:
//删除第一个节点private E unlinkFirst(Node<E> f) { final E element = f.item; final Node<E> next = f.next; f.item = null; f.next = null; // help GC first = next; if (next == null) last = null; else next.prev = null; size--; modCount++; return element;}//删除last节点private E unlinkLast(Node<E> l) { final E element = l.item; final Node<E> prev = l.prev; l.item = null; l.prev = null; // help GC last = prev; if (prev == null) first = null; else prev.next = null; size--; modCount++; return element;}//删除某个节点E unlink(Node<E> x) { // 临时保存移除对象的所有数据(prev和next指针以及存储数据) final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; //prev指针为null,则说明该对象为头节点 if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } //next指针为null,则说明该对象为尾节点 if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element;}同样理解任意一个核心方法,剩下两个方法也就不难理解了,我们以unlink(Node x)为例:
步骤1:执行remove操作前的数据结构

步骤2:执行prev指针相关

步骤3:执行next指针相关

remove代码分析
//按index删除节点很简单,node方法获取到对应的元素,然后unlink删除即可public E remove(int index) { checkElementIndex(index); return unlink(node(index));}//按对象删除,依次遍历链表,然后找到首个符合的元素,然后删除该元素public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false;}//同样没啥好说的,移除第一个Nodepublic E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f);}//移除最后一个Nodepublic E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l);}node(int index)
我们来看一看node方法是如何找到对应index的元素节点的:
Node<E> node(int index) { if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; }}可以看到,类似于二分查找法,第一次查找根据index判断是从头部还是尾部获取对应元素,相对于数组结构,性能还是有所欠缺。
小结
优点:
LinkedList没有大小限制
没有浪费存储空间(Node节点的创建需要额外消耗少量空间)
add,remove等操作的空间消耗是固定的,不会造成对元素进行额外的移动拷贝
缺点:
除了对首尾元素外,对其他节点,进行add,remove,set,get等操作,都需要进行遍历查找的,时间复杂度为O(n)
应用场景
查询操作少,存储大量数据,可以考虑使用LinkedList
多线程下:
LinkedList和ArrayList一样,都不是线程安全的。
在考虑线程安全的情况下,可以使用 ConcurrentLinkedQueue代替LinkedList,直接同步LinkedList对象,或者使用
List list = Collections.synchronizedList(new LinkedList(…));
对比ArrayList
ArrayList和LinkedList的大致区别如下:
* 1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
* 2.对于随机访问get和set,ArrayList优于LinkedList,因为LinkedList要移动指针遍历查找。
* 3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
当我们在集合中装5万条数据,测试运行结果如下:
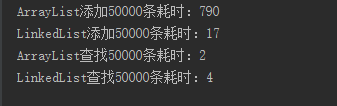
显然我们可以看出ArrayList更适合读取数据,linkedList更多的时候添加或删除数据。
ArrayList内部是使用可増长数组实现的,所以是用get和set方法是花费常数时间的,但是如果插入元素和删除元素,除非插入和删除的位置都在表末尾,否则代码开销会很大,因为里面需要数组的移动。
LinkedList是使用双链表实现的,所以get会非常消耗资源,除非位置离头部很近。但是插入和删除元素花费常数时间。
参考文档
http://www.fx114.net/qa-226-155160.aspx
http://www.cnblogs.com/huzi007/p/5550440.html
- Java8 LinkedList源码分析
- java8源码分析LinkedList
- 【Java8源码分析】集合框架-LinkedList
- java8 LinkedList源码阅读
- Java8 - LinkedList源码
- java8 LinkedList源码阅读
- Java8源码-LinkedList
- Java8 LinkedList源码简析
- java8 LinkedList源码阅读【2】- 总结
- ConcurrentHashMap源码分析--Java8
- ConcurrentHashMap源码分析--Java8
- Java8 HashMap源码分析
- Java8 ArrayList源码分析
- Java8 HashMap源码分析
- java8源码分析ArrayList
- java8-HashMap源码分析
- LinkedList 源码分析
- LinkedList源码分析
- Oracle查看用户信息
- Pandas对文件的处理
- spring整合web项目
- JAVA基础之方法参数传递
- redis安装配置总结
- Java8 LinkedList源码分析
- JavaScript难点(二)
- [干货]javax.el.PropertyNotFoundException: Property 'XXX' not found on class 'XX' 问题详解
- 2017 多校训练第三场 HDU 6063 RXD and math
- 如何创建一个ssh项目
- 学习笔记
- Java多线程 线程安全一本通,线程安全,为什么要用多线程,如何同步,单例模式线程安全
- 16CF1--A
- markdown学习


