Java8源码-LinkedList
来源:互联网 发布:数据挖掘 情报研究 编辑:程序博客网 时间:2024/06/11 15:59
前几天学习了ArrayList源码和Vector源码和迭代器模式在它们源码中的使用,今天开始学习LinkedList源码。参考的JDK版本为1.8。
LinkedList和ArrayList与Vector同样实现了List接口,但它执行某些操作如插入和删除元素操作比ArrayList与Vector更高效,而随机访问操作效率低。除此之外,LinkedList还添加了可以使其用作栈、队列或双端队列的方法。LinkedList在实现方面与ArrayList与Vector有哪些不同呢?为什么它插入删除操作效率高?随机访问操作效率低?它是如何用作栈、队列或双端队列的?本文将分析LinkedList的内部结构及实现原理,帮助大家更好的使用它,并一一解答上述问题。
顶部注释
Doubly-linked list implementation of the List and Deque interfaces. Implements all optional list operations, and permits all elements (including null).
第一段大意为LinkedList是List接口和Deque接口的双向链表实现。LinkedList实现了所有的列表操作,允许所有的元素(包括空元素)。
All of the operations perform as could be expected for a doubly-linked list. Operations that index into the list will traverse the list from the beginning or the end,whichever is closer to the specified index.
第二段大意为所有的操作都是在对双向链表操作。
Note that this implementation is not synchronized.
If multiple threads access a linked list concurrently, and at least one of the threads modifies the list structurally, it must be synchronized externally. (A structural modification is any operation that adds or deletes one or more elements; merely setting the value of an element is not a structural modification.) This is typically accomplished by synchronizing on some object that naturally encapsulates the list.
第三段大意为LinkedList不是线程安全的。
If no such object exists, the list should be “wrapped” using the Collections#synchronizedList Collections.synchronizedList method. This is best done at creation time, to prevent accidental unsynchronized access to the list:
List list = Collections.synchronizedList(new LinkedList(...));
第四段大意为Collections.synchronizedList方法可以实现线程安全的操作。
The iterators returned by this class’s iterator and listIterator methods are fail-fast: if the list is structurally modified at any time after the iterator is created, in any way except through the Iterator’s own remove or add methods, the iterator will throw a ConcurrentModificationException. Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the presence of unsynchronized concurrent modification. Fail-fast iterators throw ConcurrentModificationException on a best-effort basis. Therefore, it would be wrong to write a program that depended on this exception for its correctness: the fail-fast behavior of iterators should be used only to detect bugs.
第五第六段大意为由iterator()和listIterator()返回的迭代器是fail-fast的。想详细了解fail-fast请参考我的另一文章Java容器源码-详解fail-fast
LinkedList类层次结构
先来看看LinkedList的定义
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
从中我们可以了解到
- LinkedList<E>:说明它支持泛型。
- extends AbstractSequentialList<E>
AbstractSequentialList 继承自AbstractList,但AbstractSequentialList 只支持按次序访问,而不像 AbstractList 那样支持随机访问。这是LinkedList随机访问效率低的原因之一。 - implements List<E>:说明它支持集合的一般操作。
- implements Deque<E>:Deque,Double ended queue,双端队列。LinkedList可用作队列或双端队列就是因为实现了它。
- implements Cloneable:表明其可以调用clone()方法来返回实例的field-for-field拷贝。
- implements java.io.Serializable:表明该类是可以序列化的。
与ArrayList对比发现,LinkedList并没有实现RandomAccess,而实现RandomAccess表明其支持快速(通常是固定时间)随机访问。此接口的主要目的是允许一般的算法更改其行为,从而在将其应用到随机或连续访问列表时能提供良好的性能。这是LinkedList随机访问效率低的原因之一。
下图是LinkedList的类结构层次图
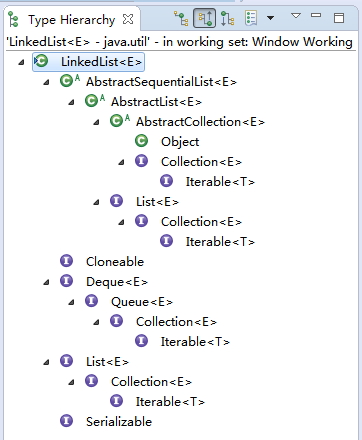
如何查看类层次结构图可以参考我写过的一篇文章:
eclipse-查看继承层次图/继承实现层次图
全局变量
/** * LinkedList节点个数 */transient int size = 0;/** * 指向头节点的指针 * Invariant: (first == null && last == null) || * (first.prev == null && first.item != null) */transient Node<E> first;/** * 指向尾节点的指针 * Invariant: (first == null && last == null) || * (last.next == null && last.item != null) */transient Node<E> last;关于node的详细介绍请看本文末尾的内部类—Node.java一节。Node表示链表每个节点的内部结构,包括一个数据域item,一个后置指针next,一个前置指针prev。
构造方法
接下来,看LinkedList提供的构造方法。ArrayList提供了两种构造方法。
1.构造空LinkedList。
/** * 构造一个空链表. */public LinkedList() {}2.构造空LinkedList。
/** * 根据指定集合c构造linkedList。先构造一个空linkedlist,在把指定集合c中的所有元素都添加到linkedList中。 * * @param c 指定集合 * @throws NullPointerException 如果特定指定集合c为null */public LinkedList(Collection<? extends E> c) { this(); addAll(c);}方法
以下几个方法是操作链表的底层方法
linkFirst(E e)
方法在表头添加指定元素e,在表头添加元素的过程如下: 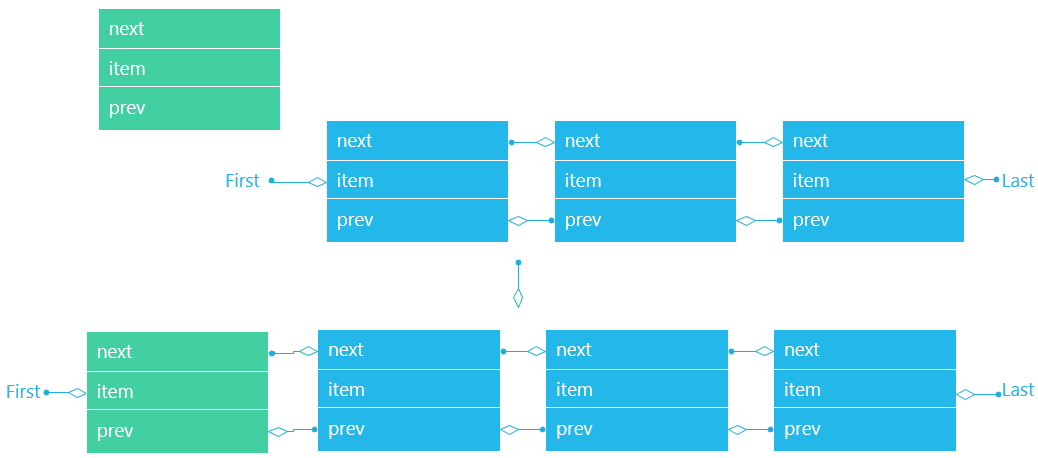
源码如下:
/** * 在表头添加元素 */private void linkFirst(E e) { //使节点f指向原来的头结点 final Node<E> f = first; //新建节点newNode,节点的前指针指向null,后指针原来的头节点 final Node<E> newNode = new Node<>(null, e, f); //头指针指向新的头节点newNode first = newNode; //如果原来的头结点为null,更新尾指针,否则使原来的头结点f的前置指针指向新的头结点newNode if (f == null) last = newNode; else f.prev = newNode; size++; modCount++;}linkLast(E e)
方法在表尾插入指定元素e。添加元素的过程如下: 
/** * 在表尾插入指定元素e */void linkLast(E e) { //使节点l指向原来的尾结点 final Node<E> l = last; //新建节点newNode,节点的前指针指向l,后指针为null final Node<E> newNode = new Node<>(l, e, null); //尾指针指向新的头节点newNode last = newNode; //如果原来的尾结点为null,更新头指针,否则使原来的尾结点l的后置指针指向新的头结点newNode if (l == null) first = newNode; else l.next = newNode; size++; modCount++;}linkBefore( E e, Node succ)
方法在指定节点succ之前插入指定元素e。添加元素的过程如下: 
/** * 在指定节点succ之前插入指定元素e。指定节点succ不能为null。 */void linkBefore(E e, Node<E> succ) { // assert succ != null; //获得指定节点的前驱 final Node<E> pred = succ.prev; //新建节点newNode,前置指针指向pred,后置指针指向succ final Node<E> newNode = new Node<>(pred, e, succ); //succ的前置指针指向newTouch succ.prev = newNode; //如果指定节点的前驱为null,将newTouch设为头节点。否则更新pred的后置节点 if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++;}unlinkFirst( Node f)
方法删除并返回头结点f。删除头结点过程如下: 
/** * 删除头结点f,并返回头结点的值 */private E unlinkFirst( Node<E> f) { // assert f == first && f != null; // 保存头结点的值 final E element = f.item; // 保存头结点指向的下个节点 final Node<E> next = f.next; //头结点的值置为null f.item = null; //头结点的后置指针指向null f.next = null; // help GC //将头结点置为next first = next; //如果next为null,将尾节点置为null,否则将next的后置指针指向null if (next == null) last = null; else next.prev = null; size--; modCount++; //返回被删除的头结点的值 return element;}unlinkLast( Node l)
方法删除并返回尾结点f。删除尾结点过程如下: 
/** * 删除尾节点l.并返回尾节点的值 */private E unlinkLast(Node<E> l) { // assert l == last && l != null; // 保存尾节点的值 final E element = l.item; //获取新的尾节点prev final Node<E> prev = l.prev; //旧尾节点的值置为null l.item = null; //旧尾节点的后置指针指向null l.prev = null; // help GC //将新的尾节点置为prev last = prev; //如果新的尾节点为null,头结点置为null,否则将新的尾节点的后置指针指向null if (prev == null) first = null; else prev.next = null; size--; modCount++; //返回被删除的尾节点的值 return element;}unlink( Node x)
方法删除指定节点,返回指定元素的值x。删指定节点过程如下: 
/** * 删除指定节点,返回指定元素的值 */E unlink(Node<E> x) { // assert x != null; // 保存指定节点的值 final E element = x.item; // 获取指定节点的下个节点next final Node<E> next = x.next; // 获取指定节点的下个节点prev final Node<E> prev = x.prev; //如果prev为null,那么next为新的头结点,否则将prev的后置指针指向next,x的前置指针指向null if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } //如果next为null,那么prev为新的尾结点,否则将next的前置指针指向prev,x的后置指针指向null if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } //x的值置为null x.item = null; size--; modCount++; //返回被删除的节点的值 return element;}getFirst()
/** * 返回链表中的头结点的值. * * @return 返回链表中的头结点的值 * @throws NoSuchElementException 如果链表为空 */public E getFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return f.item;}getLast()
/** * 返回链表中的尾结点的值. * * @return 返回链表中的头结点的值 * @throws NoSuchElementException 如果链表为空 */public E getLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return l.item;}常用的操作方法
removeFirst
/** * 删除并返回表头元素. * * @return 表头元素 * @throws NoSuchElementException 链表为空 */public E removeFirst() { final Node<E> f = first; if (f == null) throw new NoSuchElementException(); return unlinkFirst(f);}removeLast
/** * 删除并返回表尾元素. * * @return 表尾元素 * @throws NoSuchElementException 链表为空 */public E removeLast() { final Node<E> l = last; if (l == null) throw new NoSuchElementException(); return unlinkLast(l);}addFirst( E e)
/** * 在表头插入指定元素. * * @param e 插入的指定元素 */public void addFirst(E e) { linkFirst(e);}addLast( E e)
/** * 在表尾插入指定元素. * * 该方法等价于add() * * @param e 插入的指定元素 */ public void addLast(E e) { linkLast(e);}contains( Object o)
/** * 判断链表是否包含指定对象o * @param o 指定对象 * @return 是否包含指定对象 */public boolean contains(Object o) { return indexOf(o) != -1;}size()
/** * 返回链表元素个数 * * @return 链表元素个数 */public int size() { return size;}add( E e)
/** * 在表尾插入指定元素. * * 该方法等价于addLast * * @param e 插入的指定元素 * @return true */public boolean add(E e) { linkLast(e); return true;}remove(Object o)
/** * 正向遍历链表,删除出现的第一个值为指定对象的节点 * * @param o 要删除的节点置 * @return 如果o在链表中存在,返回true */public boolean remove(Object o) { //遍历链表,如果o为null,删除第一个值为null的节点,返回true。如果不为null,删除第一个值为o的节点。如果链表中存在o,就返回true。 if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false;}addAll( Collection<? extends E> c)
/** * 插入指定集合到链尾 * * @param c 指定集合 * @return 如果链表改变,返回true * @throws NullPointerException 如果指定集合为null */public boolean addAll(Collection<? extends E> c) { return addAll(size, c);}addAll( int index, Collection<? extends E> c)
/** * 插入指定集合到链尾的指定位置 * * @param index 指定的插入位置 * @param c 插入的指定集合 * @return 如果链表改变,返回true * @throws IndexOutOfBoundsException 如果index<0或index>size * @throws NullPointerException 如果指定集合为null */public boolean addAll(int index, Collection<? extends E> c) { //检查插入的位置是否合法 checkPositionIndex(index); Object[] a = c.toArray(); int numNew = a.length; if (numNew == 0) return false;//如果c是空的话那么就返回false //定义两个节点指针,指向插入点前后的节点元素 Node<E> pred, succ; if (index == size) { succ = null; pred = last; } else { succ = node(index); pred = succ.prev; } // 插入集合中所有元素 for (Object o : a) { @SuppressWarnings("unchecked") E e = (E) o; Node<E> newNode = new Node<>(pred, e, null); if (pred == null) first = newNode; else pred.next = newNode; pred = newNode; } // 修改插入后的指针问题 if (succ == null) { last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew; modCount++; return true;}clear()
/** * 删除链表中的所有元素 */public void clear() { // Clearing all of the links between nodes is "unnecessary", but: // - helps a generational GC if the discarded nodes inhabit // more than one generation // - is sure to free memory even if there is a reachable Iterator for (Node<E> x = first; x != null; ) { Node<E> next = x.next; x.item = null; x.next = null; x.prev = null; x = next; } first = last = null; size = 0; modCount++;}按位操作
get( int index)
/** * 返回指定索引处的元素 * * @param index 指定索引 * @return 指定索引处的元素 * @throws IndexOutOfBoundsException 如果索引index越界 */public E get(int index) { checkElementIndex(index); return node(index).item;}set( int index, E element)
/** * 替换指定索引处的元素为指定元素element * * @param index 被替换的元素的索引 * @param element * @return 指定元素element * @throws IndexOutOfBoundsException 索引越界 */public E set(int index, E element) { checkElementIndex(index); Node<E> x = node(index); E oldVal = x.item; x.item = element; return oldVal;}add( int index, E element)
/** * 插入指定元素到指定索引处 * * @param index 指定索引 * @param element 指定元素 * @throws IndexOutOfBoundsException 索引越界 */public void add(int index, E element) { checkPositionIndex(index); if (index == size) linkLast(element); else linkBefore(element, node(index));}remove( int index)
/** * 删除指定索引处的元素 * * @param 指定索引 * @return 指定索引处的元素 * @throws IndexOutOfBoundsException 索引越界 */public E remove(int index) { checkElementIndex(index); return unlink(node(index));}isElementIndex( int index)
/** * 返回索引是否越界 */private boolean isElementIndex(int index) { return index >= 0 && index < size;}isPositionIndex(int index)
/** * 返回插入操作时给定的索引是否合法 */private boolean isPositionIndex(int index) { return index >= 0 && index <= size;}outOfBoundsMsg( int index)
/** * 索引越界时打印的信息 */private String outOfBoundsMsg(int index) { return "Index: "+index+", Size: "+size;}checkElementIndex( int index)
/** * 检查索引是否越界 */private void checkElementIndex(int index) { if (!isElementIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}checkPositionIndex( int index)
/** * 检查插入操作时给定的索引是否合法 */private void checkPositionIndex(int index) { if (!isPositionIndex(index)) throw new IndexOutOfBoundsException(outOfBoundsMsg(index));}node( int index)
/** * 返回在指定索引处的非空元素 */Node<E> node(int index) { // assert isElementIndex(index); if (index < (size >> 1)) { Node<E> x = first; for (int i = 0; i < index; i++) x = x.next; return x; } else { Node<E> x = last; for (int i = size - 1; i > index; i--) x = x.prev; return x; }}查找操作
indexOf( Object o)
/** * 正向遍历链表,返回指定元素第一次出现时的索引。如果元素没有出现,返回-1. * * @param o 需要查找的元素 * @return 指定元素第一次出现时的索引。如果元素没有出现,返回-1。 */public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1;}lastIndexOf( Object o)
/** * 逆向遍历链表,返回指定元素第一次出现时的索引。如果元素没有出现,返回-1. * * @param o 需要查找的元素 * @return 指定元素第一次出现时的索引。如果元素没有出现,返回-1。 */public int lastIndexOf(Object o) { int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1;}队列操作
peek()
/** * 返回头节点的元素,如果链表为空则返回null * * @return 返回头节点的元素,如果链表为空则返回null * @since 1.5 */public E peek() { final Node<E> f = first; return (f == null) ? null : f.item;}element()
/** * 获取表头节点的值,头节点为空抛出异常 * * @return 获取表头节点的值 * @throws NoSuchElementException 如果链表为空 * @since 1.5 */public E element() { return getFirst();}poll()
/** * 返回并删除头节点,如果链表为空则返回null * * @return 返回并删除头节点,如果链表为空则返回null * @since 1.5 */public E poll() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f);}remove()
/** * 删除并返回头节点,如果链表为空,抛出异常 * * @return 头结点 * @throws NoSuchElementException 链表为空 * @since 1.5 */public E remove() { return removeFirst();}offer(E e)
/** * 添加元素到队列尾部 * * @param e 指定元素 * @return * @since 1.5 */public boolean offer(E e) { return add(e);}双向队列操作
offerFirst( E e)
/** * 插入指定元素到队列头部. * * @param e 插入的元素 * @return true * @since 1.6 */public boolean offerFirst(E e) { addFirst(e); return true;}offerLast( E e)
/** * 插入指定元素到队列尾部. * * @param e 插入的元素 * @return true * @since 1.6 */public boolean offerLast(E e) { addLast(e); return true;}peekFirst()
/*** 返回队列的头元素,如果头节点为空则返回空** @return 返回队列的头元素,如果头节点为空则返回空* @since 1.6*/public E peekFirst() { final Node<E> f = first; return (f == null) ? null : f.item;}peekLast()
/*** 返回队列的尾元素,如果尾节点为空则返回空** @return 返回队列的尾元素,如果尾节点为空则返回空* @since 1.6*/public E peekLast() { final Node<E> l = last; return (l == null) ? null : l.item;}pollFirst()
/** * 删除并返回队列的第一个元素,如果头节点为空,则返回null. * * @return 删除并返回队列的第一个元素,如果头节点为空,则返回null. * @since 1.6 */public E pollFirst() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f);}pollLast()
/** * 删除并返回队列的最后个元素,如果尾节点为空,则返回null. * * @return 删除并返回队列的最后一个元素,如果尾节点为空,则返回null. * @since 1.6 */public E pollLast() { final Node<E> l = last; return (l == null) ? null : unlinkLast(l);}push( E e)
/** * 插入指定元素到栈头 * * 此方法等价于addFirst(e) * * @param e 指定元素 * @since 1.6 */public void push(E e) { addFirst(e);}pop()
/** * 删除并返回栈头元素 * * 此方法等价于pop() * * @return 返回栈头元素 * @throws NoSuchElementException 如果栈为空 * @since 1.6 */public E pop() { return removeFirst();}removeFirstOccurrence( Object o)
/** * 正向遍历栈,删除指定对象第一次出现时,索引对应的元素 * * @param o 被删除的元素 * @return true 如果元素出现 * @since 1.6 */public boolean removeFirstOccurrence(Object o) { return remove(o);}其他操作
listIterator( int index)
/** * 返回指向索引为index的元素的列表迭代器。此列表迭代器是fail-fast的,如果遍历过程中list被修改,迭代器会抛出ConcurrentModificationException异常。因此,在并发修改时,迭代器没有冒险行动,而是干净利落的抛出异常。 * * @param index 迭代器初始指向的索引 * @return 列表迭代器 * @throws IndexOutOfBoundsException 索引月季 * @see List#listIterator(int) */public ListIterator<E> listIterator(int index) { checkPositionIndex(index); return new ListItr(index);}ListItr的具体实现请看本文末尾内部类—ListItr
descendingIterator()
/** * 递减迭代器 * * @since 1.6 */public Iterator<E> descendingIterator() { return new DescendingIterator();}DescendingIterator的具体实现请看本文末尾内部类—DescendingIterator
superClone()
@SuppressWarnings("unchecked")private LinkedList<E> superClone() { try { return (LinkedList<E>) super.clone(); } catch (CloneNotSupportedException e) { throw new InternalError(e); }}clone()
/** * 返回浅拷贝 * * @return 返回浅拷贝 */public Object clone() { LinkedList<E> clone = superClone(); // Put clone into "virgin" state clone.first = clone.last = null; clone.size = 0; clone.modCount = 0; // Initialize clone with our elements for (Node<E> x = first; x != null; x = x.next) clone.add(x.item); return clone;}toArray()
/** * 将所有链表元素按顺序存到数组中. * * @return 包含所有链表元素的数组 */public Object[] toArray() { Object[] result = new Object[size]; int i = 0; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; return result;}toArray( T[] a)
/** * 将所有链表元素按顺序存到数组中。数组元素的类型是给定的类型。如果链表元素的类型和数组元素类型不匹配,将新建一个数组来存储链表元素 * * @throws NullPointerException 如果指定的数组为null */@SuppressWarnings("unchecked")public <T> T[] toArray(T[] a) { if (a.length < size) a = (T[])java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size); int i = 0; Object[] result = a; for (Node<E> x = first; x != null; x = x.next) result[i++] = x.item; if (a.length > size) a[size] = null; return a;}序列化和反序列化
private static final long serialVersionUID = 876323262645176354L;/** * 序列化链表 * * @serialData 大小和元素 */private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException { // Write out any hidden serialization magic s.defaultWriteObject(); // 序列化大小 s.writeInt(size); // // 按顺序序列化元素 for (Node<E> x = first; x != null; x = x.next) s.writeObject(x.item);}/** * 反序列化 */@SuppressWarnings("unchecked")private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException { // Read in any hidden serialization magic s.defaultReadObject(); // 反序列化大小 int size = s.readInt(); // 按顺序反序列化元素 for (int i = 0; i < size; i++) linkLast((E)s.readObject());}spliterator()
/** * 创建一个late-binding和fail-fast的迭代器 * * @implNote * * @return 迭代器 * @since 1.8 */@Overridepublic Spliterator<E> spliterator() { return new LLSpliterator<E>(this, -1, 0);}内部类
ListItr
private class ListItr implements ListIterator<E> { private Node<E> lastReturned; private Node<E> next; private int nextIndex; private int expectedModCount = modCount; ListItr(int index) { // assert isPositionIndex(index); next = (index == size) ? null : node(index); nextIndex = index; } public boolean hasNext() { return nextIndex < size; } public E next() { checkForComodification(); if (!hasNext()) throw new NoSuchElementException(); lastReturned = next; next = next.next; nextIndex++; return lastReturned.item; } public boolean hasPrevious() { return nextIndex > 0; } public E previous() { checkForComodification(); if (!hasPrevious()) throw new NoSuchElementException(); lastReturned = next = (next == null) ? last : next.prev; nextIndex--; return lastReturned.item; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex - 1; } public void remove() { checkForComodification(); if (lastReturned == null) throw new IllegalStateException(); Node<E> lastNext = lastReturned.next; unlink(lastReturned); if (next == lastReturned) next = lastNext; else nextIndex--; lastReturned = null; expectedModCount++; } public void set(E e) { if (lastReturned == null) throw new IllegalStateException(); checkForComodification(); lastReturned.item = e; } public void add(E e) { checkForComodification(); lastReturned = null; if (next == null) linkLast(e); else linkBefore(e, next); nextIndex++; expectedModCount++; } public void forEachRemaining(Consumer<? super E> action) { Objects.requireNonNull(action); while (modCount == expectedModCount && nextIndex < size) { action.accept(next.item); lastReturned = next; next = next.next; nextIndex++; } checkForComodification(); } final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }}Node.java
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}DescendingIterator
/** * Adapter to provide descending iterators via ListItr.previous */private class DescendingIterator implements Iterator<E> { private final ListItr itr = new ListItr(size()); public boolean hasNext() { return itr.hasPrevious(); } public E next() { return itr.previous(); } public void remove() { itr.remove(); }}LLSpliterator
/** A customized variant of Spliterators.IteratorSpliterator */static final class LLSpliterator<E> implements Spliterator<E> { static final int BATCH_UNIT = 1 << 10; // batch array size increment static final int MAX_BATCH = 1 << 25; // max batch array size; final LinkedList<E> list; // null OK unless traversed Node<E> current; // current node; null until initialized int est; // size estimate; -1 until first needed int expectedModCount; // initialized when est set int batch; // batch size for splits LLSpliterator(LinkedList<E> list, int est, int expectedModCount) { this.list = list; this.est = est; this.expectedModCount = expectedModCount; } final int getEst() { int s; // force initialization final LinkedList<E> lst; if ((s = est) < 0) { if ((lst = list) == null) s = est = 0; else { expectedModCount = lst.modCount; current = lst.first; s = est = lst.size; } } return s; } public long estimateSize() { return (long) getEst(); } public Spliterator<E> trySplit() { Node<E> p; int s = getEst(); if (s > 1 && (p = current) != null) { int n = batch + BATCH_UNIT; if (n > s) n = s; if (n > MAX_BATCH) n = MAX_BATCH; Object[] a = new Object[n]; int j = 0; do { a[j++] = p.item; } while ((p = p.next) != null && j < n); current = p; batch = j; est = s - j; return Spliterators.spliterator(a, 0, j, Spliterator.ORDERED); } return null; } public void forEachRemaining(Consumer<? super E> action) { Node<E> p; int n; if (action == null) throw new NullPointerException(); if ((n = getEst()) > 0 && (p = current) != null) { current = null; est = 0; do { E e = p.item; p = p.next; action.accept(e); } while (p != null && --n > 0); } if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); } public boolean tryAdvance(Consumer<? super E> action) { Node<E> p; if (action == null) throw new NullPointerException(); if (getEst() > 0 && (p = current) != null) { --est; E e = p.item; current = p.next; action.accept(e); if (list.modCount != expectedModCount) throw new ConcurrentModificationException(); return true; } return false; } public int characteristics() { return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED; }}用到的设计模式
迭代器模式
详情请参考LinkedList与迭代器模式
相关推荐:设计模式(16)-迭代器模式。
总结
从源码中,我们不难论证以前对LinkedList的了解
- LinkedList底层是双向链表。
- 有序。链表是有序的。
- 元素可重复。链表元素可重复。
- 随机访问效率低,增删效率高。
更多文章:
- Java8容器源码-目录
- Java8容器源码-整体结构
- Java8容器源码-ArrayList
- ArrayList与迭代器模式
- Java8容器源码-Vector
- Vector与迭代器模式
- Java8容器源码-详解fail-fast
- Iterator与Enumeration
- Java8容器源码-LinkedList
- LinkedList与迭代器模式
- Java8容器源码-Stack
- Java8容器源码-List总结
- Java8容器源码-Map整体架构
- Java8容器源码-HashMap
- Java8容器源码-Hashtable(1)
- Java8容器源码-Hashtable(2)
原文地址:CSDN博客-潘威威的博客-http://blog.csdn.net/panweiwei1994/article/details/77110354
本文版权归作者所有,欢迎转载,但转载时请在文章明显位置给出原文作者名字(潘威威)及原文链接,否则作者将保留追究法律责任的权利。
- java8 LinkedList源码阅读
- Java8 - LinkedList源码
- java8 LinkedList源码阅读
- Java8 LinkedList源码分析
- Java8源码-LinkedList
- java8源码分析LinkedList
- Java8 LinkedList源码简析
- java8 LinkedList源码阅读【2】- 总结
- 【Java8源码分析】集合框架-LinkedList
- Java8 LinkedList的底层实现
- LinkedList源码
- LinkedList源码
- LinkedList源码
- LinkedList源码
- 【源码】LinkedList源码剖析
- JDK源码-LinkedList源码
- 深入java集合系列:java8 LinkedList详解
- java8的源码
- json时间格式化(JS)
- Image-to-Image Translation with Conditional Adversarial Networks论文学习
- 【尺取】hdu 6103 Kirinriki
- 错误0x80070522错误问题
- ctf web4
- Java8源码-LinkedList
- 自已动手编译Linux系统-基于ALFS的LFS8.0实践(一)
- linux使用运算符(; || &&)
- 签到题
- EMF学习笔记(四)——使用EMF编程——持久化(续)
- 两个列表合并成字典
- JTable 不能正确显示标题总结
- HDU-3713---Double Maze (bfs) 详细解释
- 什么是Android开发?


