Java8源码-LinkedHashMap
来源:互联网 发布:apache tomcat安装教程 编辑:程序博客网 时间:2024/06/06 01:28
前面已经学习了HashMap源码和Hashtable源码,今天开始学习LinkedHashMap。参考的JDK版本为1.8。
LinkedHashMap继承了HashMap,是Map接口的哈希表和链接列表实现。哈希表的功能通过继承HashMap实现了。LinkedHashMap还维护着一个双重链接链表。此链表定义了迭代顺序,该迭代顺序可以是插入顺序或者是访问顺序。本文主要讲解双重链接链表的部分,看看它是如何实现有序性的。
数据结构
在分析LinkedHashMap源码之前,有必要了解LinkedHashMap的数据结构,否则很难理解下面的内容。
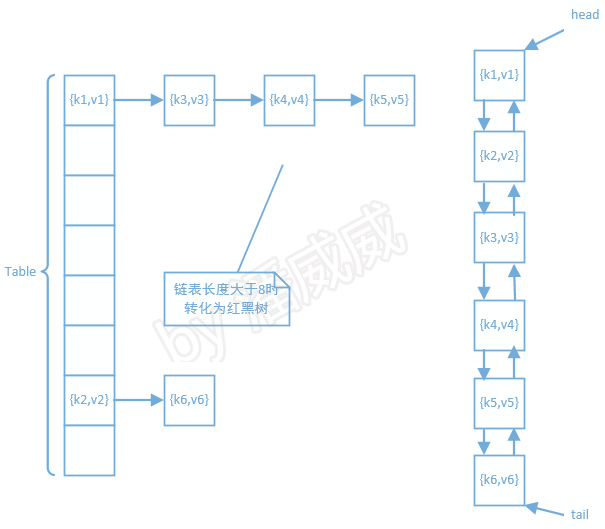
从上图中可以很清楚的看到,HashMap的数据结构是数组+链表+红黑树(since JDK1.8)+ 双重链接列表。数组+链表+红黑树的部分请参考HashMap源码一文中关于数据结构的讲解,HashMap和LinkedHashMap在这部分的实现是几乎相同的。LinkedHashMap为每个Entry添加了前驱和后继,构成了一个双向循环链表,每次向linkedHashMap插入键值对,除了将其插入到哈希表的对应位置之外,还要将其插入到双向循环链表的尾部。
部分顶部注释
Hash table and linked list implementation of the Map interface, with predictable iteration order. This implementation differs from HashMap in that it maintains a doubly-linked list running through all of its entries. This linked list defines the iteration ordering, which is normally the order in which keys were inserted into the map (insertion-order). Note that insertion order is not affected if a key is re-inserted into the map. (A key k is reinserted into a map m if m.put(k, v) is invoked when m.containsKey(k) would return true immediately prior to the invocation.)
大意为LinkedHashMap是Map的哈希表和链接列表的实现,具有可预知的迭代顺序。LinkedHashMap和HashMap的不同之处在于它包含一个贯穿于所有entry的双重链接列表。双重链接列表定义了迭代顺序,默认是插入顺序。值得注意的是,如果一个key被重插入,插入顺序不受影响。
层次结构图
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V>
从中我们可以了解到:
- LinkedHashMap<K,V>:HashMap是以key-value形式存储数据的
- extends HashMap<K,V>:继承了HashMap,哈希表部分的功能和HashMap相似。
- implements Map<K,V>:实现了Map。HashMap已经继承了Map接口,为什么LinkedHashMap还要实现Map接口呢?仔细看过Java容器其他源码的朋友会发现,不仅仅LinkedHashMap这样做,其他实现类也经常这样做。网上的一些看法是这样做可以直观地表达出LinkedHashMap实现了Map。如果大家有其他看法,欢迎留言。
说到直观地展示出一个类的继承实现结构,eclipse的类层次结构图就可以实现这个功能。下图是LinkedHashMap类结构层次图
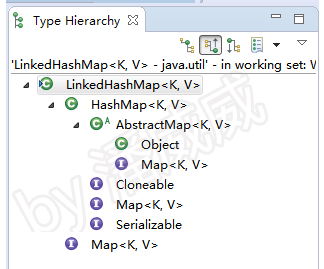
如何查看类层次结构图可以参考我写过的一篇文章:
eclipse-查看继承层次图/继承实现层次图
域
/** * 双向循环链表的头结点 */transient LinkedHashMap.Entry<K,V> head;/** * 双向循环链表的尾结点 */transient LinkedHashMap.Entry<K,V> tail;/** * 迭代顺序。 * true代表按访问顺序迭代 * false代表按插入顺序迭代 * * @serial */final boolean accessOrder;这里有必要看下LinkedHashMap的Entry的定义。LinkedHashMap的Entry继承了HashMap的Node,并且每个entry都包含前指针和后指针,这是双向循环链表的特点。
/** * LinkedHashMap的Entry继承了HashMap的Node */static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; //构造方法。 Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); }}私有方法
linkNodeLast( LinkedHashMap.Entry<K,V> p)
/** * 将指定entry插入到双向链表末尾 */private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { LinkedHashMap.Entry<K,V> last = tail; //尾指针执行p tail = p; //如果旧的尾节点指向null,意味着双向循环链表为空,这时头尾指针都要指向p if (last == null) head = p; else {//否则将p插入到旧尾节点的后面 p.before = last; last.after = p; }}transferLinks( LinkedHashMap.Entry<K,V> src, LinkedHashMap.Entry<K,V> dst)
// 将src替换为dstprivate void transferLinks(LinkedHashMap.Entry<K,V> src, LinkedHashMap.Entry<K,V> dst) { LinkedHashMap.Entry<K,V> b = dst.before = src.before; LinkedHashMap.Entry<K,V> a = dst.after = src.after; //如果src的前指针指向null,说明src为头节点,这时将dst替换为头节点即可 if (b == null) head = dst; else//否则,将dst的前指针指向的节点的后指针指向dst b.after = dst; //如果src的后指针指向null,说明src为尾节点,这时将dst替换为尾节点即可 if (a == null) tail = dst; else//否则,将dst的后指针指向的节点的前指针指向dst a.before = dst;}重写HashMap的方法
reinitialize()
//将linkedHashMap重置到初始化的默认状态void reinitialize() { //重置哈希表 super.reinitialize(); //重置双向循环链表 head = tail = null;}newNode( int hash, K key, V value, Node<K,V> e)
/** * 创建一个普通entry,将entry插入到双向循环链表的末尾,最后返回entry */Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { //创建一个entry LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); //将entry插入到双向循环链表的末尾 linkNodeLast(p); //返回entry return p;}replacementNode( Node<K,V> p, Node<K,V> next)
/** * 替换普通节点 */Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) { LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p; LinkedHashMap.Entry<K,V> t = new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next); transferLinks(q, t); return t;}newTreeNode( int hash, K key, V value, Node<K,V> next)
/** * 创建一个树的entry,将entry插入到双向循环链表的末尾,最后返回entry */TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) { TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next); linkNodeLast(p); return p;}replacementTreeNode( Node<K,V> p, Node<K,V> next)
/** * 替换树节点 */TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) { LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p; TreeNode<K,V> t = new TreeNode<K,V>(q.hash, q.key, q.value, next); transferLinks(q, t); return t;}afterNodeRemoval( Node<K,V> e)
/** * 保证linkedHashMap删除操作后哈希表与双向循环链表的一致性 */void afterNodeRemoval(Node<K,V> e) { // unlink LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.before = p.after = null; if (b == null) head = a; else b.after = a; if (a == null) tail = b; else a.before = b;}这个方法是用来在LinkedHashMap的哈希表中删除一个键值对后同时将键值对从双向循环链表中删除,保证哈希表和双向循环链表的一致性。
如果你有仔细看过HashMap的源码,你就会发现源码里有这么三个空方法:
void afterNodeAccess(Node<K,V> p) { }void afterNodeInsertion(boolean evict) { }void afterNodeRemoval(Node<K,V> p) { }你当时有没有疑问,这三个方法方法体为空,为什么存在?这三个方法表示在访问、插入、删除某个节点之后,进行一些处理,它们在LinkedHashMap都有重写。LinkedHashMap正是通过重写这三个方法来保证链表的插入、删除的有序性。
afterNodeInsertion( boolean evict)
/** * 可能把头节点删除 */void afterNodeInsertion(boolean evict) { // possibly remove eldest LinkedHashMap.Entry<K,V> first; if (evict && (first = head) != null && removeEldestEntry(first)) { K key = first.key; removeNode(hash(key), key, null, false, true); }}从代码中可以看出,如果evict && (first = head) != null && removeEldestEntry(first)条件为true,将删除头节点。看下removeEldestEntry方法的实现,发现永远返回false。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false;}这意味着afterNodeInsertion这个方法什么都做不了。那这个方法有什么用?
如果重写removeEldestEntry方法,就能定义是否删除的规则,afterNodeInsertion就有用了。对removeEldestEntry方法的详细解释请往下看。
afterNodeAccess( Node<K,V> e)
/** * 若迭代顺序为true,且指定参数节点e不是尾结点,把指定参数节点e移到末尾 */void afterNodeAccess(Node<K,V> e) { // move node to last LinkedHashMap.Entry<K,V> last; //若迭代顺序为true,且指定参数节点e不是尾结点 if (accessOrder && (last = tail) != e) { LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; p.after = null; if (b == null) head = a; else // b.after = a; if (a != null) a.before = b; else last = b; if (last == null) head = p; else { p.before = last; last.after = p; } tail = p; ++modCount; }}internalWriteEntries( java.io.ObjectOutputStream s)
/** * 写入键值对到ObjectOutputStream中 */void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException { for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { s.writeObject(e.key); s.writeObject(e.value); }}构造方法
LinkedHashMap有五种构造方法:
- LinkedHashMap( int initialCapacity, float loadFactor)。使用指定的初始化容量initial capacity 和负载因子load factor构造一个空LinkedHashMap。
- LinkedHashMap( int initialCapacity)。使用指定的初始化容量initial capacity和默认负载因子DEFAULT_LOAD_FACTOR(0.75)构造一个空LinkedHashMap。
- LinkedHashMap()。使用指定的初始化容量(16)和默认负载因子DEFAULT_LOAD_FACTOR(0.75)构造一个空HashMap。
- LinkedHashMap(Map<? extends K, ? extends V> m)。使用指定Map m构造新的LinkedHashMap。使用指定的初始化容量(16)和默认负载因子DEFAULT_LOAD_FACTOR(0.75)。
- LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)。使用指定的初始化容量initial capacity 和负载因子load factor和迭代顺序accessOrder构造一个空LinkedHashMap。
LinkedHashMap( int initialCapacity, float loadFactor)
/** * 使用指定的初始化容量initial capacity 和负载因子load factor构造一个空LinkedHashMap * * @param initialCapacity 初始化容量 * @param loadFactor 负载因子 * @throws IllegalArgumentException 如果指定的初始化容量为负数或者加载因子为非正数。 */public LinkedHashMap(int initialCapacity, float loadFactor) { super(initialCapacity, loadFactor); //默认迭代顺序为插入顺序 accessOrder = false;}LinkedHashMap( int initialCapacity)
/** * 使用指定的初始化容量initial capacity和默认负载因子DEFAULT_LOAD_FACTOR(0.75)构造一个空LinkedHashMap * * @param initialCapacity 初始化容量 * @throws IllegalArgumentException 如果指定的初始化容量为负数 */public LinkedHashMap(int initialCapacity) { super(initialCapacity); //默认迭代顺序为插入顺序 accessOrder = false;}LinkedHashMap()
/** * 使用指定的初始化容量(16)和默认负载因子DEFAULT_LOAD_FACTOR(0.75)构造一个空HashMap */public LinkedHashMap() { super(); //默认迭代顺序为插入顺序 accessOrder = false;}LinkedHashMap( Map<? extends K, ? extends V> m)
/** * 使用指定Map m构造新的LinkedHashMap。使用指定的初始化容量(16)和默认负载因子DEFAULT_LOAD_FACTOR(0.75) * @param m 指定的map * @throws NullPointerException 如果指定的map是null */public LinkedHashMap(Map<? extends K, ? extends V> m) { super(); //默认迭代顺序为插入顺序 accessOrder = false; putMapEntries(m, false);}LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder)
/** * 使用指定的初始化容量initial capacity 和负载因子load factor和迭代顺序accessOrder构造一个空LinkedHashMap * * @param initialCapacity 初始化容量 * @param loadFactor 负载因子 * @param accessOrder 迭代顺序 * * @throws IllegalArgumentException 如果指定的初始化容量为负数或者加载因子为非正数。 */public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) { super(initialCapacity, loadFactor); //默认迭代顺序为插入顺序 this.accessOrder = accessOrder;}常用方法
containsValue( Object value)
/** * 如果linkedHashMap中的键值对有一对或多对的value为参数value,返回true * * @param value 参数value * @return 如果linkedHashMap中的键值对有一对或多对的value为参数value,返回true */public boolean containsValue(Object value) { //遍历双向循环链表,如果有一对或多对的键值对value为参数value,返回true for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) { V v = e.value; if (v == value || (value != null && value.equals(v))) return true; } //否则返回false return false;}get( Object key)
/** * 返回指定的key对应的entry的value,如果entry为null或者value为null,则返回null * * @see #put(Object, Object) */public V get(Object key) { Node<K,V> e; //如果key对应的entry为null,返回null if ((e = getNode(hash(key), key)) == null) return null; //如果迭代顺序为按访问顺序迭代 if (accessOrder) //将e插入双向链表末尾 afterNodeAccess(e); //返回value return e.value;}getOrDefault( Object key, V defaultValue)
/** * 通过key映射到对应entry,如果没映射到则返回默认值defaultValue * * @return key映射到对应的entry,如果没映射到则返回默认值defaultValue */public V getOrDefault(Object key, V defaultValue) { Node<K,V> e; //如果key对应的entry为null,返回defaultValue if ((e = getNode(hash(key), key)) == null) return defaultValue; //如果迭代顺序为按访问顺序迭代 if (accessOrder) //将e插入双向链表末尾 afterNodeAccess(e); //返回value return e.value;}clear()
/** * 清空linkedHashMap。 */public void clear() { //清空哈希表 super.clear(); //清空双向循环链表 head = tail = null;}removeEldestEntry( Map.Entry<K,V> eldest)
/** * 如果map应该删除头节点,返回true * * 这个方法在被put和putAll方法被调用,当向map中插入一个新的entry时被执行。 * * 这个方法提供了当一个新的entry被添加到linkedHashMap中,删除头节点的机会。 * * 这个方法是很有用的,可以通过删除头节点来减少内存消耗,避免溢出。 * * 简单的例子:这个方法的重写将map的最大值设为100,到100时,每次增一个entry,就删除一次头节点。 * * private static final int MAX_ENTRIES = 100; * * protected boolean removeEldestEntry(Map.Entry eldest) { * return size() > MAX_ENTRIES;//当map大小大于100时,返回true。意为允许删除头节点 * } * * 这个方法一般不会直接修改map,而是通过返回true或者false来控制是否修改map。 * * 这个方法仅仅返回false,这样头节点就永远都不会被删除了。 * * @param eldest 头节点 * @return 如果map应该删除头节点就返回true,否则返回false */protected boolean removeEldestEntry(Map.Entry<K,V> eldest) { return false;}keySet()
/** * 返回linkedHashMap中所有key的视图。 * 改变linkedHashMap会影响到set,反之亦然。 * 如果当迭代器迭代set时,linkedHashMap被修改(除非是迭代器自己的remove()方法),迭代器的结果是不确定的。 * set支持元素的删除,通过Iterator.remove、Set.remove、removeAll、retainAll、clear操作删除hashMap中对应的键值对。不支持add和addAll方法。 * * @return 返回linkedHashMap中所有key的set视图 */public Set<K> keySet() { Set<K> ks = keySet; if (ks == null) { ks = new LinkedKeySet(); keySet = ks; } return ks;}final class LinkedKeySet extends AbstractSet<K> { public final int size() { return size; } public final void clear() { LinkedHashMap.this.clear(); } public final Iterator<K> iterator() { return new LinkedKeyIterator(); } public final boolean contains(Object o) { return containsKey(o); } public final boolean remove(Object key) { return removeNode(hash(key), key, null, false, true) != null; } public final Spliterator<K> spliterator() { return Spliterators.spliterator(this, Spliterator.SIZED | Spliterator.ORDERED | Spliterator.DISTINCT); } public final void forEach(Consumer<? super K> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e.key); if (modCount != mc) throw new ConcurrentModificationException(); }}values()
/** * 返回linkedHashMap中所有value的collection视图 * 改变linkedHashMap会改变collection,反之亦然。 * 如果当迭代器迭代collection时,linkedHashMap被修改(除非是迭代器自己的remove()方法),迭代器的结果是不确定的。 * collection支持元素的删除,通过Iterator.remove、Collection.remove、removeAll、retainAll、clear操作删除linkedHashMap中对应的键值对。不支持add和addAll方法。 * * @return 返回linkedHashMap中所有key的collection视图 */public Collection<V> values() { Collection<V> vs = values; if (vs == null) { vs = new LinkedValues(); values = vs; } return vs;}final class LinkedValues extends AbstractCollection<V> { public final int size() { return size; } public final void clear() { LinkedHashMap.this.clear(); } public final Iterator<V> iterator() { return new LinkedValueIterator(); } public final boolean contains(Object o) { return containsValue(o); } public final Spliterator<V> spliterator() { return Spliterators.spliterator(this, Spliterator.SIZED | Spliterator.ORDERED); } public final void forEach(Consumer<? super V> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e.value); if (modCount != mc) throw new ConcurrentModificationException(); }}entrySet()
/** * 返回hashMap中所有键值对的set视图 * 改变hashMap会影响到set,反之亦然。 * 如果当迭代器迭代set时,hashMap被修改(除非是迭代器自己的remove()方法),迭代器的结果是不确定的。 * set支持元素的删除,通过Iterator.remove、Set.remove、removeAll、retainAll、clear操作删除hashMap中对应的键值对。不支持add和addAll方法。 * * @return 返回hashMap中所有键值对的set视图 */public Set<Map.Entry<K,V>> entrySet() { Set<Map.Entry<K,V>> es; return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;}final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> { public final int size() { return size; } public final void clear() { LinkedHashMap.this.clear(); } public final Iterator<Map.Entry<K,V>> iterator() { return new LinkedEntryIterator(); } public final boolean contains(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Node<K,V> candidate = getNode(hash(key), key); return candidate != null && candidate.equals(e); } public final boolean remove(Object o) { if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>) o; Object key = e.getKey(); Object value = e.getValue(); return removeNode(hash(key), key, value, true, true) != null; } return false; } public final Spliterator<Map.Entry<K,V>> spliterator() { return Spliterators.spliterator(this, Spliterator.SIZED | Spliterator.ORDERED | Spliterator.DISTINCT); } public final void forEach(Consumer<? super Map.Entry<K,V>> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e); if (modCount != mc) throw new ConcurrentModificationException(); }}forEach( BiConsumer<? super K, ? super V> action)
/** * 待补充 */public void forEach(BiConsumer<? super K, ? super V> action) { if (action == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) action.accept(e.key, e.value); if (modCount != mc) throw new ConcurrentModificationException();}replaceAll( BiFunction<? super K, ? super V, ? extends V> function)
/** * 待补充 */public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) { if (function == null) throw new NullPointerException(); int mc = modCount; for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) e.value = function.apply(e.key, e.value); if (modCount != mc) throw new ConcurrentModificationException();}内部类
Entry、LinkedKeySet、LinkedValues、LinkedEntrySet内部类的实现在上面。
LinkedHashIterator类
abstract class LinkedHashIterator { LinkedHashMap.Entry<K,V> next; LinkedHashMap.Entry<K,V> current; int expectedModCount; LinkedHashIterator() { next = head; expectedModCount = modCount; current = null; } public final boolean hasNext() { return next != null; } final LinkedHashMap.Entry<K,V> nextNode() { LinkedHashMap.Entry<K,V> e = next; if (modCount != expectedModCount) throw new ConcurrentModificationException(); if (e == null) throw new NoSuchElementException(); current = e; next = e.after; return e; } public final void remove() { Node<K,V> p = current; if (p == null) throw new IllegalStateException(); if (modCount != expectedModCount) throw new ConcurrentModificationException(); current = null; K key = p.key; removeNode(hash(key), key, null, false, false); expectedModCount = modCount; }}LinkedKeyIterator类
final class LinkedKeyIterator extends LinkedHashIterator implements Iterator<K> { public final K next() { return nextNode().getKey(); }}LinkedValueIterator类
final class LinkedValueIterator extends LinkedHashIterator implements Iterator<V> { public final V next() { return nextNode().value; }}LinkedEntryIterator类
final class LinkedEntryIterator extends LinkedHashIterator implements Iterator<Map.Entry<K,V>> { public final Map.Entry<K,V> next() { return nextNode(); }LinkedHashMap到这里就看完了,LinkedHashMap和HashMap确实很相似,HashMap的特性LinkedHashMap都有,LinkedHashMap中的操作基本上都是为了维护具有访问顺序的双向循环链表。
总结
HashMap与LinkedHashMap比较
不同点
相同点
- 都是基于哈希表的实现。
- 存储的是键值对映射。
- 都继承了AbstractMap,实现了Map、Cloneable、Serializable。
- 它们的构造函数都一样。
- 默认的容量大小是16,默认的加载因子是0.75。
- 都允许key和value为null。
- 都是线程不安全的。
更多文章:
- Java8容器源码-目录
- Java8容器源码-整体结构
- Java8容器源码-ArrayList
- ArrayList与迭代器模式
- Java8容器源码-Vector
- Vector与迭代器模式
- Java8容器源码-详解fail-fast
- Iterator与Enumeration
- Java8容器源码-LinkedList
- LinkedList与迭代器模式
- Java8容器源码-Stack
- Java8容器源码-List总结
- Java8容器源码-Map整体架构
- Java8容器源码-HashMap
- Java8容器源码-Hashtable(1)
- Java8容器源码-Hashtable(2)
- Java8容器源码-LinkedHashMap
- Java8容器源码-WeakHashMap
- Java8容器源码-TreeMap
- Java8容器源码-Map总结
原文地址:CSDN博客-潘威威的博客-http://blog.csdn.net/panweiwei1994/article/details/77483778
本文版权归作者所有,欢迎转载,但转载时请在文章明显位置给出原文作者名字(潘威威)及原文链接,否则作者将保留追究法律责任的权利。
- Java8 - LinkedHashMap源码
- Java8源码-LinkedHashMap
- JAVA8 linkedhashmap 源码阅读笔记
- LinkedHashMap源码
- 【源码】LinkedHashMap源码剖析
- 【源码】LinkedHashMap源码剖析
- Map(二)之LinkedHashMap(java8)
- HashMap LinkedHashMap源码分析
- LinkedHashMap源码分析
- LinkedHashMap源码浅析
- 【源码学习-LinkedHashMap】
- LinkedHashMap源码分析
- LinkedHashMap源码浅析
- LinkedHashMap源码阅读
- LinkedHashMap源码分析
- LinkedHashMap源码分析
- LinkedHashMap 源码解析
- LinkedHashMap源码解析
- 泛型的定义和使用
- 进程与线程之间那些事儿:
- 简单的数据库操作与变量
- 【bzoj2789】[Poi2012]Letters
- effective C++ 条款二十六解读
- Java8源码-LinkedHashMap
- jackson annotations注解详解
- uVa1586 元素周期表
- shell命令
- 股彩赌明日股涨跌
- 关于近期爬虫学习的总结
- solr学习一:solr6.6单机环境Linux搭建
- Android studio上面学习Aidl实现复杂数据类型的传递
- 基数排序(转载)


