7. 机器学习基石-How can Machine Learn?
来源:互联网 发布:源数网络卡组 编辑:程序博客网 时间:2024/05/16 10:10
How can Machine Learn? - Linear Regression
- How can Machine Learn? - Linear Regression
- 1. What is Regression
- 2. Linear Regression
- 1) Introduction of Linear Regression
- 2) Error Measurement of Linear Regression
- 3) Linear Regression Algorithm
- 4) Generalization Issue
- 5) Linear Regression for Binary Classification
- Reference
1. What is Regression
机器学习算法一般是这样一个步骤:
对于一个问题,用数学语言来描述它,然后建立模型,e.g., 回归模型或者分类模型;
建立代价函数: Cost Function, 用最大似然、最大后验概率或者最小化分类误差等等数,也就是一个最优化问题。找到最优化问题的解,也就是能拟合我们的数据的最好的模型参数;
求解这个代价函数,找到最优解。求解也就分很多种情况了:
1). 如果这个优化函数存在解析解。例如我们求最值一般是对代价函数求导,找到导数为0的点,也就是最大值或者最小值的地方了。如果代价函数能简单求导,并且求导后为0的式子存在解析解,那么我们就可以直接得到最优的参数了: Gradient Descent。
2). 如果式子很难求导,例如函数里面存在隐含的变量或者变量相互间存在耦合,也就互相依赖的情况。或者求导后式子得不到解释解,例如未知参数的个数大于已知方程组的个数等。这时候我们就需要借助迭代算法来一步一步找到最有解了。
3). 另外需要考虑的情况是,如果代价函数是凸函数,那么就存在全局最优解。
回归(Regression)问题与分类(Classification)问题类似,关键的区别在于,Regression的输出是实数,是一个范围,所以不能提前确定所有输出值;而Classification的输出是确定的值。换个角度说,假如输出足够多的数据的时候:如果输出的值是连续的,这个问题叫做Regression,而如果输出的值是离散的,那么这个问题叫做Classification
用数学符号表示如果公式(1)所示。
2. Linear Regression
1) Introduction of Linear Regression
线性回归问题同样的表示各个属性(Attribution)对最终结果的贡献:也就是说每个属性乘以对应的权值,最后再加上一定的偏移,如公式(2)所示
如果给第一项的偏移
Hypothesis h(x):
从公式(3)的可以看出,与二元分类假设函数的表示只差了一个取正负号的函数
2) Error Measurement of Linear Regression
线性回归问题的错误如图一所示。 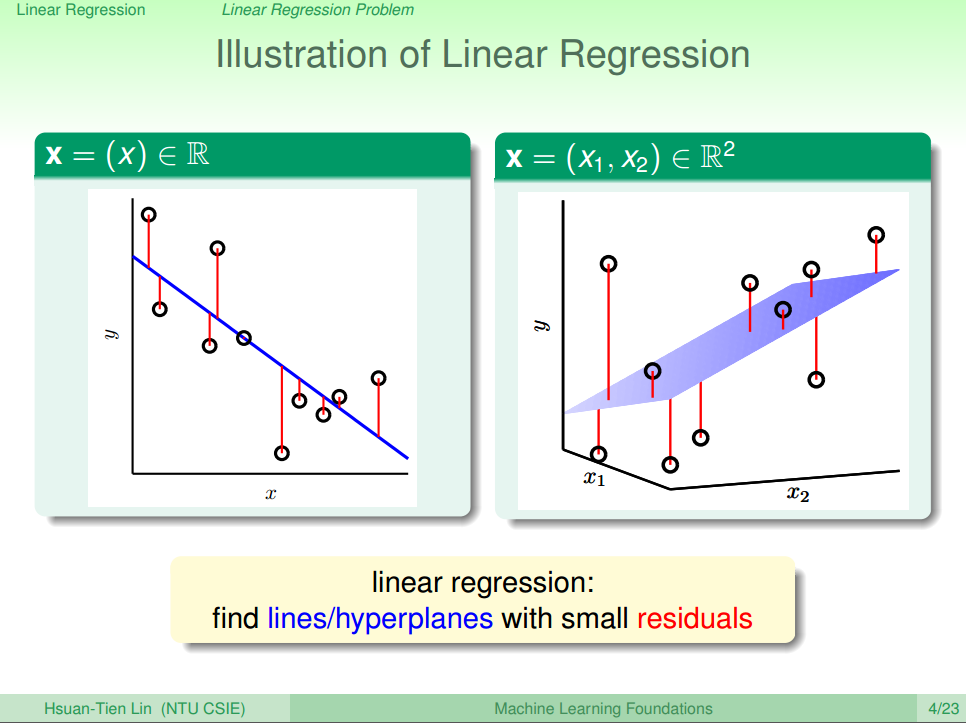
上一章中,提到了回归问题我们用平方误差来表示(其实还有RMSE, R2等方法,老师上课只讲了平方误差,为了说明方便,我们只写这个)
根据图一的信息,很明显得到公式(4)(5)。
VC Bound可以约束各种情况的学习模型,当然回归类型的模型也被也受此约束,只需要寻找足够小
3) Linear Regression Algorithm
刚刚上面的Error Meansurement中,我们提到了VC Bound中,在训练样本足够的情况下,我们要用特定的算法,来找到最小的
根据公式(6),那么
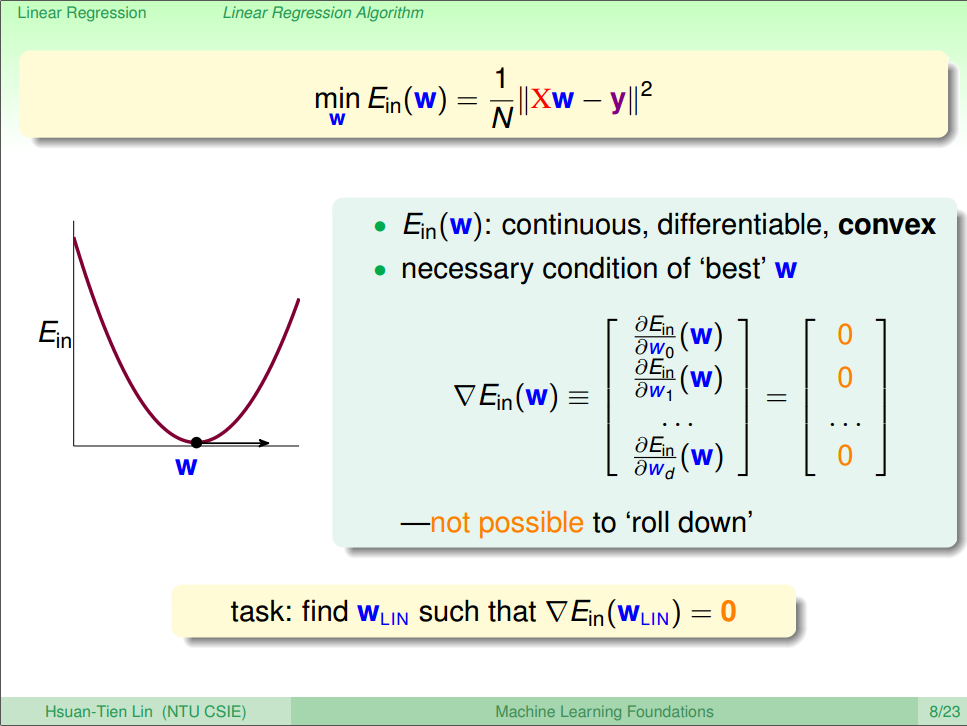
所以接下来,我们需要对
1. 首先我们需要考虑两种情况:①只有一个w; ②w为向量
2. 首先我们把公式(6)平方去掉
3. 只有一个w的时候,就按照正常的求导方式求导即可,得到公式(7)
4. 当w为向量的时候,我们需要对其中一个进行转置,然后再求导,得到公式(8)
5. 根据公式(7)(8)可以看出,两种情况的求导的结果非常相似,可以用公式(9)表示
6. 最后我们令公式(9)的值为0,得到我们需要的
4) Generalization Issue
上一节中,我们得到了最佳的 w 的解,但是,哪个是最小的
结论就是得到了
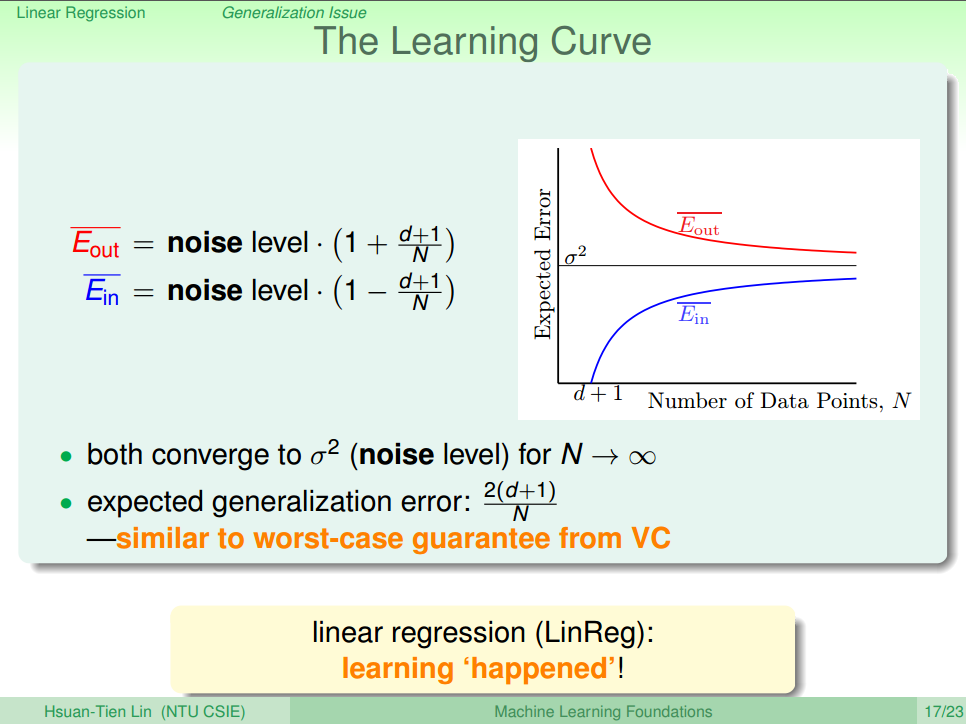
可以看出在N趋于无穷大时,与两者都会趋近于noise level的值,即
至此可以表明在线性回归中可以寻找到很好的
5) Linear Regression for Binary Classification
这一节,我们主要讨论能否通过求解线性回归的方式求二元分类问题
首先对比Linear Classification 和 Linear Regression, 如图四

从求解问题的难度考虑,二元分类的求解是一个NP难问题,只能近似求解,而线性回归求解方便,程序编写也简单。
直觉告诉我们:因为二元分类的输出空间{-1,+1}属于线性回归的输出空间,即
下面给出证明:
入手点:误差大小
首先对比两种方法的曲线图,如图五所示。 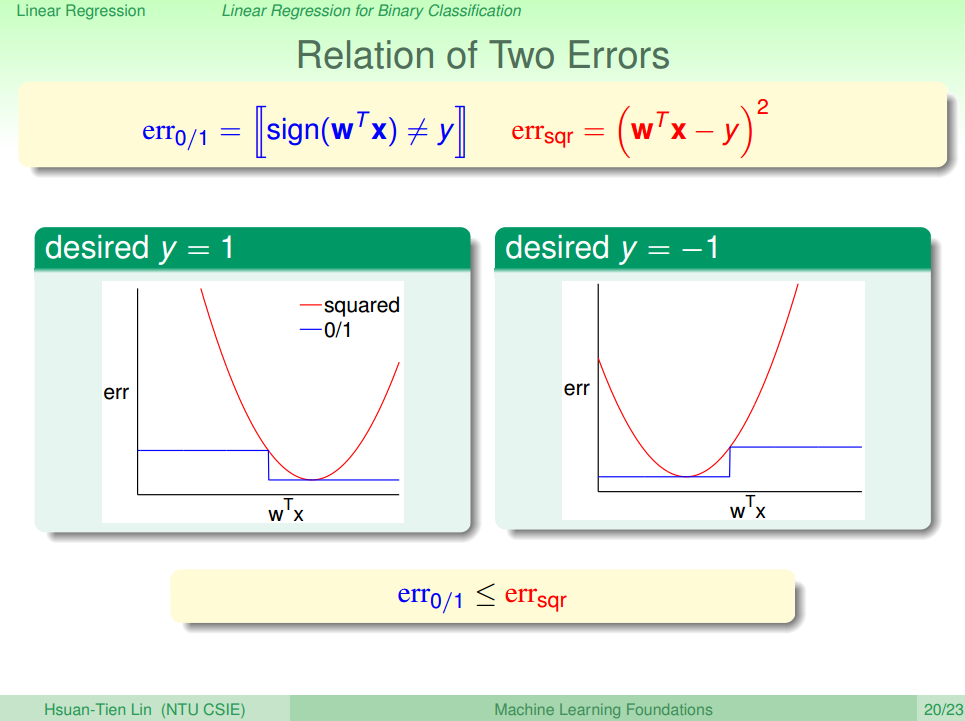
可以发现,无论期望的y为-1还是+1,
所以我们可以通过使用 Linear Regression 的方法来求解Linear Classification的问题,虽然通过这种方法,得到的误差可能更大,但却是一种更有效率的求解方式。在实际运用中,一般都将通过线性回归求得的解析解作为PLA或者pocket的初始值,达到快速求解的目的 。
Summary
- 首先介绍了Regression。
- 然后通过例子引入Linear Regression,分别介绍Linear Regression的误差方程,算法流程。
- 接着我们引入VC Bound 解释了Linear Regression为什么可以实现学习。
- 最后我们应用Linear Regression的算法到Classification的问题中:虽然会损失一定的准确度,但是效率提升很大。
Reference
[1] 机器学习基石(台湾大学-林轩田)\9\9 - 1 - Linear Regression Problem (10-08)
[2] 机器学习基石(台湾大学-林轩田)\9\9 - 3 - Generalization Issue (20-34)
[3] 机器学习基石(台湾大学-林轩田)\9\9 - 4 - Linear Regression for Binary Classification (11-23)
- 7. 机器学习基石-How can Machine Learn?
- 8. 机器学习基石-How can Machine Learn?
- 9. 机器学习基石-How can Machine Learn?
- 10. 机器学习基石-How can Machine Learn?
- 12. 机器学习基石-How can Machine Learn Better?
- 13. 机器学习基石-How can Machine Learn Better?
- 14. 机器学习基石-How can Machine Learn Better?
- 1. 机器学习基石-When can Machine Learn?
- 2. 机器学习基石-When can Machine Learn?
- 3. 机器学习基石-When can Machine Learn?
- 4. 机器学习基石-When can Machine Learn?
- 5. 机器学习基石-Why can Machine Learn?
- 6. 机器学习基石-Why can Machine Learn?
- 11.How can Machine Learn Better?
- 机器学习基石-Dual Support Vector Machine
- 机器学习基石HOW部分(1)
- 机器学习基石HOW部分(2)
- 机器学习基石HOW部分(3)
- java集合类框架的基本接口有哪些
- 获取子字符串
- 深入浅出ActiveMQ(四)--Spring和ActiveMQ整合的完整实例
- ajax请求中contentType与dataType区别
- 条件,循环基本语法
- 7. 机器学习基石-How can Machine Learn?
- 这是一场数学、数学、数学的盛会
- Hibernate用SchemaExport自动创建不了表
- centos7安装出现license information(license not accepted)解决办法
- 运维之红帽管理员篇-----6. 分区规划及使用 、 LVM逻辑卷 、 管理交换空间
- TCP与UDP区别总结
- APK手动编译全过程
- android+okhttp
- Logger:封装系统log的日志打印工具


