11.How can Machine Learn Better?
来源:互联网 发布:虚拟币交易所源码 编辑:程序博客网 时间:2024/05/25 05:35
How can Machine Learn Better? - Overfitting and Solution
1. What is Overfitting?
上一节最后,我们提到了如果线性模型的模型复杂度太大的话,可能会引起Overfitting。同样的很明显会有Underfitting的情况。
那什么是Overfitting,Underfitting呢?
首先根据名字,Overfitting:over fitting,就是在fitting的时候太over了。我们用线性模型去分类/回归处理数据的过程就是一个fitting的过程,所以也就是说我们处理过头了。同理Underfitting就是处理不够到位。
那么什么时候才是处理过头呢?什么时候才是处理不到位呢?
就是在处理相对简单的问题的时候用了相对复杂的模型去处理。
就是在处理相对复杂的问题的时候用了相对简单的模型去处理。
我们用下面的例子来进行说明
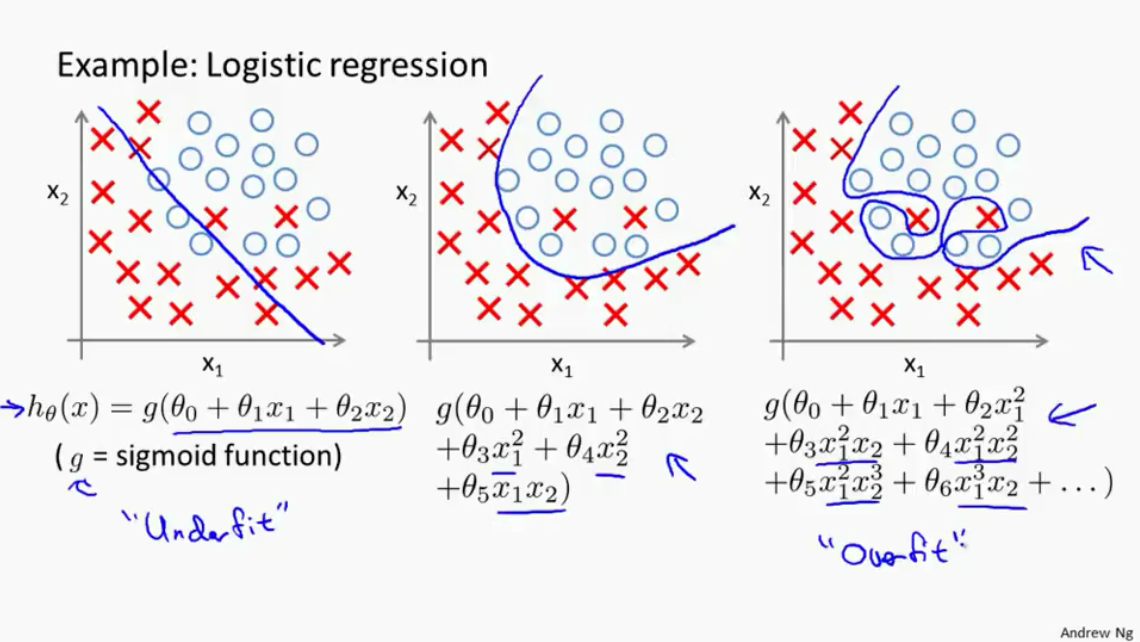
1.首先例子如图一所示(这里用的是Ng的图,因为在林老师的ppt中没找到很好地图同时体现Underfit, good fit overfit)。左图是欠拟合(underfit),中间的图四好的拟合(good fit),右图是过度拟合(overfit)。单纯从拟合结果来看:明显左边和中间的图
假如我们考虑good fit分类出错的点为噪音点(noise),那么Overfit的模型就会受到了严重的干扰。
- 接着我们回头看之前总结的VC Dimension 的曲线, 如图二所示。
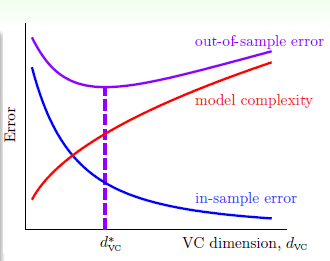
图二 Learning Curve [1]
图中可以看到在VC Dimension变大时,
- 过拟合(Overfitting)发生在VC Dimension较大时,
- 欠拟合(Underfitting)发生在在VC Dimension较小时,
关于如何解决欠拟合的问题之前也讨论过: 从低到高不断地提高多项式次数,使得VC维提高,达到拟合的效果。
但过拟合的问题更为复杂,下面会更深入的探讨。
- 下面的图三,可以让我们更加直观的看到overfitting造成的问题
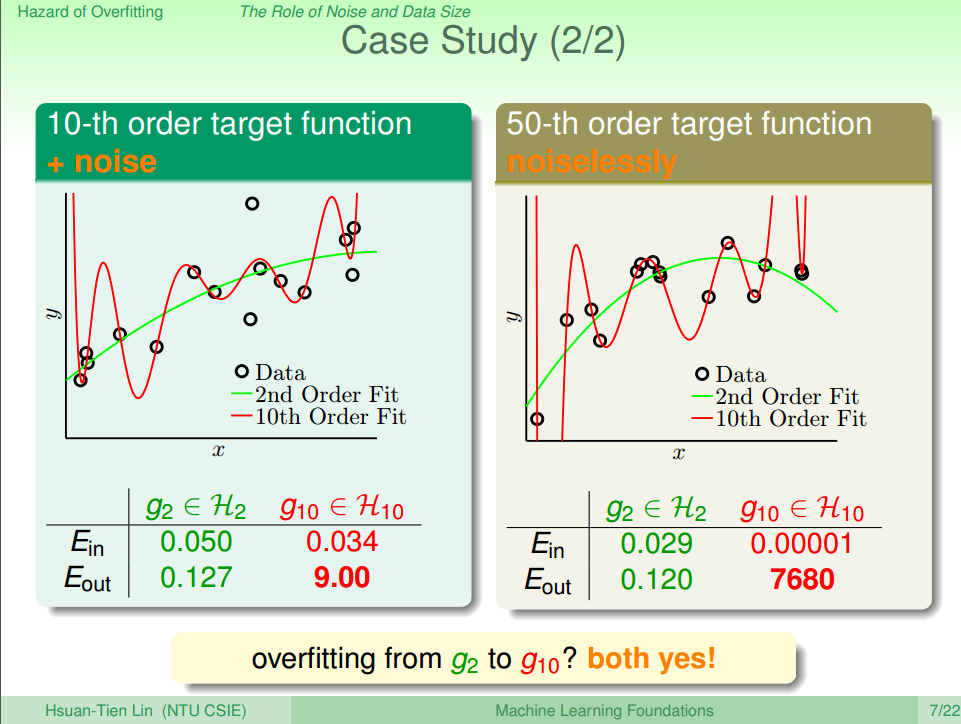
从图中可以看到,Overfitting的
总结起来有3个因数会导致Overfitting的发生:
- data size N 太小
- noise 太多
- VC Dimension太大
2. Dealing with Overfitting
上一节我们提出了overfitting并作了分析。总结出3个因数会导致overfitting,下面根据这3个因数,我们有5种方法帮助我们避免overfitting的发生。
- 使用简单的模型(start from simple model),逐次增加模型的复杂度 - 防止 VC Dimension太大
- 进行数据清理/裁剪(data cleaning/pruning) - 防止 noise 太多
- 数据提示(data hinting) - 防止 data size N 太小
- 正则化(regularization) - 防止 VC Dimension太大
- 确认(validation) - 提取一部分的数据作为测试集,提前估计模型的泛化强度
下面我们分别介绍这5种方法,其中前三种方法比较简单,这里不做深入讨论,而 Regularization 和 Validation 较复杂,这里会用比较多的笔墨进行讨论。
1) Start from Simple Model
上一章中也提到过,由于VC Dimension太大的话,导致
2) Data Cleaning/Pruning
Data cleaning/pruning就是对训练数据集里label有明显错误的样本进行清理(data cleaning)或者裁剪(pruning)。data cleaning/pruning关键在于如何准确寻找label错误的点或者是noise的点。而处理的方法为
- 纠正,即数据清理(data cleaning)的方式处理该情况;
- 删除错误样本,即数据裁剪(data pruning)的方式处理。
处理措施很简单,但是发现样本是噪音或离群点却比较困难。
3) Data Hinting
Data hinting是针对N不够大的情况,通过data hinting的方法就可以对已知的样本进行简单的处理、变换,从而获得更多的样本。比如说:数字分类问题,可以对已知的数字图片进行轻微的平移或者旋转,从而得到更多的数据,达到扩大训练集的目的。这种通过data hinting得到的数据叫做:virtual examples。
需要注意的是,新获取的virtual examples可能不再是iid某个distribution。所以新构建的virtual examples要尽量合理,且是独立同分布的。
4) Regularization
Regularization(正规化)处理属于penalized方法的一种,通过正规化的处理来对原来的方程加上一个regularizer进行penalize,从而使得过渡复杂的模型,变得没那么复杂。
关于Regularization 的讨论看此链接:
12. 机器学习基石-How can Machine Learn Better? - Regularization
5) Validation
这个是目前最常用的方法之一,通过提前把一部分的数据拿出来作为测试集,因为测试集是随机取出来的,而将来实际的应用中,数据也大体和测试集出入不大,所以用这种方法,可以提前得到实际应用的时候,模型的错误
关于Validation 的讨论看此链接
13. 机器学习基石-How can Machine Learn Better? - Validation
Summary
1.首先介绍了Overfitting和Underfitting的概念。
2.接着我们着重分析Overfitting,总结了产生Overfitting的原因:
data size N 太小
noise 太多
VC Dimension太大
3.最后我们分析如何最大程度的避免Overfitting。在solution中.
Reference
[1] 机器学习基石(台湾大学-林轩田)\13\13 - 1 - What is Overfitting- (10-45)
[2] 机器学习基石(台湾大学-林轩田)\13\13 - 2 - The Role of Noise and Data Size (13-36)
- 11.How can Machine Learn Better?
- 12. 机器学习基石-How can Machine Learn Better?
- 13. 机器学习基石-How can Machine Learn Better?
- 14. 机器学习基石-How can Machine Learn Better?
- 7. 机器学习基石-How can Machine Learn?
- 8. 机器学习基石-How can Machine Learn?
- 9. 机器学习基石-How can Machine Learn?
- 10. 机器学习基石-How can Machine Learn?
- how-to-learn-machine-learning
- How can you learn faster
- 1. 机器学习基石-When can Machine Learn?
- 2. 机器学习基石-When can Machine Learn?
- 3. 机器学习基石-When can Machine Learn?
- 4. 机器学习基石-When can Machine Learn?
- 5. 机器学习基石-Why can Machine Learn?
- 6. 机器学习基石-Why can Machine Learn?
- How to learn to stop worrying and love machine learning
- learn how to learn
- HIVE
- cocos js-binding相关资料
- 懒人读算法(八)-所有子集
- 更新vim8.0后,MacVim中YouCompleteMe出错
- 国家发展智慧城市的8个战略
- 11.How can Machine Learn Better?
- 指定TensorFlow使用哪一个GPU
- Linux操作小结
- oracle的事务和隔离级别
- c/c++面向对象编程之共用数据的保护
- Verilog带参数的module实例化的方式
- hosts文件里面做域名映射
- iOS数据存储方法介绍
- JDK部分源码阅读与理解


