13. 机器学习基石-How can Machine Learn Better?
来源:互联网 发布:世界核武国家 知乎 编辑:程序博客网 时间:2024/06/04 19:16
How can Machine Learn Better? - Validation
- How can Machine Learn Better? - Validation
- 1. Model Selection Problem
- 2. Validation
- 3. Leave-One-Out Cross Validation
- 4. V-Fold Cross Validation
- Summary
- Reference
这一节我们Validation,需要选择的原因是机器学习的算法有很多种,如何评估哪一种适合当前的使用场景是一个值得商榷的问题。所以通过Validation,我们可以对模型的误差有一定的测试,评估,从而可以确定我们所需要的模型。
1. Model Selection Problem
到目前为止,已经学过了许多算法模型,但一个模型需要很多参数的选择,这是本章讨论的重点。
以二元分类为例,在学过的算法有PLA、pocket、线性回归、logistic回归;算法中需要用到迭代方法,就需要选择迭代步骤T;同理也需要选择学习步长 ;处理非线性问题时,需要用到不同的转换函数,可能是线性的,二次式,10次多项式或者10次勒让德多项式;如果加上正则化项,则可以选择L2正则化项,L1正则化项;有了正则化项,则参数 值也需要选择。
在如此多的选项中设计一个适用于各种情况各个数据集的模型显然是不可能的,因此针对不同的情况,对各个参数的选择是必须的。
我们主要是通过误差 E 来进行判断一个模型是否良好的。我们有
1. 显然我们不能通过
2. 但是我们也不能通过
但是我们能否采用另一个相对宽松的误差来作为评估呢?比如说:有这样一个独立于训练样本的测试集,将M个模型在测试集上进行测试,看一下Etest的大小,则选取Etest最小的模型作为最佳模型。
是可以的,因为我们有Hoeffding Inequity作为理论保证
下面我们将讨论这个宽松的误差。
1.首先,这个最小的测试集选出来的权值满足公式(1),其中
2.这种测试集验证的方法,根据finite-bin Hoffding不等式,可以得到公式(2),并且可以看出,模型个数M越少,测试集数目越大,那么
下面比较一下使用
1. 使用
2. 第使用
下面,我们针对验证集的选择进行讨论。
2. Validation
验证集的选择,我们必须遵循几点:
1. 选择要随机 - 造成数据不平衡,结果有问题
2. 数据量分配要合理 - 过多的验证集会造成训练集的减少,过少的验证集验证结果可信度不高
3. 验证集必须是新的,没有被用于训练 - 那就等于是直接用训练集去做验证了
所以为了满足这3个条件,我们下面需要讨论如何来划分数据集
1.首先我们将原本的数据样本D分为两部分: 训练数据

2.根据Hoeffding Inequity,我们可以得到公式(4)
下面我们举个例子来解释这种模型选择的方法的优越性,假设有两个模型:一个是5阶多项式HΦ5,一个是10阶多项式HΦ10。通过不使用验证集和使用验证集两种方法对模型选择结果进行比较,分析结果如图二所示

图中,横坐标表示验证集数量K,纵坐标表示
红色曲线表示使用验证集,但是最终选取的矩是
但是也存在问题,当 K 太大的时候,红色曲线会超过黑色直线,也就是上面提到的,选择了太多的数据作为验证集,从而导致训练的数据大大减少,那么模型的泛化能力太差,不能保证
那么如何选择 K呢?
老师的建议是选择
3. Leave-One-Out Cross Validation
上一节,最后我们提到了K值得重要性,下面我们将讨论如何让这个数据取得更加合理。
第一种方法叫做: Leave-One-Out Cross Validation(留一法交叉验证),这方法是采用一种极端的情况(K=1),也就是说验证集大小为1,即每次只用一组数据对
这种算法的优缺点如下:
- 优点:使得
- 缺点:①
误差方程的表达式如公式(3)所示。
该算法的具体流程如下:
1.取n=1的点出来做验证集,其他点保留作为训练集,求出Hypothesis 和对应的 误差
2.接着取n=2的点出来做验证集,其他点保留作为训练集,求出Hypothesis 和对应的 误差
3.以此类推,重复N次,直到n=N的点也进行上述的操作
4.把N次误差加起来求平均
课上举了一个例子说明该方法的效果并且总结了Feature的多少与
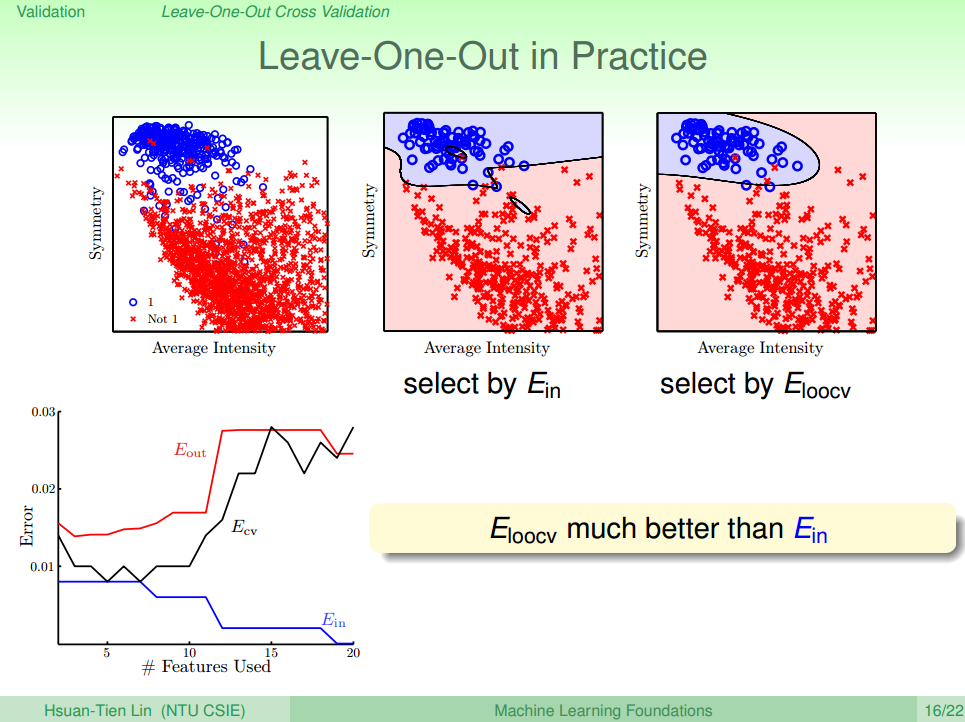
但是这种方法由于他的缺点太多,所以实际中往往很少使用。更多的是使用下面要讨论的V-Fold Cross Validation
4. V-Fold Cross Validation
上面讨论的Leave-One-Out Cross Validation 的优缺点导致了该算法不好用。所以针对该算法的缺点,人们对其改进为V-Fold Cross Validation: 这种算法是把数据N平均分为V分,每次取一份作为验证集,剩下的V-1份作为测试集,重复V次,算出平均误差。那样的话Leave-One-Out Cross Validation 可以看成是V=N的极端情况
该算法的误差方程如公式(4)所示
一般的Validation使用V-Fold Cross Validation来选择最佳的模型。
但是该算法也有一点问题:就是Validation的数据来源是集中的,所以并不能保证交叉验证的效果好,得到的数学模型一定就很好。只有在样本数据足够多的时候,结果才可信,数学模型泛化能力越强。
Summary
- 首先介绍了validation验证的意义
- 然后介绍了Leave-One-Out算法并分析其优劣:该算法在实际应用不多
- 最后根据Leave-One-Out算法的缺点,做改进,提出了V-Fold Cross Validation
Reference
[1] 机器学习基石(台湾大学-林轩田)\15\15 - 1 - Model Selection Problem (16-00)
[2] 机器学习基石(台湾大学-林轩田)\15\15 - 3 - Leave-One-Out Cross Validation (16-06)
- 13. 机器学习基石-How can Machine Learn Better?
- 12. 机器学习基石-How can Machine Learn Better?
- 14. 机器学习基石-How can Machine Learn Better?
- 7. 机器学习基石-How can Machine Learn?
- 8. 机器学习基石-How can Machine Learn?
- 9. 机器学习基石-How can Machine Learn?
- 10. 机器学习基石-How can Machine Learn?
- 1. 机器学习基石-When can Machine Learn?
- 2. 机器学习基石-When can Machine Learn?
- 3. 机器学习基石-When can Machine Learn?
- 4. 机器学习基石-When can Machine Learn?
- 5. 机器学习基石-Why can Machine Learn?
- 6. 机器学习基石-Why can Machine Learn?
- 11.How can Machine Learn Better?
- 机器学习基石HOW BETTER部分(1)
- 机器学习基石HOW BETTER部分(3)
- 机器学习基石HOW BETTER部分(4)
- 机器学习基石HOW BETTER部分(2)
- 叉姐200题
- php yii2跑数出现mysql-gone-away-2006解决
- 苹果匠艺:乔布斯身边的天才
- JVM_8_内存分配与回收策略
- laravel报TokenMismatchException
- 13. 机器学习基石-How can Machine Learn Better?
- Procute is not mapped [from Procute]
- mysql 在 ubuntu 下学习
- ZooKeeper学习之配置【1】基本配置
- c++获取毫秒级时间 windows
- mysql查询当天、本周、最近xx天、本月 的数据
- BP神经网络后向传播算法
- 8位单片机 16位 32位区别?
- CString 转 char *


