Chrome源码剖析--Chrome的多线程模型 上
来源:互联网 发布:javascript box2d 编辑:程序博客网 时间:2024/05/29 14:46
0. Chrome的并发模型
如果你仔细看了前面的图,对Chrome的线程和进程框架应该有了个基本的了解。Chrome有一个主进程,称为Browser进程,它是老大,管理Chrome大部分的日常事务;其次,会有很多Renderer进程,它们圈地而治,各管理一组站点的显示和通信(Chrome在宣传中一直宣称一个tab对应一个进程,其实是很不确切的...),它们彼此互不搭理,只和老大说话,由老大负责权衡各方利益。它们和老大说话的渠道,称做IPC(Inter-Process Communication),这是Google搭的一套进程间通信的机制,基本的实现后面自会分解。。。
Chrome的进程模型
Google在宣传的时候一直都说,Chrome是one tab one process的模式,其实,这只是为了宣传起来方便如是说而已,基本等同广告,实际疗效,还要从代码中来看。实际上,Chrome支持的进程模型远比宣传丰富,你可以参考一下这里 ,简单的说,Chrome支持以下几种进程模型:
- Process-per-site-instance:就是你打开一个网站,然后从这个网站链开的一系列网站都属于一个进程。这是Chrome的默认模式。
- Process-per-site:同域名范畴的网站放在一个进程,比如www.google.com和www.google.com/bookmarks就属于一个域名内(google有自己的判定机制),不论有没有互相打开的关系,都算作是一个进程中。用命令行--process-per-site开启。
- Process-per-tab:这个简单,一个tab一个process,不论各个tab的站点有无联系,就和宣传的那样。用--process-per-tab开启。
- Single Process:这个很熟悉了吧,传统浏览器的模式,没有多进程只有多线程,用--single-process开启。
关于各种模式的优缺点,官方有官方的说法,大家自己也会有自己的评述。不论如何,至少可以说明,Google不是由于白痴而采取多进程的策略,而是实验出来的效果。。。
大家可以用Shift+Esc观察各模式下进程状况,至少我是观察失败了(每种都和默认的一样...),原因待跟踪。。。
不论是Browser进程还是Renderer进程,都不只是光杆司令,它们都有一系列的线程为自己打理各种业务。对于Renderer进程,它们通常有两个线程,一个是Main thread,它负责与老大进行联系,有一些幕后黑手的意思;另一个是Render thread,它们负责页面的渲染和交互,一看就知道是这个帮派的门脸级人物。相比之下,Browser进程既然是老大,小弟自然要多一些,除了大脑般的Main thread,和负责与各Renderer帮派通信的IO thread,其实还包括负责管文件的file thread,负责管数据库的db thread等等(一个更详细的列表,参见这里 ),它们各尽其责,齐心协力为老大打拼。它们和各Renderer进程的之间的关系不一样,同一个进程内的线程,往往需要很多的协同工作,这一坨线程间的并发管理,是Chrome最出彩的地方之一了。。。
闲话并发
单进程单线程的编程是最惬意的事情,所看即所得,一维的思考即可。但程序员的世界总是没有那么美好,在很多的场合,我们都需要有多线程、多进程、多机器携起手来一齐上阵共同完成某项任务,统称:并发(非官方版定义...)。在我看来,需要并发的场合主要是要两类:
- 为了更好的用户体验。有的事情处理起来太慢,比如数据库读写、远程通信、复杂计算等等,如果在一个线程一个进程里面来做,往往会影响用户感受,因此需要另开一个线程或进程转到后台进行处理。它之所以能够生效,仰仗的是单CPU的分时机制,或者是多CPU协同工作。在单CPU的条件下,两个任务分成两拨完成的总时间,是大于两个任务轮流完成的,但是由于彼此交错,更人的感觉更为的自然一些。
- 为了加速完成某项工作。大名鼎鼎的Map/Reduce,做的就是这样的事情,它将一个大的任务,拆分成若干个小的任务,分配个若干个进程去完成,各自收工后,在汇集在一起,更快的得到最后的结果。为了达到这个目的,只有在多CPU的情形下才有可能,在单CPU的场合(单机单CPU...),是无法实现的。
在第二种场合下,我们会自然而然的关注数据的分离,从而很好的利用上多CPU的能力;而在第一种场合,我们习惯了单CPU的模式,往往不注重数据与行为的对应关系,导致在多CPU的场景下,性能不升反降。。。
1. Chrome的线程模型
仔细回忆一下我们大部分时候是怎么来用线程的,在我足够贫瘠的多线程经历中,往往都是这样用的:起一个线程,传入一个特定的入口函数,看一下这个函数是否是有副作用的(Side Effect),如果有,并且还会涉及到多线程的数据访问,仔细排查,在可疑地点上锁伺候。。。
Chrome的线程模型走的是另一个路子,即,极力规避锁的存在。换更精确的描述方式来说,Chrome的线程模型,将锁限制了极小的范围内(仅仅在将Task放入消息队列的时候才存在...),并且使得上层完全不需要关心锁的问题(当然,前提是遵循它的编程模型,将函数用Task封装并发送到合适的线程去执行...),大大简化了开发的逻辑。。。
不过,从实现来说,Chrome的线程模型并没有什么神秘的地方(美女嘛,都是穿衣服比不穿衣服更有盼头...),它用到了消息循环的手段。每一个Chrome的线程,入口函数都差不多,都是启动一个消息循环(参见MessagePump类),等待并执行任务。而其中,唯一的差别在于,根据线程处理事务类别的不同,所起的消息循环有所不同。比如处理进程间通信的线程(注意,在Chrome中,这类线程都叫做IO线程,估计是当初设计的时候谁的脑门子拍错了...)启用的是MessagePumpForIO类,处理UI的线程用的是MessagePumpForUI类,一般的线程用到的是MessagePumpDefault类(只讨论windows, windows, windows...)。不同的消息循环类,主要差异有两个,一是消息循环中需要处理什么样的消息和任务,第二个是循环流程(比如是死循环还是阻塞在某信号量上...)。下图是一个完整版的Chrome消息循环图,包含处理Windows的消息,处理各种Task(Task是什么,稍后揭晓,敬请期待...),处理各个信号量观察者(Watcher),然后阻塞在某个信号量上等待唤醒。。。
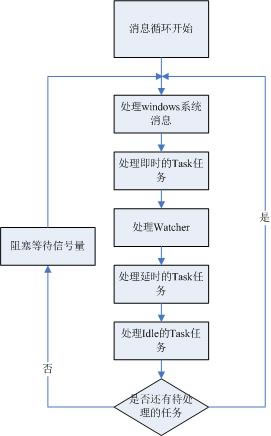
图2 Chrome的消息循环
当然,不是每一个消息循环类都需要跑那么一大圈的,有些线程,它不会涉及到那么多的事情和逻辑,白白浪费体力和时间,实在是不可饶恕的。因此,在实现中,不同的MessagePump类,实现是有所不同的,详见下表:
MessagePumpDefaultMessagePumpForIOMessagePumpForUI是否需要处理系统消息否是是是否需要处理Task是是是是否需要处理Watcher否是否是否阻塞在信号量上否是是- Chrome源码剖析--Chrome的多线程模型 上
- Chrome源码剖析【一】 Chrome的多线程模型
- Chrome源码剖析--Chrome的多线程模型 下
- Chrome源码剖析--Chrome的多线程模型 中
- Chrome源码剖析--Chrome的多线程模型 下
- Chrome源码剖析【一】 Chrome的多线程模型
- Chrome源码剖析 【一】 Chrome的多线程模型
- Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Chrome源码剖析--Chrome的进程模型
- Chrome源码剖析-- Chrome的插件模型
- 【chrome】Chrome源码剖析、上--多线程模型、进程通信、进程模型
- Google Chrome源码剖析【一】:多线程模型
- Google Chrome源码剖析【一】:多线程模型
- Chrome源码剖析、上
- Chrome源码剖析-- 序
- CRM的认知
- 栈的链表表示
- 使用MFC数组类- 文章推荐
- 软件版本命名规范
- Chrome源码剖析--Chrome的多线程模型 上
- ActiveX和OLE有什么区别?
- Android Activity 生命周期
- Chrome源码剖析--Chrome的多线程模型 下
- 进程间通信:Windows下进程间通信的手段
- Windows服务
- Windows下与Linux下编写socket程序的区别
- 工作第一天
- Chrome源码剖析--Chrome的进程间通信 上


