二分搜索算法
来源:互联网 发布:vy是什么意思网络用语 编辑:程序博客网 时间:2024/04/30 04:23
一、简介
二分搜索适用于高效搜索已经排好序的表。搜素过程从表的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果待查找元素大于或者小于中间元素,则在表大于或小于中间元素的那一半中查找。如果在某一步骤搜索范围为0,则代表找不到。
二、实现与分析
这里给出二分搜索的一种实现:
private int binary_search(int l, int r, int key){if(r < l)return -1; int mid = (l + r) / 2;if(key < a[mid])return binary_search(l, mid - 1, key);else if(key > a[mid])return binary_search(mid + 1, r, key);else return mid;}其中,要搜索的表是数组a,整数l和r确定了搜索在表中的范围,key就是要搜索的关键字,这里是一个整数。显而易见,该算法是递归地进行的。 为了深入理解二分搜索的执行过程,可以将其过程用一棵二叉决策树来表示。决策树的构造方法如下:

最终的结果如下图所示:

每一次搜索都对应树中的一条路径。如果搜索成功,最后到达内部(圆)结点;如果搜索失败,就会到达叶子(方)结点。显然,一次搜索的时间复杂度由决策树的高度决定,即O(logN)。没有基于比较的搜索方法能比这个结果更好了。这里介绍一个来自Donald. E. Knuth的定理1:

小结一下,上述二分搜索算法的比较次数不会超过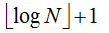 ,并且平均每次成功的搜索需要大约logN-1次比较。没有基于比较的搜索方法优于这个算法。
,并且平均每次成功的搜索需要大约logN-1次比较。没有基于比较的搜索方法优于这个算法。
,并且平均每次成功的搜索需要大约logN-1次比较。没有基于比较的搜索方法优于这个算法。下面给出另一种实现方法。在上面代码的binary_search方法中,使用了l、r和mid三个位置变量。而实际上,只需要两个变量的就够了。一个变量i记录当前的边界(左或右),一个记录搜索范围的大小。先给出代码如下:
private int uniform_binary_search(int i, int m, int key) { if(key < a[i]) { if(m == 0) return -1; else return uniform_binary_search(i - (int)Math.ceil(m / 2), m / 2, key); } else if(key > a[i]) { if(m == 0) return -1; else return uniform_binary_search(i + (int)Math.ceil(m / 2), m / 2, key); } else return i; }注意,这个算法执行前i设置为N/2向上取整,m设置为N/2向下取整。向左搜索时,i存储了搜素范围的右边界;向右搜索时,i存储了左边界。m则始终为搜索范围的大小,即当前要搜索的元素个数为m或m-1。这个算法过程统一可以构造二叉决策树如下:
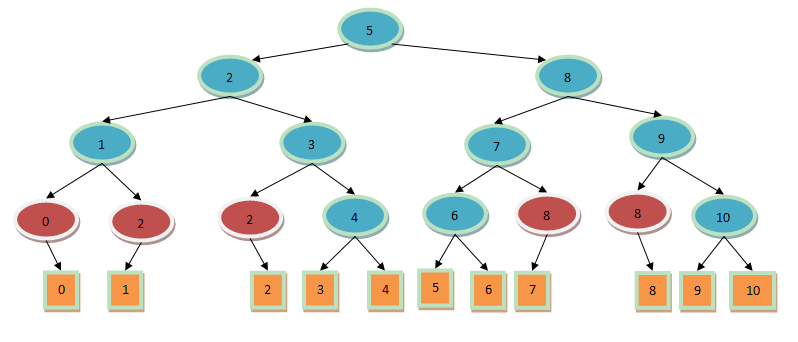
红色的结点表示有重复的搜索。方法名中uniform(统一)的含义是,在决策树中同一层次的结点的标号与其父结点的标号之差是统一的。正因为要保证这个特点,才导致有些结点重复出现。而在上面的普通二分搜索中,这个性质不满足。
三、参考资料:
1.wikipedia
2.计算机程序设计艺术第三卷 排序和查找
-------------------------------------------------------------------------
修订:上面定理1中最后一个2^(k-1)应该为2^k。
- 【基础算法】搜索-二分搜索
- C#二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 简单算法--二分搜索
- 二分搜索算法细节
- 研究二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 二分搜索算法
- 分治算法--二分搜索
- java二分搜索算法
- 14条原则 (2) 首先检查最简单的:例如,MFC播放avi的时候在上面画东西
- android SDK开发环境搭建(Android 4.0.3 emulator)
- POJ 2155 Matrix
- 单源最短路径_贪心算法
- 三维立体重建
- 二分搜索算法
- 汇编_ASM_选择排序
- 发现csdn的一个bug
- 在Java语言中访问游标类型详解
- 汇编_ASM_选择排序
- 简单的词法分析器
- Microsoft sqlserver sa无法登陆
- pThread=AfxBeginThread(ThreadFunc,&Info);
- Linux USB subsystem --- USB Debug File System Initialize


