《Thinking In Algorithm》15.堆结构之二项堆
来源:互联网 发布:js 类数组 编辑:程序博客网 时间:2024/05/17 17:17
堆的变体:
- 二叉堆
- 二项堆
- 斐波那契堆
上篇博客中我讲了下数据结构二叉堆,而今天讲的二项堆与他最大的不同是它可以快速的合并成两个堆,通过一个特殊的树结构完成的。
下面列出了三种堆的时间复杂的比较。

次那个上面我们可以看出与二叉堆的差别在于找到最小元素和合并。
二叉堆查找最小元素的时间复杂度为O(1),而二项堆: O(lgn)
二叉堆合并花费:O(n),二项堆:O(lgn)
二项堆是二项树的集合。所以我们讲二项堆之前先来弄明白二项树。
1.二项树
如下图中所示,树B0是由一个结点构成的,Bk是由两棵Bk-1的树组成的,是通过连接他们的树根组成的。即其中一棵树的根变成另一棵树的最左边的孩子。

对于二项式的定义如下:
- 度数为0的二项树只包含一个结点
- 度数为k的二项树有一个根结点,根结点下有k个子女,每个子女分别是度数分别为
 的二项树的根
的二项树的根

- 度数为k的二项树共有
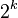 个结点,高度为
个结点,高度为 。在深度d处有
。在深度d处有 (二项式系数)个结点。
(二项式系数)个结点。 - 度数为k的二项树可以很容易从两颗度数为k-1的二项树合并得到:把一颗度数为k-1的二项树作为另一颗原度数为k-1的二项树的最左子树。这一性质是二项堆用于堆合并的基础。
2. 二项堆
二项堆H是满足二项堆特性的二项树的集合。
- 二项堆中每棵二项树都遵循最小堆的特性:即一个结点的值大于或等于他父亲的值。
- 不能有两棵或以上的二项树有相同度数(包括度数为0)。换句话说,具有度数k的二项树有0个或1个。
以上第一个性质保证了二项树的根结点包含了最小的关键字。第二个性质则说明结点数为 的二项堆最多只有
的二项堆最多只有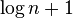 棵二项树。实际上,包含n个节点的二项堆的构成情况,由n的二进制表示唯一确定,其中每一位对应于一颗二项树。例如,13的二进制表示为1101,
棵二项树。实际上,包含n个节点的二项堆的构成情况,由n的二进制表示唯一确定,其中每一位对应于一颗二项树。例如,13的二进制表示为1101,  , 因此具有13个节点的二项堆由度数为3, 2, 0的三棵二项树组成。如下图,a中是简洁的表示法,b中更加详细的表示。
, 因此具有13个节点的二项堆由度数为3, 2, 0的三棵二项树组成。如下图,a中是简洁的表示法,b中更加详细的表示。

二项树的表示方法:
就像上图中的b图,每个二项树利用左孩子右兄弟的方法保存在二项堆中。对于结点x有一个指向父亲的节点p(x),和指向孩子的指针child[x],和指向右兄弟结点的sibling[x]。如果结点x是根节点那么p[x]=NIL.如果节点x没有孩子,那么child[x]=NIL,如果x是父亲最右边的孩子,那么sibling[x]=NIL。x节点有一个度degree[x]表示节点x孩子的数量。
在二项堆中,每棵二项树的树根用链表链接起来,树根的度是严格递增的。
二项堆通过head[H]指向第一个树根这样建立起来的,如果二项堆中没有元素,那么head[H]=NIL.
3. 二项堆的操作
3.1 创建一个二项堆
只需要创建一个对象H,且head[H]=NIL.时间复杂度为O(1).
3.2 找出最小值
因为二项堆是一个最小堆,所以最小的数是在根结点中。从二项堆的第二个性质我们可以知道,一个有n个节点的二项堆最多有lg[n]+1棵树。所以他的时间复杂度为O(lg[n]).实现代码如下:
BINOMIAL-HEAP-MINIMUM(H)1 y ← NIL2 x ← head[H]3 min ← ∞4 while x ≠ NIL5 do if key[x] < min6 then min ← key[x]7 y ← x8 x ← sibling[x]9 return y
3.3 合并两个二项堆
要合并两个二项堆,那么首先要做的是怎样合并两棵二项树,我们假设根结点为y的二项树合并到根结点为z的二项树,y变为z的最左孩子。操作如下:
BINOMIAL-LINK(y, z)1 p[y] ← z2 sibling[y] ← child[z]3 child[z] ← y4 degree[z] ← degree[z] + 1
完成了合并两棵二项树之后,那么我们来进行二项堆的合并。下面代码中用到的BINOMIAL-HEAP-MERGE(H1,H2)操作就是将h1和h2的根列表按照度数递增的顺序重新排列成一个新的二项堆。
BINOMIAL-HEAP-UNION(H1, H2) 1 H ← MAKE-BINOMIAL-HEAP() 2 head[H] ← BINOMIAL-HEAP-MERGE(H1, H2) 3 free the objects H1 and H2 but not the lists they point to 4 if head[H] = NIL 5 then return H 6 prev-x ← NIL 7 x ← head[H] 8 next-x ← sibling[x] 9 while next-x ≠ NIL10 do if (degree[x] ≠ degree[next-x]) or (sibling[next-x] ≠ NIL and degree[sibling[next-x]] = degree[x])11 then prev-x ← x ▹ Cases 1 and 212 x ← next-x ▹ Cases 1 and 213 else if key[x] ≤ key[next-x]14 then sibling[x] ← sibling[next-x] ▹ Case 315 BINOMIAL-LINK(next-x, x) ▹ Case 316 else if prev-x = NIL ▹ Case 417 then head[H] ← next-x ▹ Case 418 else sibling[prev-x] ← next-x ▹ Case 419 BINOMIAL-LINK(x, next-x) ▹ Case 420 x ← next-x ▹ Case 421 next-x ← sibling[x]22 return H
可能直接拿出代码来,你还一头雾水,不要紧,我们跟着代码走一遍的话就懂了。下图是上面代码的运行过程。


从上图中我们可以看出,a-->b执行的是BINOMIAL-HEAP-MERGE(H1,H2)操作,b-->c时,因为不满足代码10行的条件,所以直接跳到13行,并且满足条件,进入else if中,即case3。同理这样一直先去得到最终情况f。算法导论中是这样解释的:
The execution of BINOMIAL-HEAP-UNION. (a) Binomial heaps H1 and H2. (b) Binomial heap H is the output of BINOMIAL-HEAP-MERGE(H1, H2). Initially,x is the first root on the root list of H . Because both x and next-x have degree 0 and key[x] < key[next-x], case 3 applies. (c) After the link occurs, x is the first of three roots with the same degree, so case 2 applies. (d) After all the pointers move down one position in the root list, case 4 applies, since x is the first of two roots of equal degree. (e) After the link occurs, case 3 applies. (f) After another link, case 1 applies, because x has degree 3 and next-x has degree 4. This iteration of thewhile loop is the last, because after the pointers move down one position in the root list, next-x = NIL.
3.4 插入一个节点
假设插入节点x到二项堆H中,x的值为key[x]。我们直接来分析其代码:
BINOMIAL-HEAP-INSERT(H, x)1 H′ ← MAKE-BINOMIAL-HEAP()2 p[x] ← NIL3 child[x] ← NIL4 sibling[x] ← NIL5 degree[x] ← 06 head[H′] ← x7 H ← BINOMIAL-HEAP-UNION(H, H′)
其实插入节点的操作用到了两个我们之前介绍的操作,一个是创建二项堆,另一个就是合并两个二项堆。我们插入一个新的节点,就是先创建一个新的二项堆,其中只含有x节点,然后将新创建的二项堆与要插入的二项堆合并。
3.5 提取出最小值的节点
即从二项堆中提取出最小值的节点,返回一个指向该节点的指针
BINOMIAL-HEAP-EXTRACT-MIN(H)1 find the root x with the minimum key in the root list of H, and remove x from the root list of H2 H′ ← MAKE-BINOMIAL-HEAP()3 reverse the order of the linked list of x's children, and set head[H′] to point to the head of the resulting list4 H ← BINOMIAL-HEAP-UNION(H, H′)5 return x
上面伪代码的操作流程如下图:

简单解释下代码的运行过程:(a)要插入的二项堆H;(b)利用2.3中的方法找到最小值节点,并从H中删除;(c)新建一个二项堆H',将最小值节点x的孩子颠倒顺序并存入到二项堆H'中;(d)然后合并H和H'就得到删除最小节点后的二项堆。
3.6 减少某个节点的值
即减少某个节点x的值至一个新的值k。如果k比x本身的值还大,则返回错误信息。代码如下:
BINOMIAL-HEAP-DECREASE-KEY(H, x, k) 1 if k > key[x] 2 then error "new key is greater than current key" 3 key[x] ← k 4 y ← x 5 z ← p[y] 6 while z ≠ NIL and key[y] < key[z] 7 do exchange key[y] ↔ key[z] 8 ▸ If y and z have satellite fields, exchange them, too. 9 y ← z10 z ← p[y]
因为减少了x节点的值后,他可能违反了二项堆的性质1即子节点的值要大于父节点,所以要对其进行修复,4-10行就是在修复。图中表示的就是将x节点的值减到7,然后对他进行调整。时间复杂度为O(lgn),因为二项堆的高度最多为o(lgn)

3.7 删除元素
删除元素主要用到上面的两个操作,一个是3.5去除堆中最小值,第二个是3.6将某一节点减少之多大。时间复杂度为O(lgn).下面是为代码
BINOMIAL-HEAP-DELETE(H, x)1 BINOMIAL-HEAP-DECREASE-KEY(H, x, -∞)2 BINOMIAL-HEAP-EXTRACT-MIN(H)
- 《Thinking In Algorithm》15.堆结构之二项堆
- 《Thinking In Algorithm》11.堆结构之二叉堆
- 《Thinking in Algorithm》16.堆结构之斐波那契堆
- 《Thinking In Algorithm》03.数据结构之数组
- 《Thinking In Algorithm》 系列前言及目录
- 《Thinking In Algorithm》08.B-Tree
- 《Thinking In Algorithm》09.彻底理解递归
- 《Thinking In Algorithm》09.彻底理解递归
- 《Thinking In Algorithm》09.彻底理解递归
- 《Thinking In Algorithm》02.Stacks,Queues,Linked Lists
- 《Thinking In Algorithm》05.Hash Tables(哈希表)
- 《Thinking In Algorithm》07.Red-Black Trees(红黑树)
- 《Thinking in Algorithm》12.详解十一种排序算法
- 《Thinking in Algorithm》12.详解十一种排序算法
- 《Thinking in Algorithm》12.详解十一种排序算法
- 《Thinking in Algorithm》12.详解十一种排序算法
- 《Thinking in Algorithm》12.详解十一种排序算法
- 《Thinking in Algorithm》12.详解十一种排序算法
- 什么是IAP
- 通过webservice 将图片发送到Android客户端
- 微软2014在线笔试 第三题
- VxWoks学习记录(2014年4月17日)
- CentOS6.4之图解SSH无验证双向登陆配置
- 《Thinking In Algorithm》15.堆结构之二项堆
- 九度OJ题目1554:区间问题
- 生活的 圣何塞
- User-agent 类型汇总
- 符号表支持优先队列的最大值和最小值删除
- JAX-WS生成服务端与客户端的两条命令
- Keep Walking in MongoDB 3
- 爱情
- SkinH_Attach 未定义


