决策树的剪枝和CART算法
来源:互联网 发布:js省市区三级联动插件 编辑:程序博客网 时间:2024/05/01 12:56
一、简介
分类与回归树CART (Ciassification and Regression Trees)是分类数据挖掘算法的一种。CART是在给定输入随机变量X条件下输出随机变量Y的条件分布概率。该模型使用了二叉树将预测空间递归划分为若干子集,Y在这些子集的分布是连续均匀的。树中的叶节点对应着划分的不同区域,划分是由与每个内部节点相关的分支规则(Spitting Rules)确定的。通过从树根到叶节点移动,一个预测样本被赋予一个惟一的叶节点,Y在该节点上的条件分布也被确定。CART模型最旱由Breman等人提出并己在统计学领域普遍应用。在分类树下面有两个关键的思想。第一个是关于递归地划分自变量空间的想法;第二个想法是用验证数据进行剪枝。
二、分类树与回归树的区别
在数据挖掘中,决策树主要有两种类型:
分类树的输出是样本的类标。 针对Y是离散变量。
回归树的输出是一个实数 (例如房子的价格,病人呆在医院的时间等)。针对Y是连续变量。
回归树的输出是一个实数 (例如房子的价格,病人呆在医院的时间等)。针对Y是连续变量。
CART与ID3区别:
CART中用于选择变量的不纯性度量是Gini指数;
如果目标变量是标称的,并且是具有两个以上的类别,则CART可能考虑将目标类别合并成两个超类别(双化);
如果目标变量是连续的,则CART算法找出一组基于树的回归方程来预测目标变量。
如果目标变量是标称的,并且是具有两个以上的类别,则CART可能考虑将目标类别合并成两个超类别(双化);
如果目标变量是连续的,则CART算法找出一组基于树的回归方程来预测目标变量。
三、构建分类决策树
分类树用基尼指数选择最优特征,同时决定该特征值的最优二值切分点
基尼指数定义
分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼指数定义为
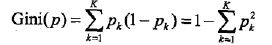
对于二类分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为
对于二类分类问题,若样本点属于第1个类的概率是p,则概率分布的基尼指数为
Gini(p)=2p(1-p)
对于给定的样本集合D,其基尼指数为
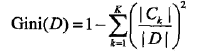 这里,Ck是D中属于第k类的样本子集,k是类的个数。
这里,Ck是D中属于第k类的样本子集,k是类的个数。
D根据特征A是否取某一个可能值a而分为D1和D2两部分:

则在特征A的条件下,D的基尼指数是:

根据表给出的数据,用CART算法生成决策树

解:首先计算各特征的基尼指数,选择最优特征以及最优切分点。分别以A1,A2,A3,A4 表示年龄、有工作、
有自己的房子和信贷情况4个特征,并以1,2,3表示年龄的值为青年、中年和老年,以1,2表示有工作和有
自己的房子的值是和否,以1,2,3表示信贷情况的值为非常好、好和一般。
求特征
基尼指数在选取最优切分点的过程中,会分为当前特征标签和其他特征标签两类。所以
简单说明下,第一部分是青年标签里能否贷款的数据混沌度,第二部分是中年和老年加在一起的数据混沌度。同理:
由于
求特征
由于
求特征
在
0 0
- 决策树的剪枝和CART算法
- 决策树-Cart生成和剪枝算法
- 决策树之剪枝原理与CART算法
- CART决策树剪枝
- 机器学习算法的Python实现 (3):CART决策树与剪枝处理
- 机器学习算法的Python实现 (3):CART决策树与剪枝处理
- 三个有名的决策树算法:CHAID、CART和C4.5
- 机器学习-决策树/CART剪枝
- 决策树和CART决策树
- 决策树的先剪枝和后剪枝
- CART 剪枝算法
- 决策树之CART算法
- 决策树之CART算法
- (决策树)CART算法
- 决策树2 -- CART算法
- 决策树之CART算法
- CART决策树算法总结
- 决策树之cart算法
- 蓝桥杯 算法训练之数字三角形(dp)
- 27岁程序员职业生涯的“中年危机”
- POJ 3316 Snakes on a Plane 可能会
- CodeBlocks恢复最初设置,解决无编译器问题
- vs2012 opencv c++
- 决策树的剪枝和CART算法
- HBase学习笔记——入门简介
- SAML
- Treap——模板
- 二叉搜索树的第k个节点
- lay lie lie
- 程序猿如何“智斗”产品经理
- 树莓派3一根网线直连电脑(针对树莓派不能上网有方法解决)
- git rebase 和 git fetch 区别


