二叉树怎样序列化才能重建
来源:互联网 发布:lcd1602只亮不显示数据 编辑:程序博客网 时间:2024/05/03 05:05
「序列化」(serialization),指的是把复杂的数据结构转化为线性结构,以方便存储的过程。序列化得到的线性结构必须能重建出原有的结构,才有意义。
对于二叉树,常用的序列化方法是在树上进行某种遍历(如先序、中序、后序、层序),用一种或两种遍历结果作为序列化结果。但并不是随便选一种或两种遍历结果,都能把二叉树重建出来。本文将给出二叉树序列化能够重建的一个充分条件,并且在实用中,这个条件也可以认为是必要的。
一、几种常见的序列化方法
1.1 仅使用一种遍历的序列化方法
这是最常见的序列化方法。可以采用的遍历顺序包括先序、后序、层序。在遍历时,要把空指针也包含在遍历的结果中。例如,对下图的二叉树,进行先序、后序、层序遍历的结果分别为 12##3#4##、##2###431、123###4##(# 表示空指针)。
从这几种遍历的结果重建二叉树的过程是显然的,程序从略。其时间复杂度为 O(n),n 为树中的结点数。
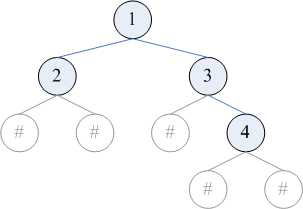 从这几种遍历的结果重建二叉树的过程是显然的,程序从略。其时间复杂度为 O(n),n 为树中的结点数。
从这几种遍历的结果重建二叉树的过程是显然的,程序从略。其时间复杂度为 O(n),n 为树中的结点数。而仅根据(带空指针的)中序遍历,是不能重建二叉树的。比如,上面这棵树的中序遍历为 #2#1#3#4#。事实上可以证明,任何一棵二叉树的中序遍历结果,都会是空指针与树中结点交替出现的形式,所以空指针没有提供任何额外的信息。
1.2 使用两种遍历的序列化方法
这是学习二叉树时的常见思考题:如何根据两种遍历结果(不含空指针)重建二叉树。并不是任意两种遍历结果都能重建二叉树,我们先考虑一种可行的情况:已知先序和中序遍历。
以上图中的二叉树为例,它的先序遍历为 124536,中序遍历为 425136。先序遍历的第一个元素 1 一定是根,以这个元素为分界点把中序遍历结果分成两半,可以得到 425 和 36,这就是左子树和右子树各自的中序遍历。在先序遍历中取同样长度的两个子序列,得到 245 和 36,这就是两个子树的先序遍历了。由此可以递归地重建出整棵二叉树。Python 代码如下(Node 类的定义从略):
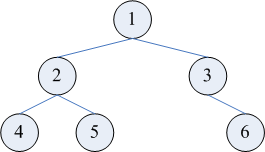 以上图中的二叉树为例,它的先序遍历为 124536,中序遍历为 425136。先序遍历的第一个元素 1 一定是根,以这个元素为分界点把中序遍历结果分成两半,可以得到 425 和 36,这就是左子树和右子树各自的中序遍历。在先序遍历中取同样长度的两个子序列,得到 245 和 36,这就是两个子树的先序遍历了。由此可以递归地重建出整棵二叉树。Python 代码如下(Node 类的定义从略):
以上图中的二叉树为例,它的先序遍历为 124536,中序遍历为 425136。先序遍历的第一个元素 1 一定是根,以这个元素为分界点把中序遍历结果分成两半,可以得到 425 和 36,这就是左子树和右子树各自的中序遍历。在先序遍历中取同样长度的两个子序列,得到 245 和 36,这就是两个子树的先序遍历了。由此可以递归地重建出整棵二叉树。Python 代码如下(Node 类的定义从略):def reconstruct(preorder, inorder): if len(preorder) == 0: return None # 递归终止条件 root = Node(preorder[0]) # 以先序遍历的第一个元素为根 p = inorder.index(preorder[0]) # 在中序遍历中找到根的位置 root.left = reconstruct(preorder[1:p+1], inorder[:p]) # 截取左子树的先序和中序遍历,重建左子树 root.right = reconstruct(preorder[p+1:], inorder[p+1:]) # 截取右子树的先序和中序遍历,重建右子树 return root # 返回重建结果另外,上面这个程序使用了 index 函数,它的时间复杂度不是 O(1) 的。在某些编程语言中,截取一个序列的子序列需要把子序列复制一份,这也不是 O(1) 的。这些因素导致整个程序的时间复杂度高于 O(n),在最坏情况下可以达到 O(n^2)。一个解决办法是把两个已知序列包装成输入流(如 Python 中的 collections.deque),在创建根结点时,暂时先不去找它在中序遍历中的位置,而是递归下去,直到在中序遍历中遇到根结点时再返回来。Python 代码如下,其中 stop 参数表示在中序遍历中遇到什么元素就该返回了。
from collections import dequedef reconstruct(preorder, inorder, stop): if inorder[0] == stop: return None # 递归终止条件 root = Node(preorder.popleft()) # 创建根结点,并消耗掉先序遍历流中的根 root.left = reconstruct(preorder, inorder, root.value) # 重建左子树,直到在中序遍历流中遇到当前层的根 inorder.popleft() # 消耗掉中序遍历流中的根 root.right = reconstruct(preorder, inorder, stop) # 重建右子树,直到在中序遍历流中遇到上层的根 return root # 返回重建结果tree = reconstruct(deque(preorder + [None]), deque(inorder + [None]), None) # 把先序和中序遍历结果都包装成输入流,并在最后加入一个 None 作为终止条件这段程序理解起来稍微困难一些,不过它更能揭示「先序 + 中序」与「先序 + 空指针」两种序列化方式的相似之处。在这段程序中,中序遍历的作用是用做递归终止条件,即告诉程序哪些地方应当是空指针。也就是说,「中序遍历」与「空指针」提供的是相同的信息,只不过更间接一些。
现在来看其它使用两种遍历的序列化方法。「后序 + 中序」的情况跟「先序 + 中序」的情况是十分类似的,把上面两段程序稍加修改,都可以用于「后序 + 中序」的重建(具体要修改哪里留作练习)。但已知先序和后序遍历结果时,是不能重建二叉树的,例如下面两棵树的先序遍历都是 12,后序遍历都是 21。
同时也可以发现,上图中两棵树的层序遍历也都是 12。因此,依靠「层序 + 先序」或「层序 + 后序」两种遍历结果,也都不能重建二叉树。依靠「层序 + 中序」是可以重建的,具体方法将在下一小节最后说明。
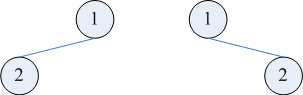 同时也可以发现,上图中两棵树的层序遍历也都是 12。因此,依靠「层序 + 先序」或「层序 + 后序」两种遍历结果,也都不能重建二叉树。依靠「层序 + 中序」是可以重建的,具体方法将在下一小节最后说明。
同时也可以发现,上图中两棵树的层序遍历也都是 12。因此,依靠「层序 + 先序」或「层序 + 后序」两种遍历结果,也都不能重建二叉树。依靠「层序 + 中序」是可以重建的,具体方法将在下一小节最后说明。1.3 二叉搜索树(BST)的序列化方法
二叉搜索树(binary search tree, BST)是这样一种二叉树:对任一结点,它的左子树中所有结点都小于(或等于)本身,而右子树中所有结点都大于(或等于)本身。BST 的定义不统一,有些定义不允许树中有重复元素,有些定义允许各个结点的单侧子树中有等于本身的元素,有些定义允许两侧都有等于本身的元素。本文采用最宽松的定义,但本小节仅讨论没有重复元素的情况,至于这个条件的放宽,留到第三大节中讨论。
如果已知一棵树是 BST,那么只需要知道先序、后序、层序遍历中的一者(不需要包含空指针)就足以重建了。这是因为,把这些遍历结果排个序,就是中序遍历,从而化归成了上一小节的情况。这说明,BST 的顺序与中序遍历提供的是同样的信息。当然,排序的时间复杂度是 O(n log n),高于重建的复杂度 O(n)。能不能绕过排序呢?也是可以的,只要我们能在重建过程中,根据「树是 BST」这个条件得知哪些地方是空指针。
例如,在已知先序遍历结果时,可以用如下方法重建 BST。inf 代表一个比所有元素都大的值。在上一小节里,我们用「中序遍历的开头就是上面某层的根结点(stop)」作为空指针的判断条件。现在没有中序遍历了,但我们可以改用「先序遍历的下一个结点大于等于 stop」作为空指针的判断条件。
from collections import dequeinf = float('inf')def reconstruct(preorder, stop): if preorder[0] >= stop: return None # 递归终止条件 root = Node(preorder.popleft()) # 创建根结点,并消耗掉先序遍历流中的根 root.left = reconstruct(preorder, root.value) # 重建左子树,直到先序遍历流中出现大于当前层根结点的值 root.right = reconstruct(preorder, stop) # 重建右子树,直到先序遍历流中出现大于上层根结点的值 return root # 返回重建结果tree = reconstruct(deque(preorder + [inf]), inf) # 把先序和中序遍历结果都包装成输入流,并在最后加入一个 inf 作为终止条件在已知层序遍历时,BST 的重建方法如下。在重建过程中,对于每个结点,记录下以它为根的子树中的元素的取值范围(用开区间表示)。结合结点本身的值,就可以知道它的两个子结点的取值范围。如果先序遍历中的下一个元素正好落在这些范围之内,那么这些子结点就存在,否则这些子结点为空。
from collections import dequeinf = float('inf')def reconstruct(level_order): level_order = deque(level_order) # 把层序遍历包装成输入流 root = Node(level_order.popleft()) # 创建根结点 queue = deque([(root, -inf, inf)]) # 重建过程中使用的队列 # 其中的元素为三元组,第一个元素为结点,后两个元素表示子树中元素的取值范围 while len(level_order) > 0: # 层序遍历结果还没读完 node, min, max = queue.popleft() # 取出队首结点及相应的取值范围 if min < level_order[0].value < node.value: node.left = Node(level_order.popleft()) queue.append((node.left, min, node.value)) # 若层序遍历的下一元素落在左子树的取值范围内,则创建左子树 if node.value < level_order[0].value < max: node.right = Node(level_order.popleft()) queue.append((node.right, node.value, max)) # 若层序遍历的下一元素落在右子树的取值范围内,则创建右子树 return root # 返回重建结果下面解答上一小节的遗留问题:对于一棵普通二叉树(非 BST),在已知层序和中序遍历时,如何重建。事实上,中序遍历可以认为是指定了树中元素的顺序关系,于是便化归为刚刚解决的「已知层序遍历重建 BST」的问题。在实现上,可以用一个哈希表将树中的元素映射为它们在中序遍历中的次序,然后就可以套用上一段程序解决。
二、二叉树序列化能够重建的充分条件
上文讨论的所有情况,可以总结成如下的「定理」:
一棵二叉树能够被重建,如果满足下面三个条件之一:
a1. 已知先序遍历;或
a2. 已知后序遍历;或
a3. 已知层序遍历;
且满足下面三个条件之一:
b1. 前面已知的那种遍历包含了空指针;或
b2. 已知中序遍历,且树中不含重复元素;或
b3. 树是二叉搜索树,且不含重复元素。
这是本文的主要结论。它指出,中序遍历提供的信息,与空指针和 BST 是相同的,而与先序、后序、层序遍历提供的信息互补。同时,这个充分条件也几乎是必要的,因为如果仅满足 a 组的两个条件,或者仅满足 b 组的两个条件,都不能重建二叉树。
三、「不含重复元素」的必要性探讨
上一节给出的条件是个充分条件;导致它不是必要条件的原因,就在于 b2、b3 两个条件中的「不含重复元素」。在这一节中,我们就来探讨一下这个条件可以放宽到什么程度,还能保证重建出的树是唯一的。
先看 b3,即 BST 的情况。对于 BST,可以把「不含重复元素」,放宽到「允许一侧子树中有与根相等的元素」。无论是根据先序还是层序遍历重建 BST,关键步骤都是确定遍历结果中的下一个元素应该长在树的什么位置,而这是根据每个可能长出结点的位置(下图中灰色的椭圆)允许的取值范围确定的。在不允许重复元素的情况下,各个「生长点」的取值范围都是开区间;在允许一侧子树中有与根相等的元素的情况下,各个「生长点」的取值范围是半开半闭区间 —— 在这两种情况下,各区间都没有重叠,所以都可以唯一确定下一个元素应该长在哪里。但如果放宽到「两侧子树都允许有与根相等的元素」,区间就变成了闭区间,端点出现重叠,就不能保证重建出的树唯一了。例如,如果先序或层序遍历的结果是 533,则不能确定后一个 3 应该是前一个 3 的左孩子还是右孩子。
不过,即使在两侧子树都允许有与根相等的元素的情况下,重建出的树也有可能是唯一的。比如,如果先序遍历是 2132,那么后一个 2 只能作为 3 的左孩子,而不能作为 1 的右孩子(下图左);再如,如果层序遍历是 232,那么后一个 2 只能作为 3 的左孩子,而不能作为 前一个 2 的左孩子(下图右)。这是因为,按照先序或层序的限制,在安放后一个 2 时,有些「生长点」已经不可用了。但这种情况只能在算法执行过程中发现,无法事先判断,也就是说,很难给出在「两侧子树都允许有与根相等的元素」的前提下树能够唯一重建的充要条件。
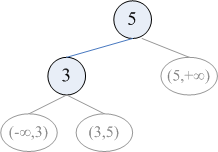 不过,即使在两侧子树都允许有与根相等的元素的情况下,重建出的树也有可能是唯一的。比如,如果先序遍历是 2132,那么后一个 2 只能作为 3 的左孩子,而不能作为 1 的右孩子(下图左);再如,如果层序遍历是 232,那么后一个 2 只能作为 3 的左孩子,而不能作为 前一个 2 的左孩子(下图右)。这是因为,按照先序或层序的限制,在安放后一个 2 时,有些「生长点」已经不可用了。但这种情况只能在算法执行过程中发现,无法事先判断,也就是说,
不过,即使在两侧子树都允许有与根相等的元素的情况下,重建出的树也有可能是唯一的。比如,如果先序遍历是 2132,那么后一个 2 只能作为 3 的左孩子,而不能作为 1 的右孩子(下图左);再如,如果层序遍历是 232,那么后一个 2 只能作为 3 的左孩子,而不能作为 前一个 2 的左孩子(下图右)。这是因为,按照先序或层序的限制,在安放后一个 2 时,有些「生长点」已经不可用了。但这种情况只能在算法执行过程中发现,无法事先判断,也就是说,再看 b2,即已知中序遍历的情况。我们发现,如果允许有重复元素,那么也无法在事先判断树是否唯一。例如,当先序遍历为 1213,中序遍历为 1231 时,重建出的树有两种可能:若认为中序遍历中的前一个 1 为根,则它有一棵右子树,其先序遍历为 213,中序遍历为 231(下图中);若认为中序遍历中的后一个 1 为根,则它有一棵左子树,其先序遍历为 213,中序遍历为 123(下图左)。但在先序遍历仍为 1213,把中序遍历改为 1321 时,重建出的树就是唯一的了(下图右):此时只能认为中序遍历中的后一个 1 为根。否则,我们将需要重建一棵先序遍历为 213、中序遍历为 321 的子树,而这样的树是不存在的。
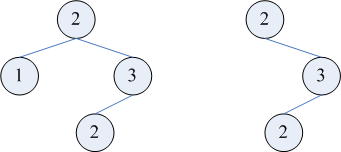 再看 b2,即已知中序遍历的情况。我们发现,如果允许有重复元素,那么也无法在事先判断树是否唯一。例如,当先序遍历为 1213,中序遍历为 1231 时,重建出的树有两种可能:若认为中序遍历中的前一个 1 为根,则它有一棵右子树,其先序遍历为 213,中序遍历为 231(下图中);若认为中序遍历中的后一个 1 为根,则它有一棵左子树,其先序遍历为 213,中序遍历为 123(下图左)。但在先序遍历仍为 1213,把中序遍历改为 1321 时,重建出的树就是唯一的了(下图右):此时只能认为中序遍历中的后一个 1 为根。否则,我们将需要重建一棵先序遍历为 213、中序遍历为 321 的子树,而这样的树是不存在的。
再看 b2,即已知中序遍历的情况。我们发现,如果允许有重复元素,那么也无法在事先判断树是否唯一。例如,当先序遍历为 1213,中序遍历为 1231 时,重建出的树有两种可能:若认为中序遍历中的前一个 1 为根,则它有一棵右子树,其先序遍历为 213,中序遍历为 231(下图中);若认为中序遍历中的后一个 1 为根,则它有一棵左子树,其先序遍历为 213,中序遍历为 123(下图左)。但在先序遍历仍为 1213,把中序遍历改为 1321 时,重建出的树就是唯一的了(下图右):此时只能认为中序遍历中的后一个 1 为根。否则,我们将需要重建一棵先序遍历为 213、中序遍历为 321 的子树,而这样的树是不存在的。「先序遍历为 213、中序遍历为 321 的树不存在」—— 这个事实其实颇有深意。它告诉我们,并不是把先序遍历随便排列一下作为中序遍历,都存在对应的树。事实上,3 个元素的全排列有 3! = 6 种,而 3 个结点组成的二叉树只有 Catalan(3) = 5 种,差的那一种恰好就是本段的例子。
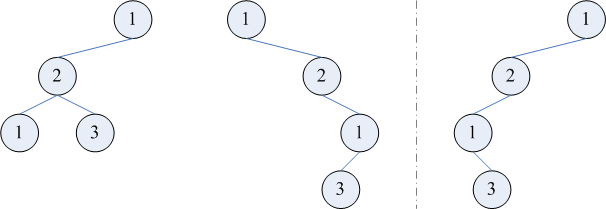 「先序遍历为 213、中序遍历为 321 的树不存在」—— 这个事实其实颇有深意。它告诉我们,并不是把先序遍历随便排列一下作为中序遍历,都存在对应的树。事实上,3 个元素的全排列有 3! = 6 种,而 3 个结点组成的二叉树只有 Catalan(3) = 5 种,差的那一种恰好就是本段的例子。
「先序遍历为 213、中序遍历为 321 的树不存在」—— 这个事实其实颇有深意。它告诉我们,并不是把先序遍历随便排列一下作为中序遍历,都存在对应的树。事实上,3 个元素的全排列有 3! = 6 种,而 3 个结点组成的二叉树只有 Catalan(3) = 5 种,差的那一种恰好就是本段的例子。如果已知的是层序和中序遍历,同样无法事先判断树是否唯一。例如,固定中序遍历为 121,若层序遍历也是 121,则树有下图左、中两种可能;但若层序遍历是 211,则树就只有下图右一种可能了。于是,与 BST 的情况类似,若在已知中序遍历的情况下允许树中有重复元素,则很难给出树能够唯一的充要条件。
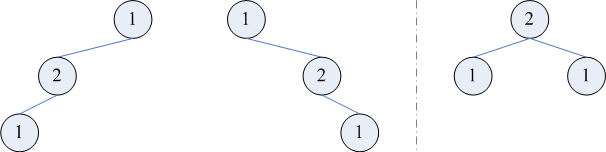
作为总结,第二节给出的充分条件中,b2、b3 两条中的「不含重复元素」,基本可以认为是必要的。除了对于 BST 可以放宽为「允许一侧子树有与根相等的元素」以外,其它情形很难放宽。
- 二叉树怎样序列化才能重建
- 根据前序中序序列重建二叉树
- 面试题-前序中序序列重建二叉树
- 根据二叉树的前序中序遍历序列重建二叉树
- 【二叉树】已知二叉树前序序列和中序序列,重建唯一二叉树
- 根据前序和中序序列重建二叉树
- 根据前序和中序列 重建二叉树
- 每天一个算法之根据前序中序序列重建二叉树
- 前/中序遍历序列重建二叉树
- 中/后序遍历序列重建二叉树
- 重建二叉树(前序,中序序列建树)
- 给出前序与中序 序列 重建二叉树
- 前序和中序序列重建二叉树
- 3.9重建二叉树
- 重建二叉树
- 二叉树重建
- 二叉树重建
- 二叉树的重建
- unity wav 格式音频转换为二进制文件
- 开发实用---修改Eclipse快捷注释的模板
- JSONCPP操作帮助
- 原始类型.Class 及 Class.forName(String class) 与 类名.class 的区别
- Linux下忘记MySQL的root密码的解决方法
- 二叉树怎样序列化才能重建
- JVM 学习笔记(三) 垃圾收集器与内存分配策略
- IAR编辑器字体配置
- A
- 扛得住mysql 性能优化
- 大话设计模式读书笔记(十四) 适配器模式
- Developing DataBase Applications Using MySQL Connector/C++ 中文文本
- PreparedStatement中的execute、executeQuery和executeUpdate之间的区别
- Java俄罗斯轮盘死亡游戏


